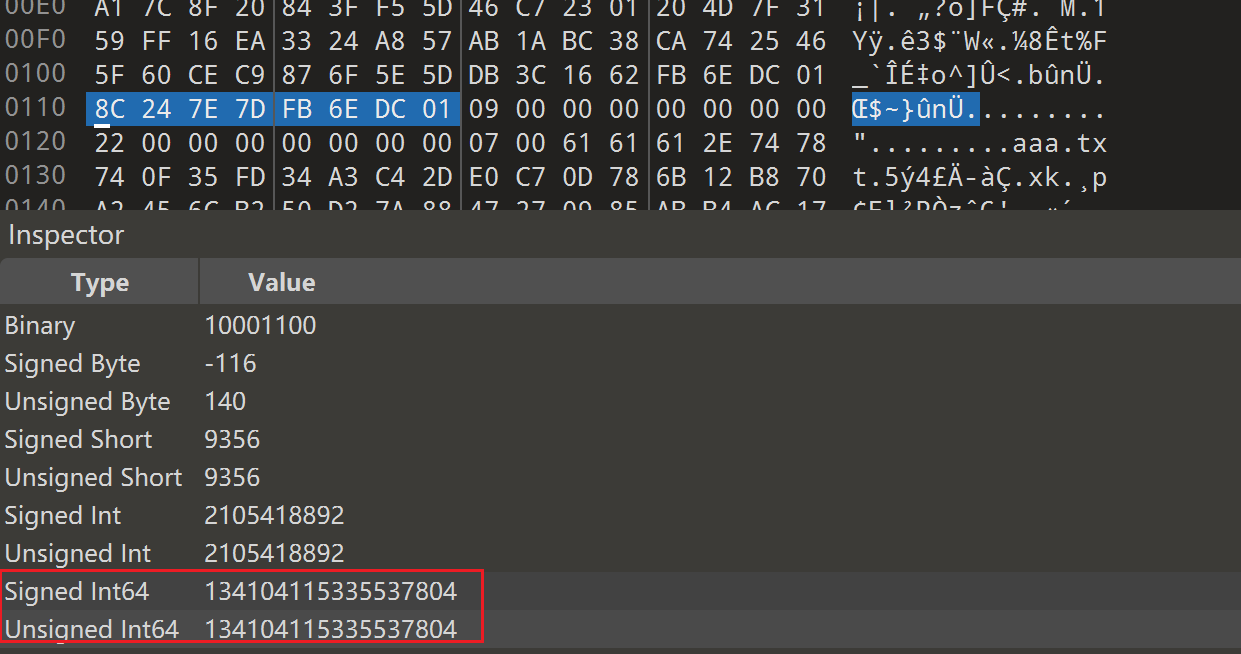
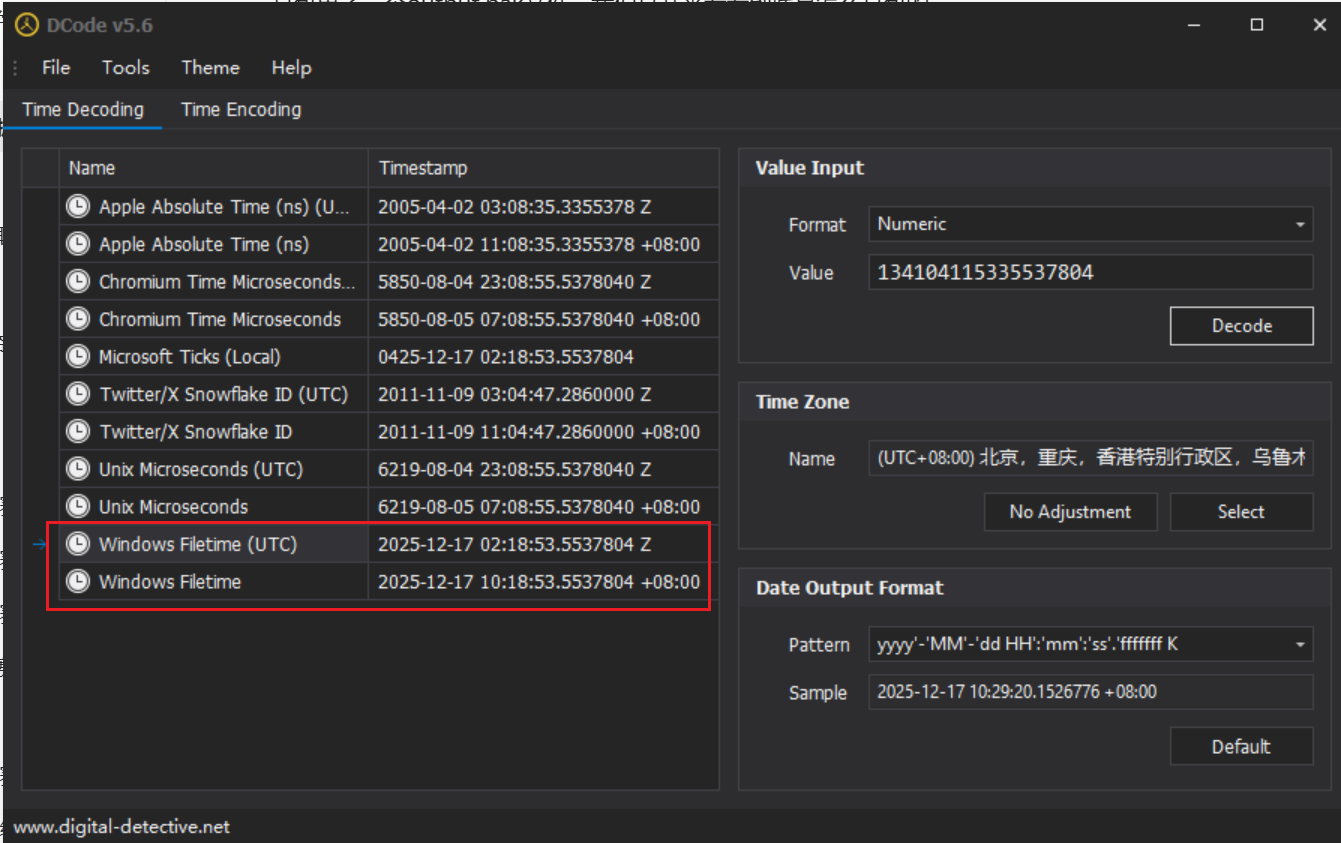
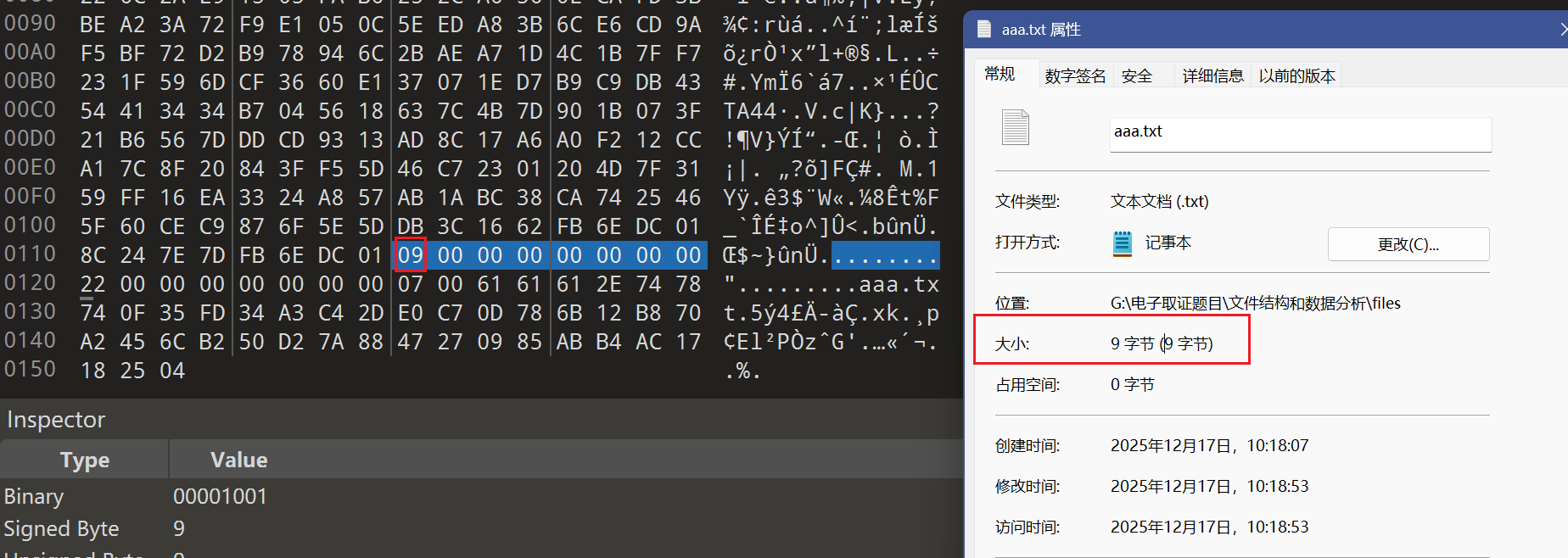
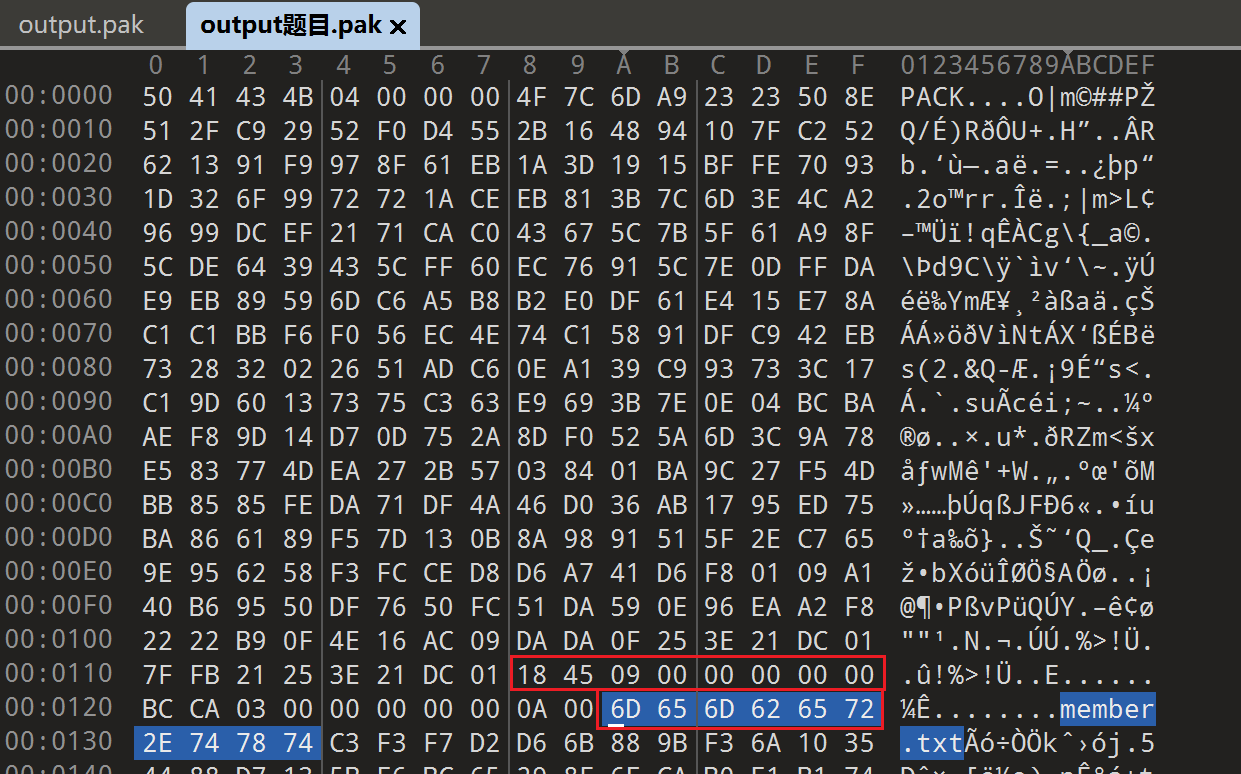
import argparse import gzip import struct from pathlib import Path
def rc4_xor(key: bytes, data: bytes) -> bytes: """RC4 XORKeyStream (encrypt/decrypt same)""" if not (1 <= len(key) <= 256): raise