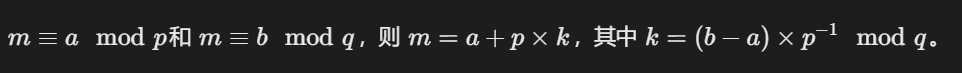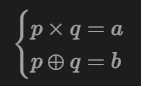Misc [Week1] 布豪有黑客(一)
不好!是流量包
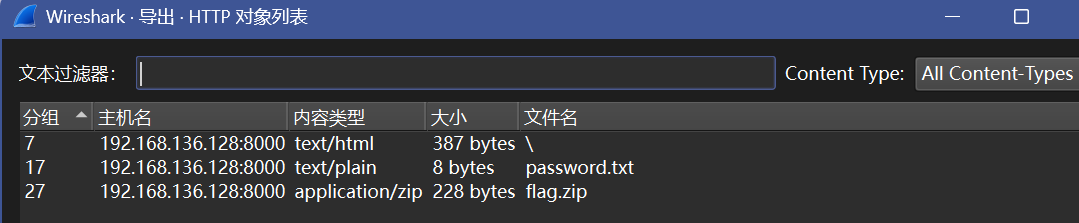
打开来就能看见个flag.zip
导出看看
额,就拿这个password.txt作为这个flag.zip的密码即可
鉴定为简单签到题
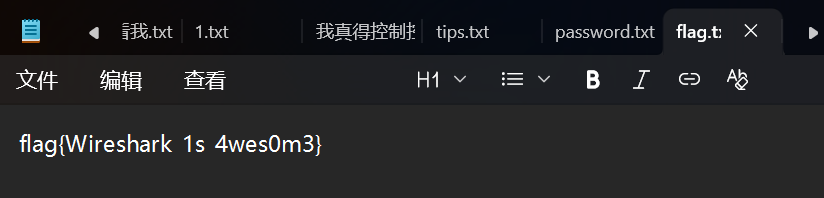
flag{Wireshark_1s_4wes0m3}
[Week1] 文化木的侦探委托(一)
太好啦!是最喜欢的图片隐写环节
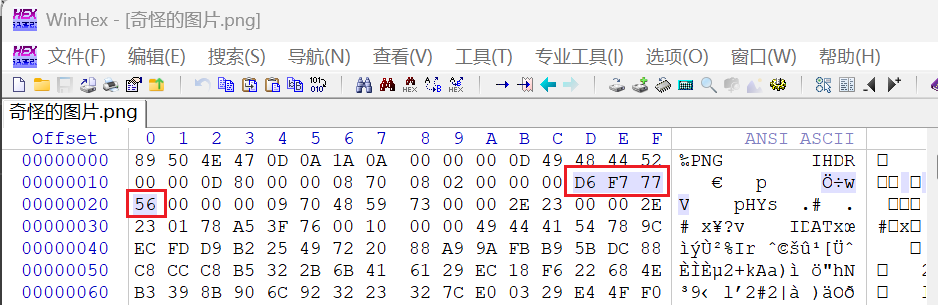
宽高有问题,我们修复一下
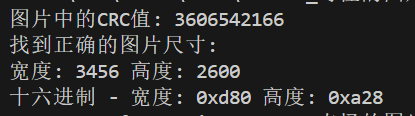
如何修复呢?这边有很多做法,首先是了解png格式的图片的每一个chunk其实都包含有循环冗余校验码,也就i是CRC32,根据这种算法我们可以爆破出png图片的宽高
这四个字节记录的便是CRC码
附一个爆破脚本
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 import binascii
得到了正确的宽高大小,我们寻找图片中存放这种宽高的地方
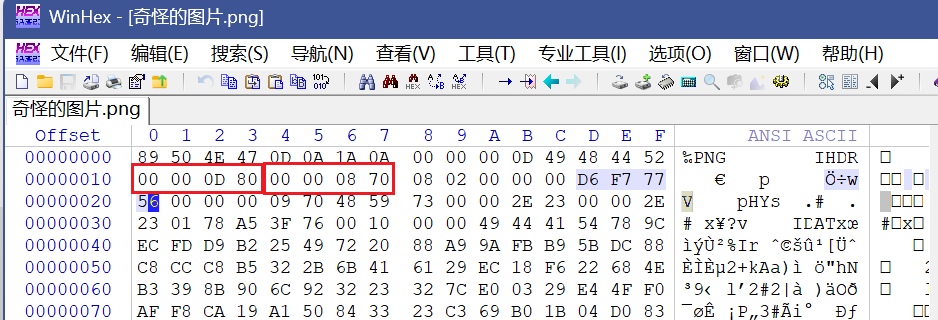
其实就在这边,前四个字节存放宽的大小,而后四个字节存放着高的大小
因此我们可以发现这与原图片的实高相差甚远,只要改成00000A28即可解决问题
改成这样子就好了
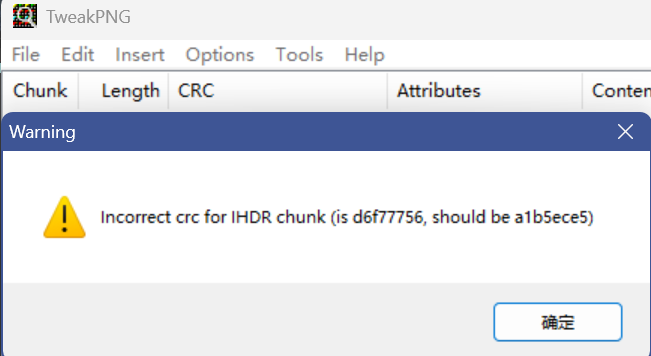
当然直接扔到Tweakpng或其他工具也可以直接出
TweakPNG会告诉你现在CRC是多少,应该是多少
随波逐流更是直接会跳出来,但是在直接一把梭之前,建议大家还是搞清楚原理最为重要
根据提示,红绿蓝,这很难不让人直接联想到所谓的RGB三原色
我们知道,图像的每一个RGB通道都是一个0-255的八位数字
然而,若我们去轻微改变每个颜色的最后一位,这意味着数字只浮动1的大小,这种改变是无法被人眼察觉出来的