ValueError(f"RC4 key length must be 1..256, got {len(key)}")
# KSA S = list(range(256)) j = 0 for i in range(256): j = (j + S[i] + key[i % len(key)]) & 0xFF S[i], S[j] = S[j], S[i]
# PRGA i = 0 j = 0 out = bytearray(len(data)) for n, b in enumerate(data): i = (i + 1) & 0xFF j = (j + S[i]) & 0xFF S[i], S[j] = S[j], S[i] k = S[(S[i] + S[j]) & 0xFF] out[n] = b ^ k return bytes(out)
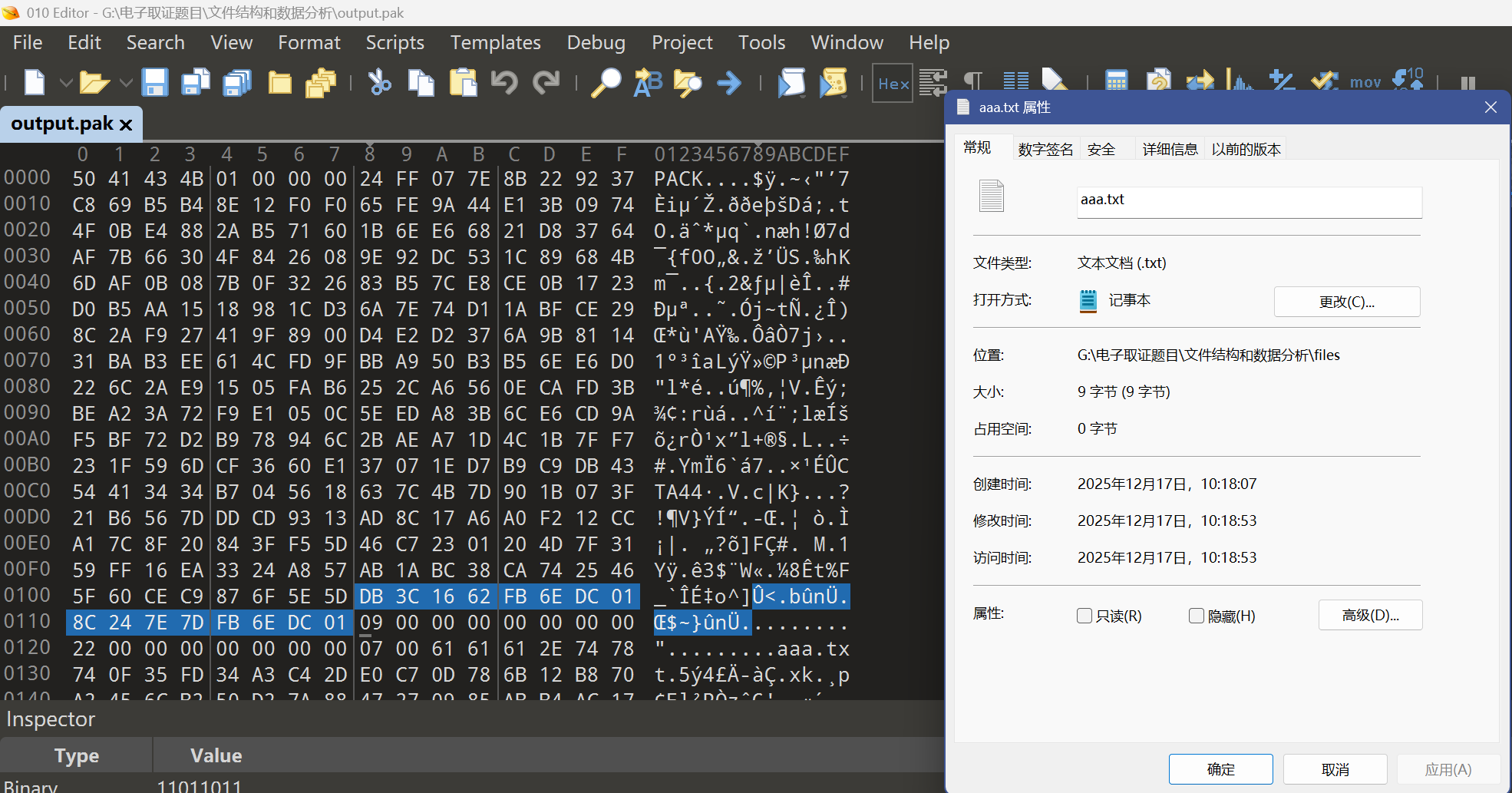
def safe_filename(name: str) -> str: # 防目录穿越,确保只落到输出目录下 name = name.replace("\\", "/").split("/")[-1] if name in ("", ".", ".."): raise ValueError("Bad filename in pak") return name
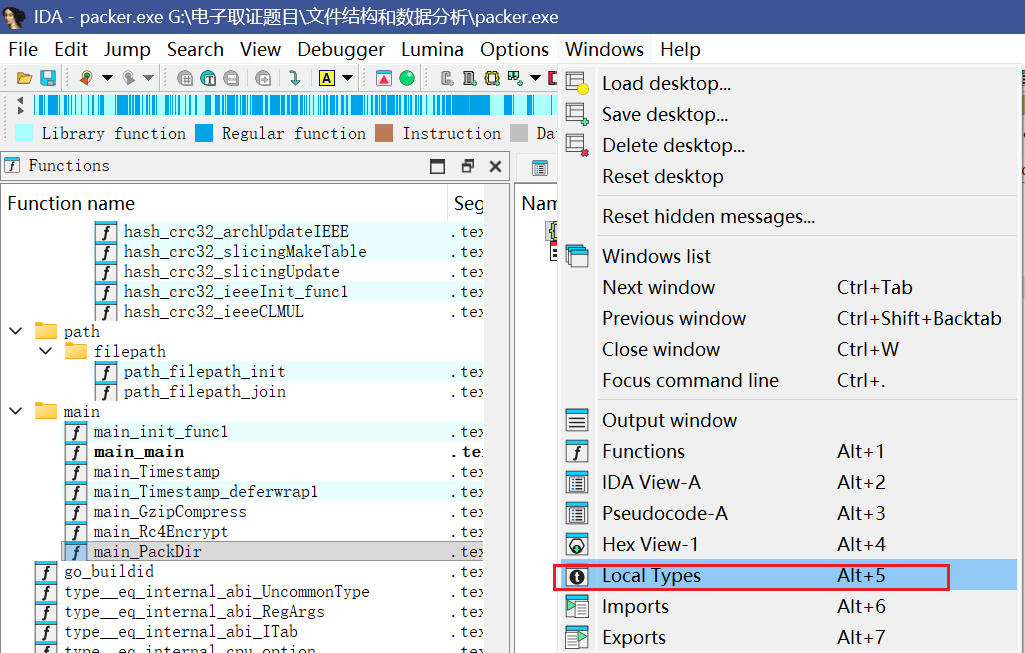
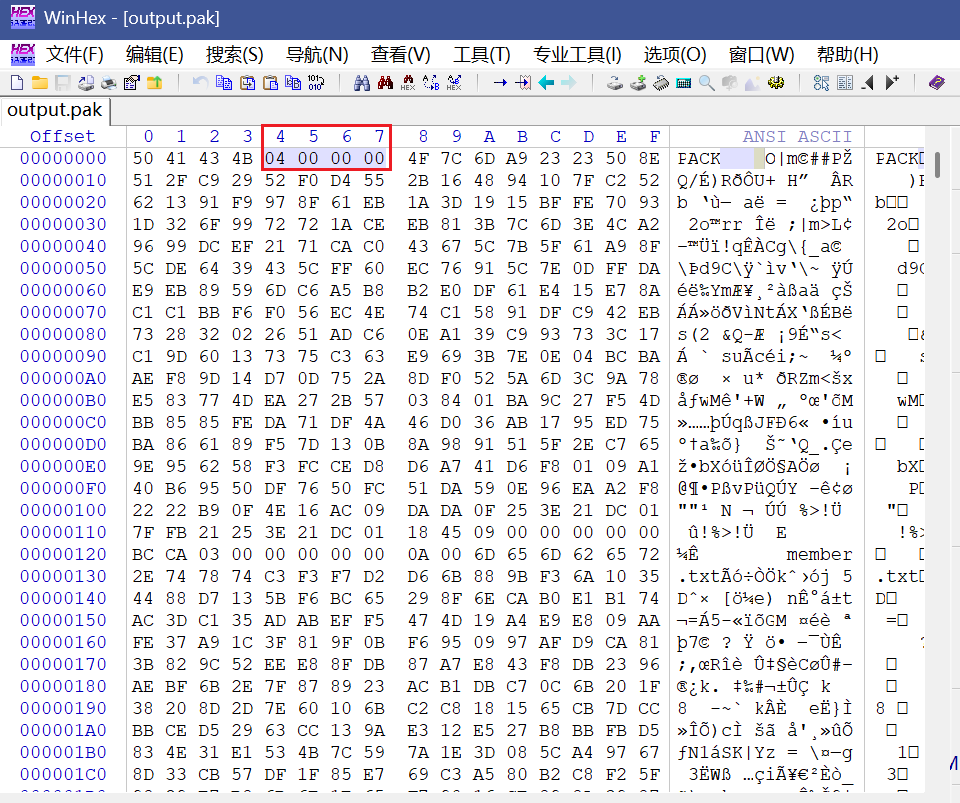