这最后一位“最低有效位”就叫LSB(Least Significant Bit),我们可以依靠这一位来隐藏一些二进制,如果我们对多个像素进行利用,就获得了多比特位的存储空间,这种空间里也就可以存储需要隐写的数据了,而这一种隐写就是LSB隐写
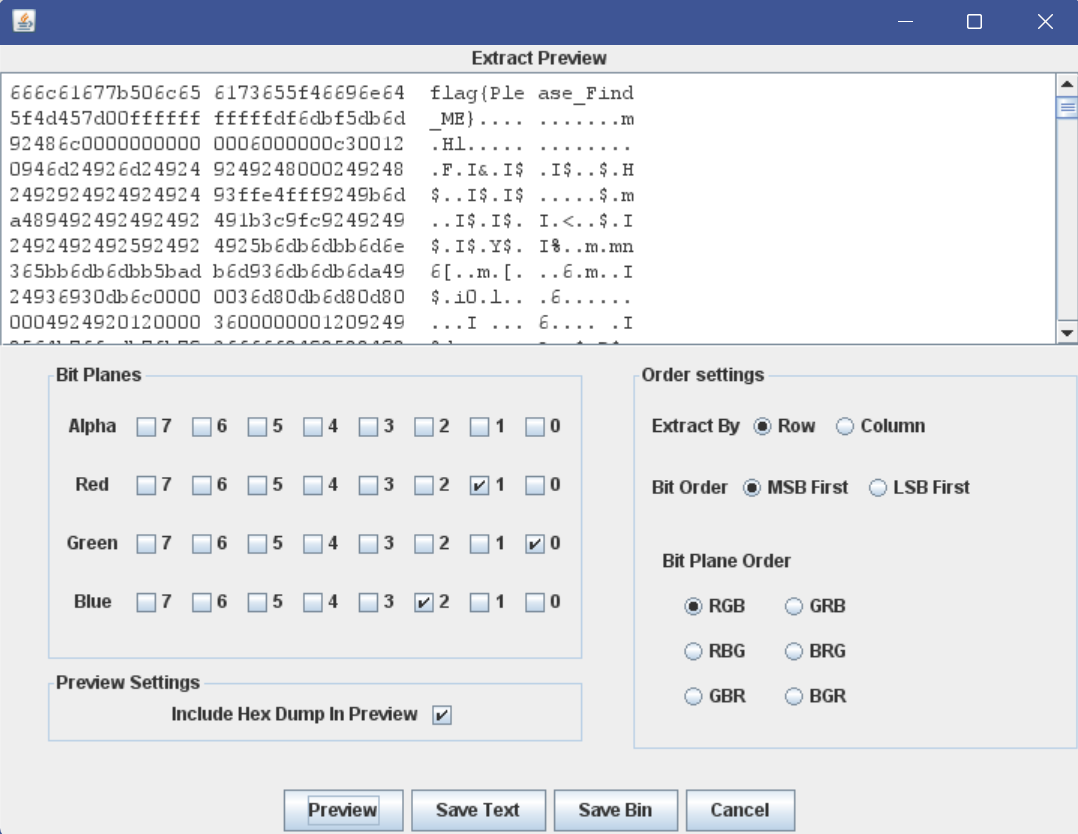
好这一题根据题目所述,就是红色通道的第一位,绿色通道的第0位和蓝色通道的第2位藏着内容,我们尝试提取这些内容
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 from PIL import Image
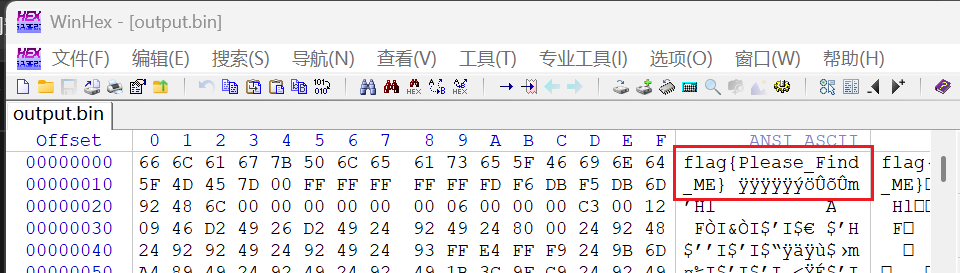
提取后观察十六进制即可发现flag
当然直接用stegslove工具也能得到
flag{Please_Find_ME}
[Week2] 文化木的侦探委托(二)
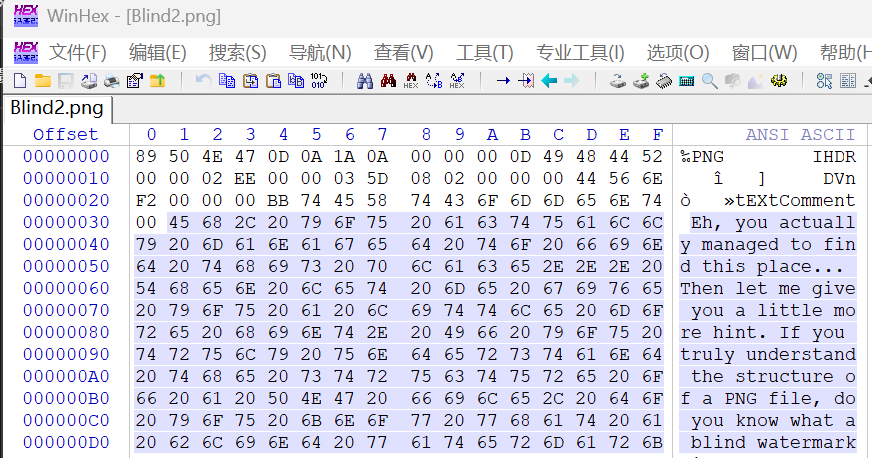
上来是这样子一张png图片,先查看十六进制
查看十六进制发现了这样子一句话:你知道盲水印是什么吗?
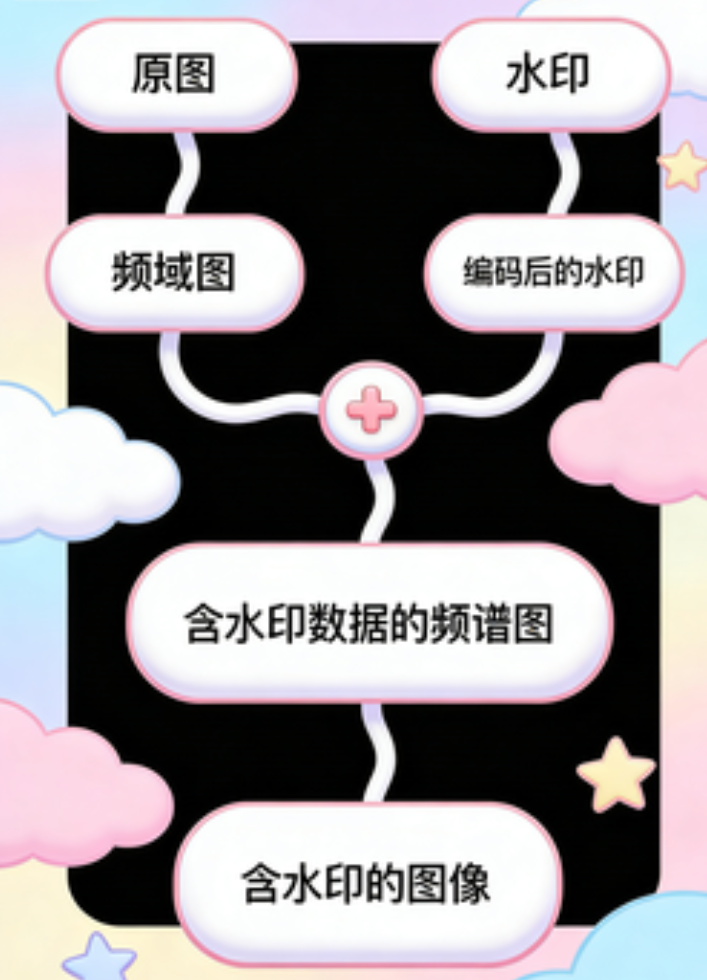
似乎是盲水印?但什么是盲水印呢?
盲水印是一种数字水印技术,将水印信息嵌入到图像、音频或视频等媒体文件中,而不会明显印象原始内容的质量。
这边是对载体图片进行了一种数学变化,最常用的是离散余弦变换嵌入(DCT)特性和小波变化特性等等,将经过编码的水印信息量化地嵌入到中频系数中去(避免在低频改动影响画面,也避免在高频丢失)
大概就是图片变成频谱图,然后水印变成编码后的水印,俩合成一张含水印数据的频谱图
核心是频域的叠加
1 2 3 4 5 6 7 # 傅里叶变换
“盲”的意思是提取水印的时候是不需要原始文件作为参考的
一般开源的实施方案是两个python库,blind-watermark和invisible-watermark
blind-watermark支持加密保护,提取不需要原图,抗攻击能力较强;而invisible-watermark则抗攻击性略差,且不支持加密。
https://github.com/guofei9987/blind_watermark
https://github.com/ShieldMnt/invisible-watermark
如果只有一张就是上边那样,但是这一题似乎不太一样
我们观察PNG格式
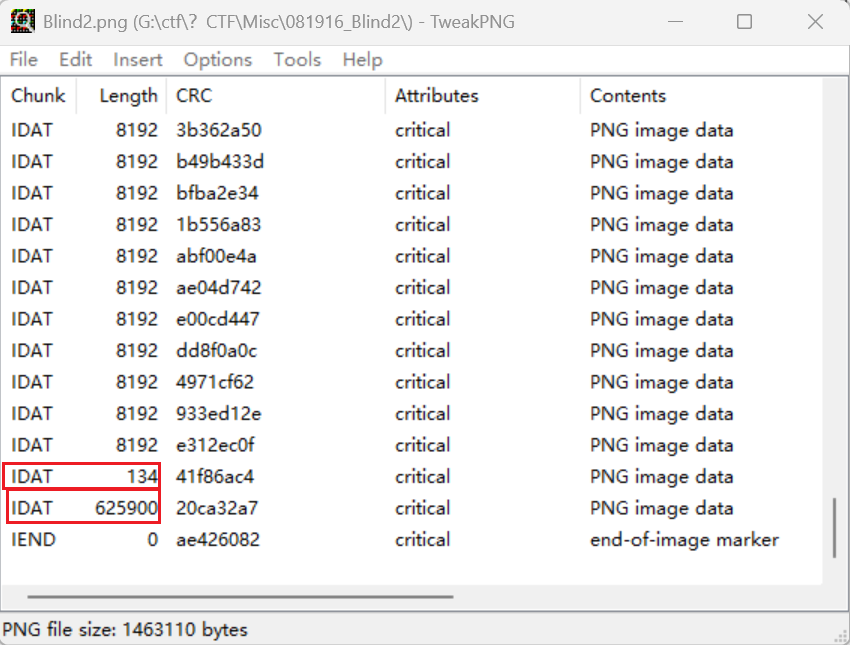
一般一张png图片在生成的时候就会计算出图片的IDAT块长度,超出长度的会被放入下一个IDAT块中,因此基本上是定长,直到最后一块