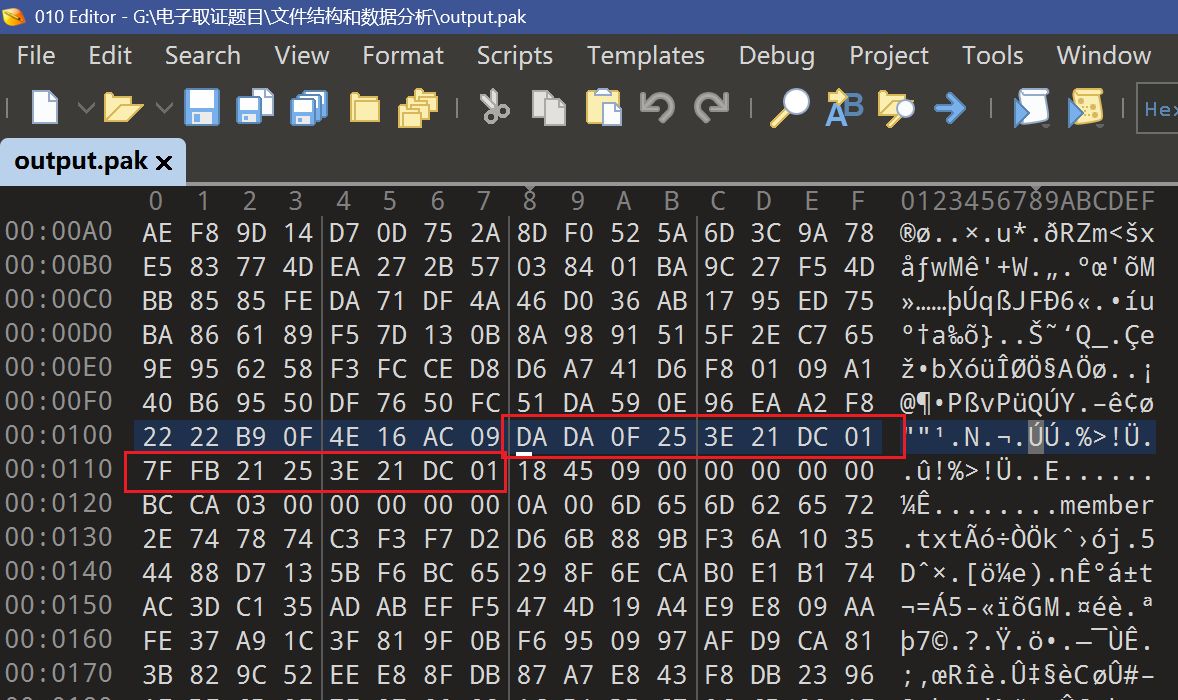
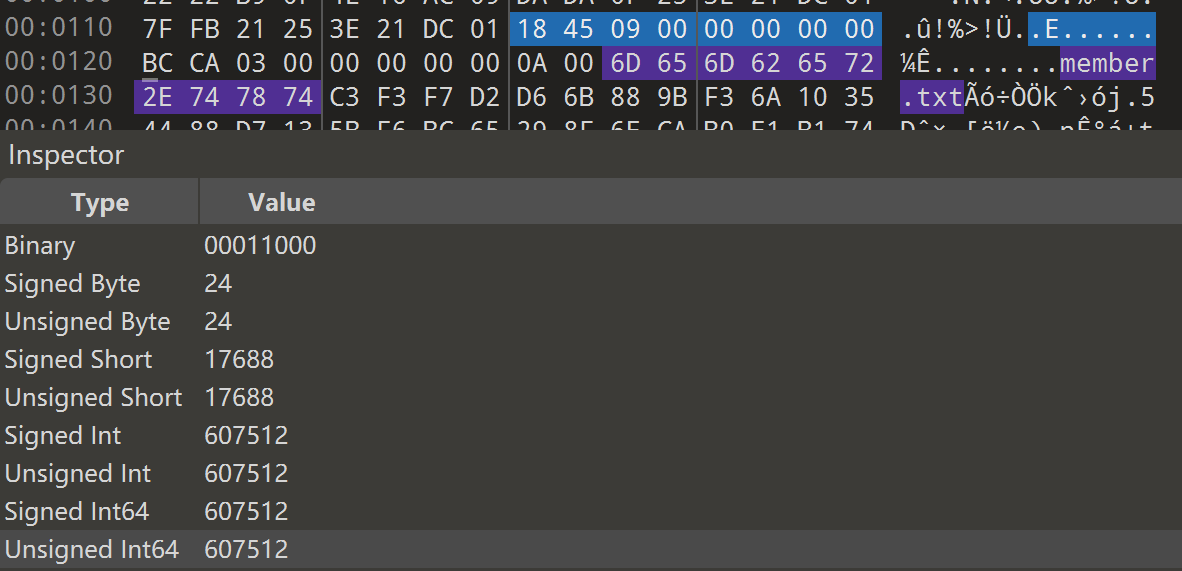
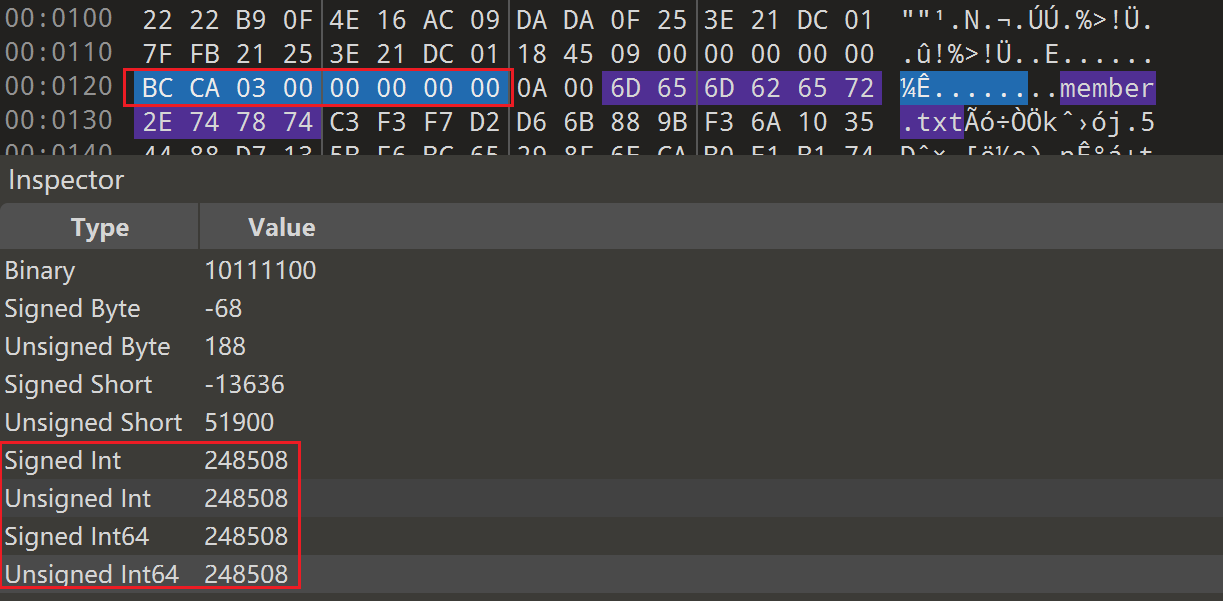
def unpack_pak(pak_path: Path, out_dir: Path) -> None: blob = pak_path.read_bytes() if len(blob) < 8 + 256: raise ValueError("File too small")
if blob[:4] != b"PACK": raise ValueError("Bad magic (expect PACK)")
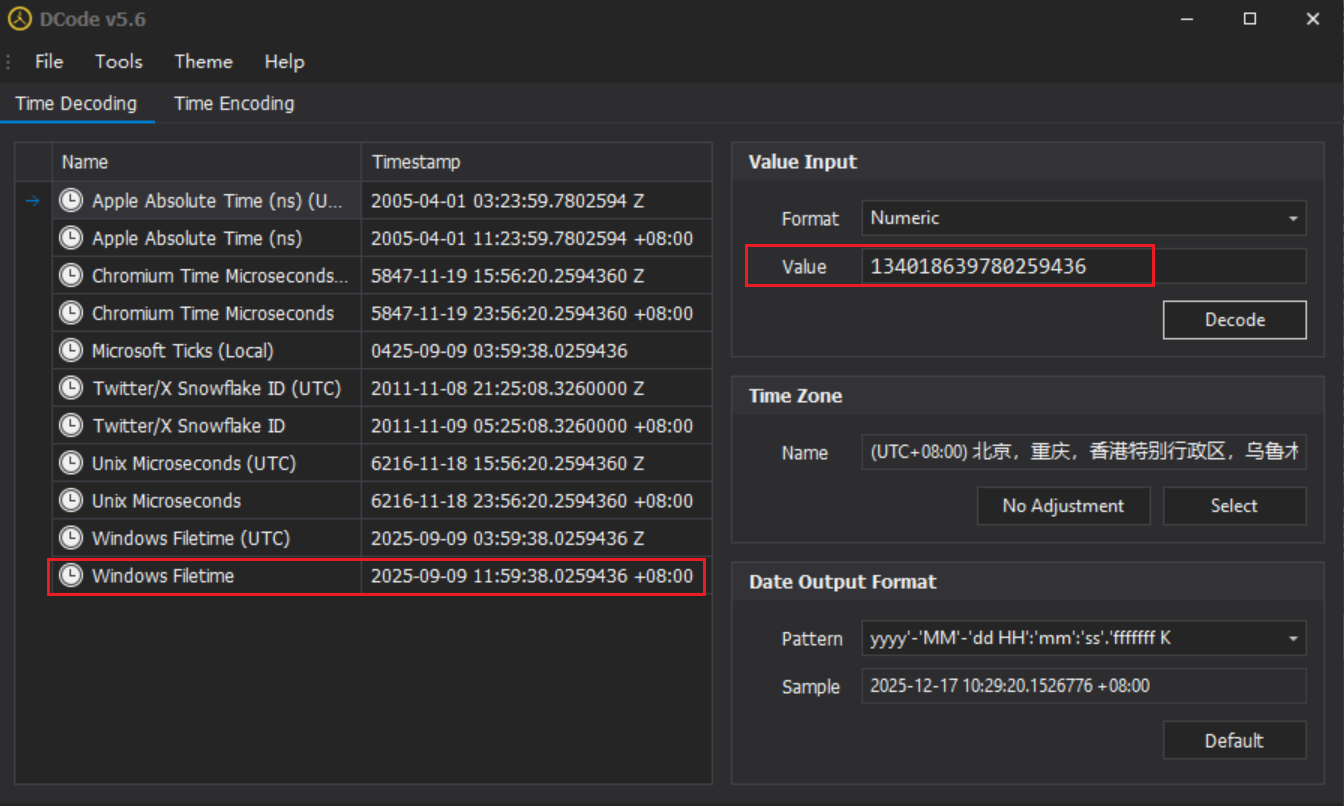