所以这边的长度明显不对劲,134应该就已经结束了
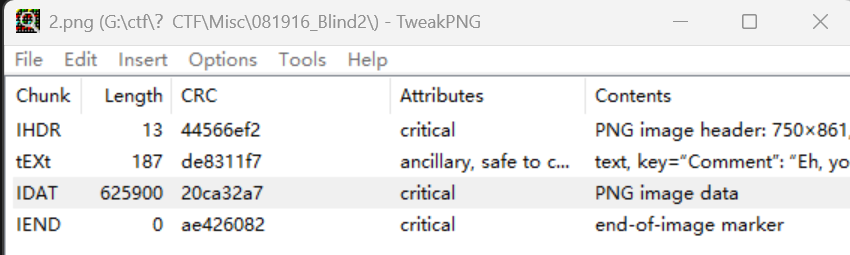
所以下边应该是第二张图,我们保留原来的头和尾,单独提取出上半部分和下半部分
保存之后发现依旧看不出啥区别,但是我们于此获得了两张图
这就涉及了另一种盲水印,双图盲水印
这是一种将信息存放在两张图的差异关系的水印隐藏方式
尽管这边同样是把信息通过DCT,DWT等手段叠加在图一的颜色通道特定频率上
但这边的“盲”就不再是不需要原图的意思了,我们需要两张图片配对使用
将双图xor后会发现黑色底蓝色条纹的图片,这也是双图盲水印工具的一大特点(我怀疑是这个信息藏在蓝色通道上,因为蓝色的改动人眼最难察觉)
于是我们确定了隐写方式,进行双图盲水印解密即可
https://github.com/chishaxie/BlindWaterMark
脚本如上,主要是两个步骤解码
首先是提取拆分
1 2 3 4 5 6 7 # 分别对原图和带水印图做傅里叶变换
然后再水印恢复
1 2 3 4 5 6 7 8 9 10 11 # 使用相同的随机种子生成打乱序列
最后即可得到flag
flag{W@tch_underw@ter}
[Week3] 文化木的侦探委托(三)
委托毫无进展了,下载附件看看
文件损坏了!根据题目提示好像只有三四五处坏了
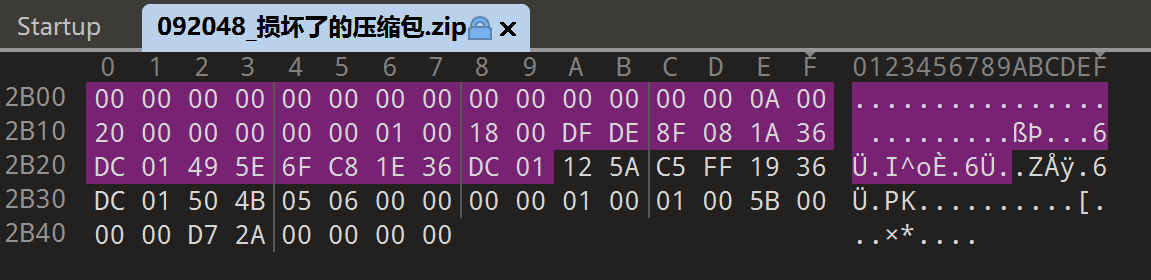
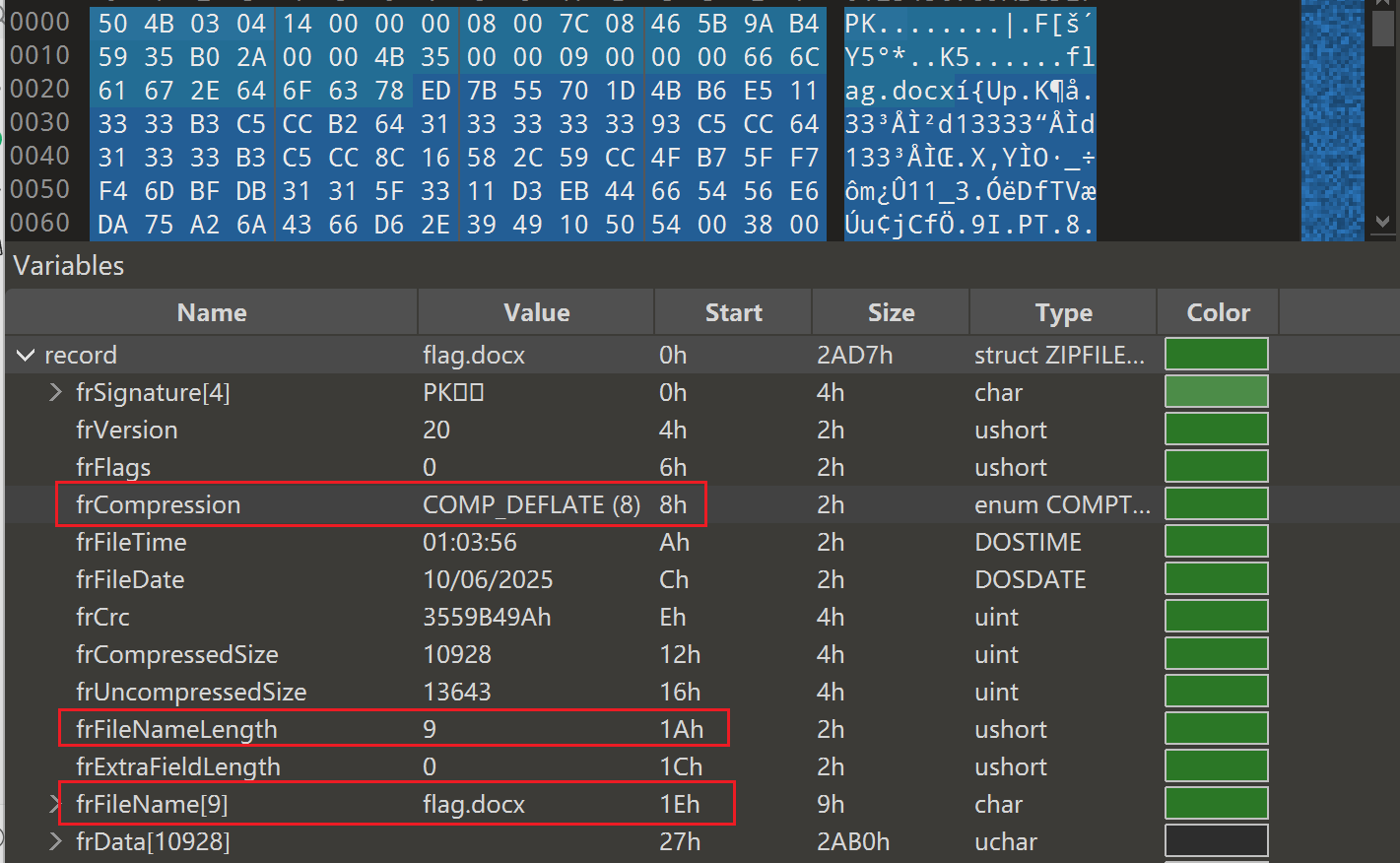
发现压缩包的dirEntry区损坏了,在修复之前:
这一道题主要涉及了Zip文件的解压流程,我们来理一下思路
我们都知道,zip分为三个结构,目录结束标识存在于整个ZIP的结尾,用于标记压缩的目录数据的结束,因此每个压缩文件都必须有且仅有一个EOCD记录
而对于zip解压而言,一般是分为四个阶段进行解压
首先是阶段1:定位到中央目录结束标记EOCD
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 bool FindEndOfCentralDirectory(FILE* zipFile) {
EOCD的结构如下
读完这一部分,系统就知道如何读中央目录了,然后就跑去读中央目录了,进入阶段2,开始循环读取每个dirEntry
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 // 读取中央目录
之后进入阶段3,先根据刚刚在dirEntry得到的偏移量,跳转到本地文件头,接着开始从record读取数据,遍历而解压每一个位置