ver = struct.unpack_from("<I", blob, 4)[0] if ver != 4: raise ValueError(f"Unsupported version: {ver}")
def cents(s): s = str(s).strip() neg = s.startswith('-') if neg: s = s[1:] a,b = (s.split('.',1)+['0'])[:2] b = (b+'00')[:2] v = int(a)*100 + int(b) return -v if neg else v
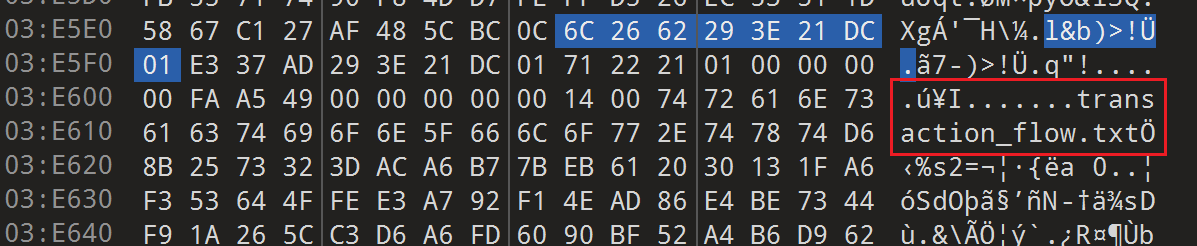