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 void ExtractAllFiles(FILE* zipFile, vector<ZipDirEntry>& dirEntries) {
到此基本就结束了,只有少部分才有第四阶段
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 // 处理数据描述符的情况
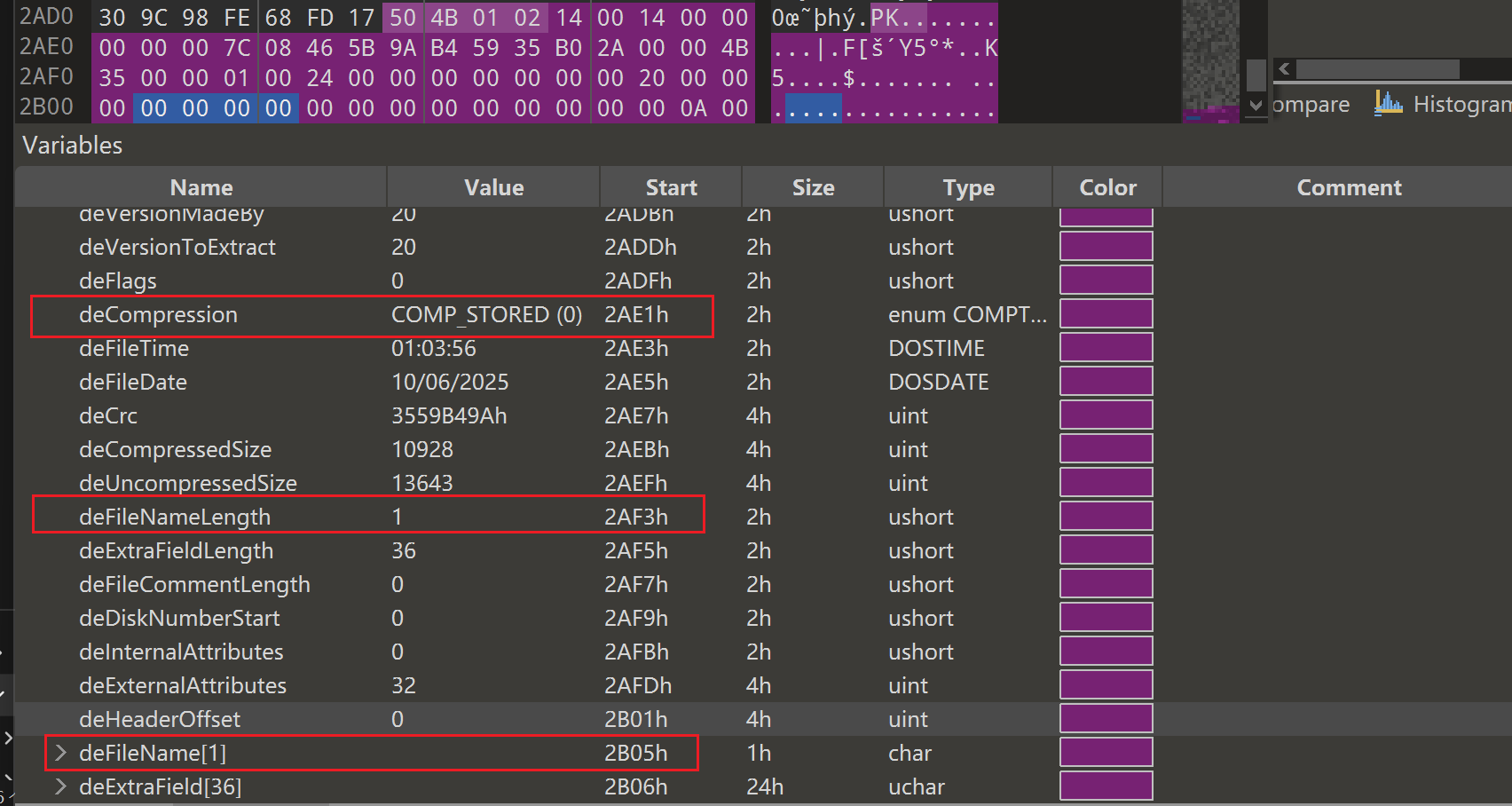
大概理清楚之后我们其实可以了解到,损坏的dirEntry区作为中央目录,它和record区是双向关联,功能互补,冗余验证的,我们既然dirEntry区坏了,自然是可以利用record区的
这个利用有两层意思
第一层就是正常对照着record区对dirEntry区进行修复工作
对照可以发现是deCompression、deFileNameLength和deFileName三部分遭到了修改,我们照着record区的数据改回来
就能顺利打开了
打开后得到flag~
flag{keep_m0ving_forward_f0r_the_ro@d_ahead_1s_l0nger_and_hard3r}
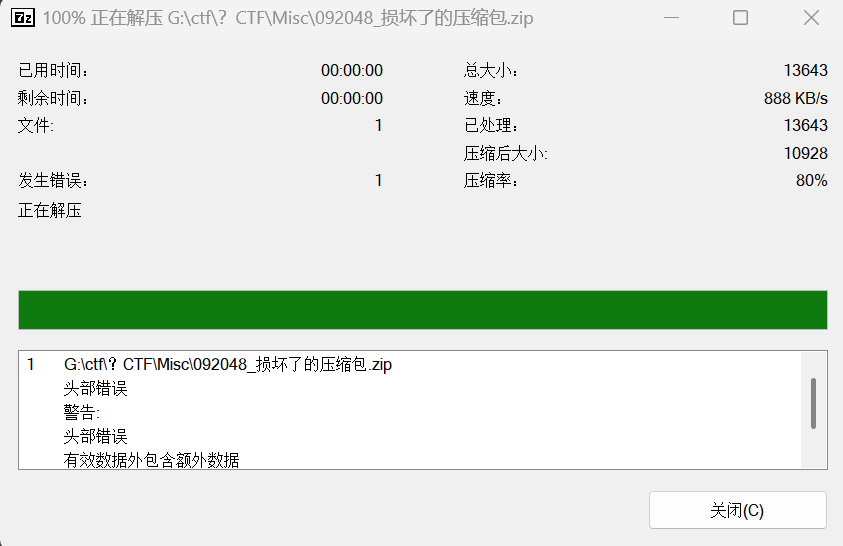
第二层利用说的是咱可以直接用record区解压啊()