m = pd.read_csv('member.txt', sep='\t', header=None, dtype=str) f = pd.read_csv('transaction_flow.txt', sep='\t', header=None, dtype=str)
m_id = m[0].astype(int) bal = m[9].map(cents)
amt = f[3].map(cents) signed = amt.where(f[2].astype(int)==1, -amt) net = signed.groupby(f[1].astype(int)).sum()
bad = m_id[bal.ne(m_id.map(net).fillna(0).astype(int))].tolist() print(",".join(map(str, bad)))
memo = {} def depth(x): if x in memo: return memo[x] p = parent.get(x, 0) memo[x] = 1 if (p==0 or p==x or p not in parent) else depth(p)+1 return memo[x]
memo = {} def depth(x): if x in memo: return memo[x] p = parent.get(x, 0) memo[x] = 1 if (p==0 or p==x or p not in parent) else depth(p)+1 return memo[x]
print(sum(1 for x in mid if depth(x) == 100))
16.性别和身份证号码能对应上的会员数量?(答案格式:1)
看性别就是看身份证而已
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18
import pandas as pd import re
def id_gender(idc): if not isinstance(idc, str): return None idc = idc.strip() if re.fullmatch(r"\d{15}", idc): return 1 if int(idc[-1])%2 else 2 if re.fullmatch(r"\d{17}[\dXx]", idc): return 1 if int(idc[-2])%2 else 2 return None