我们知道题目只修改了dirEntry的内容,而我们7zip是只看record区的,因此这一道题如果我们用7zip是可以直接解压得到flag的
直接解压完直接看答案就好了
这个是这样的,bandzip会读dirEntry的内容,而WinRAR是两区都读,高级人
[Week4] 文化木的侦探委托(四)
上来文件比别的多多了,如果只看题目内容的话大致是我们需要这个原始的音频
但是上来给的四个文件什么都看不出来
我们从唯一可读的文件入手
发现这是一份GNU Radio Companion的流程图文件啊
主要目的是从音频文件password.wav里边提取信息
我们先下载一个GNU Radio Companion
https://github.com/radioconda/radioconda-installer
在官网下载后打开
大概界面如图,这是GNU Radio这个开源软件无线电SDR开发平台的一个图形化界面
主要是通过软件实现信号处理,无需专用硬件电路即可完成调制解码、滤波、频谱分析等任务
这边就可以看到是一些任务,我们刚刚的那个文件就是这样子一个流程图
只需将后缀改为.grc即可打开
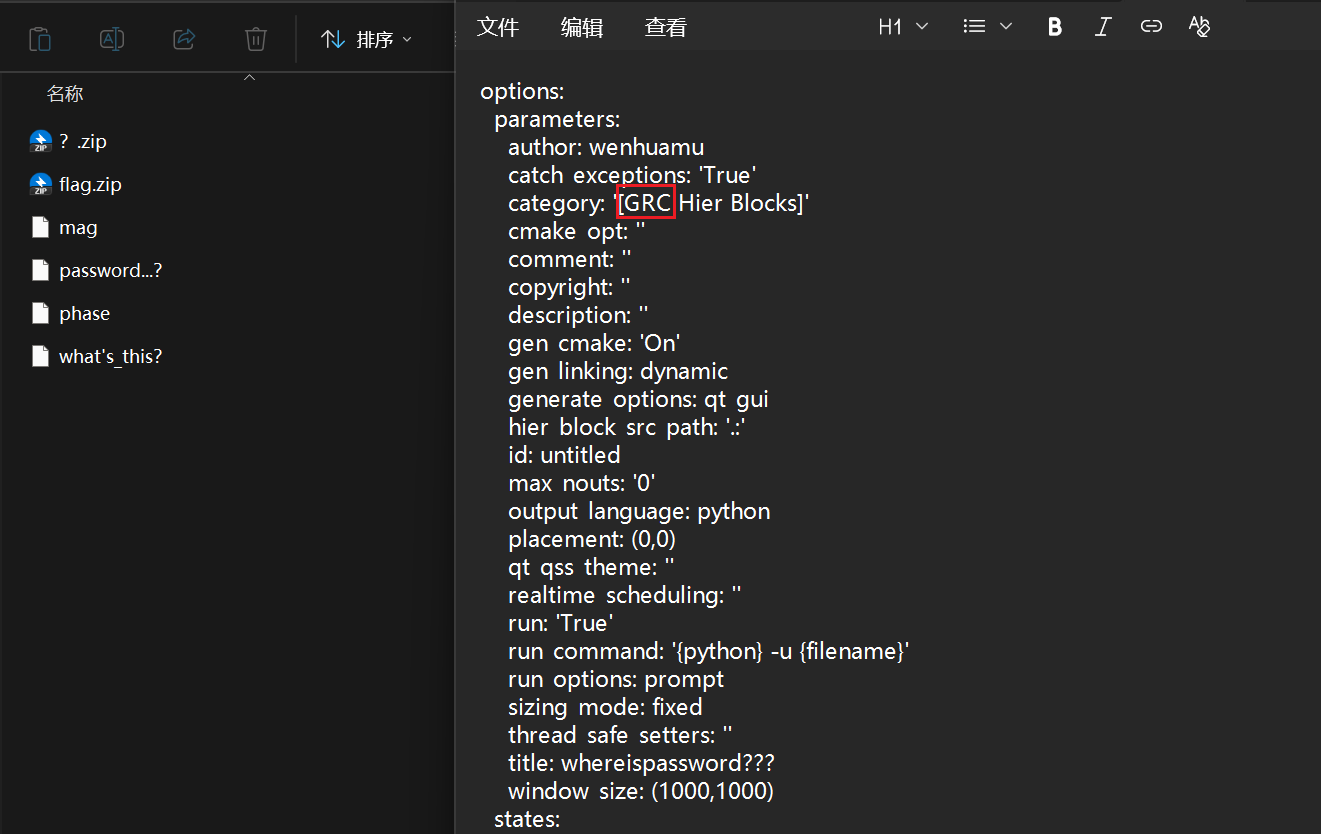
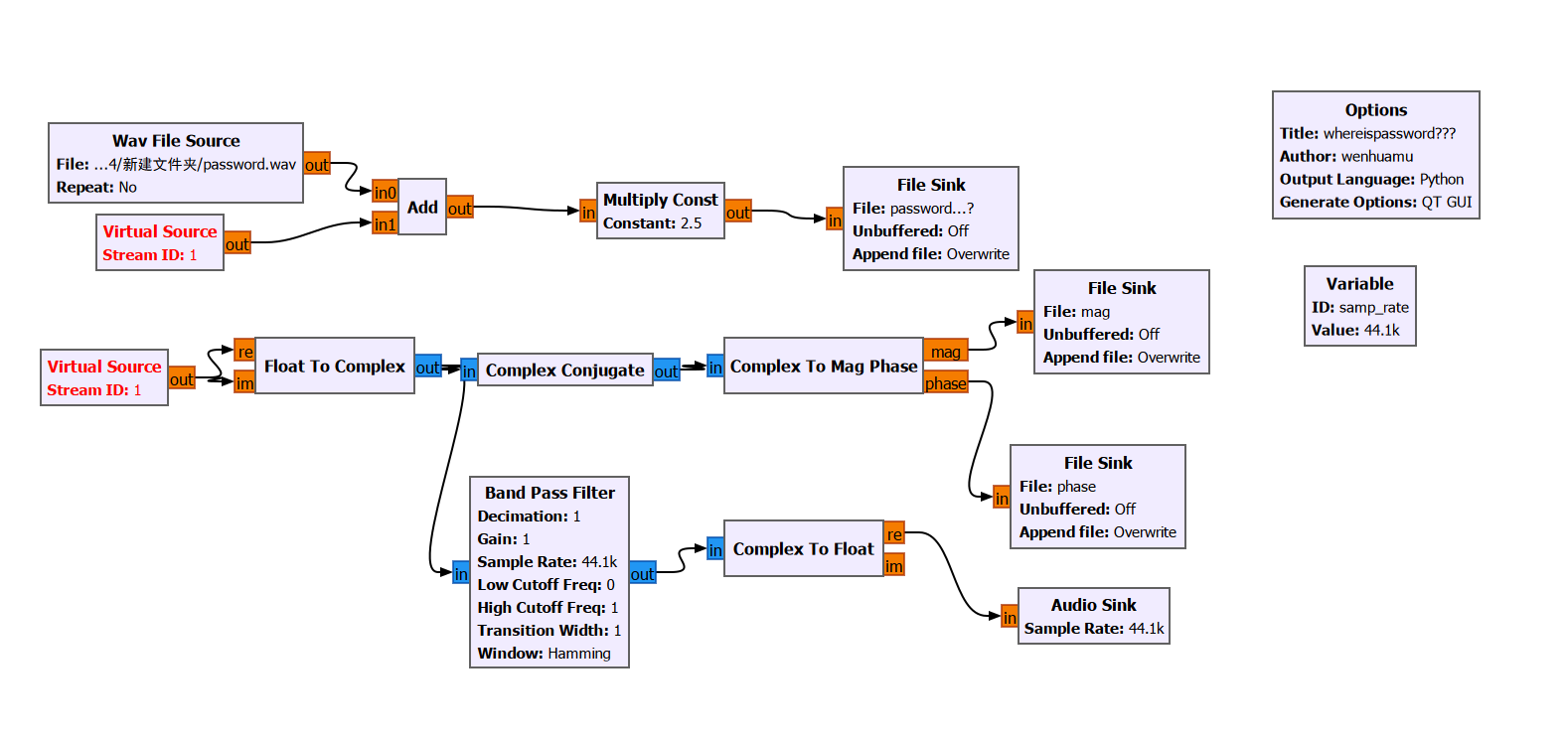
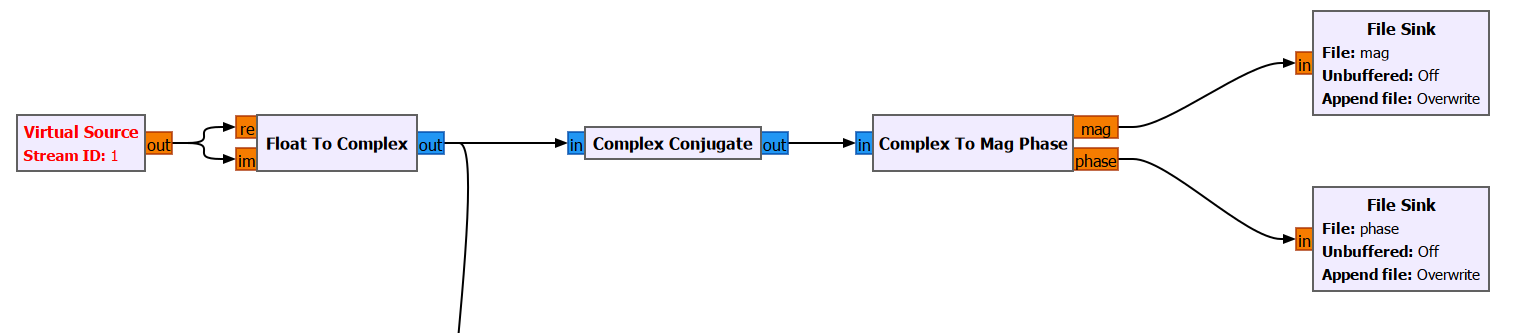
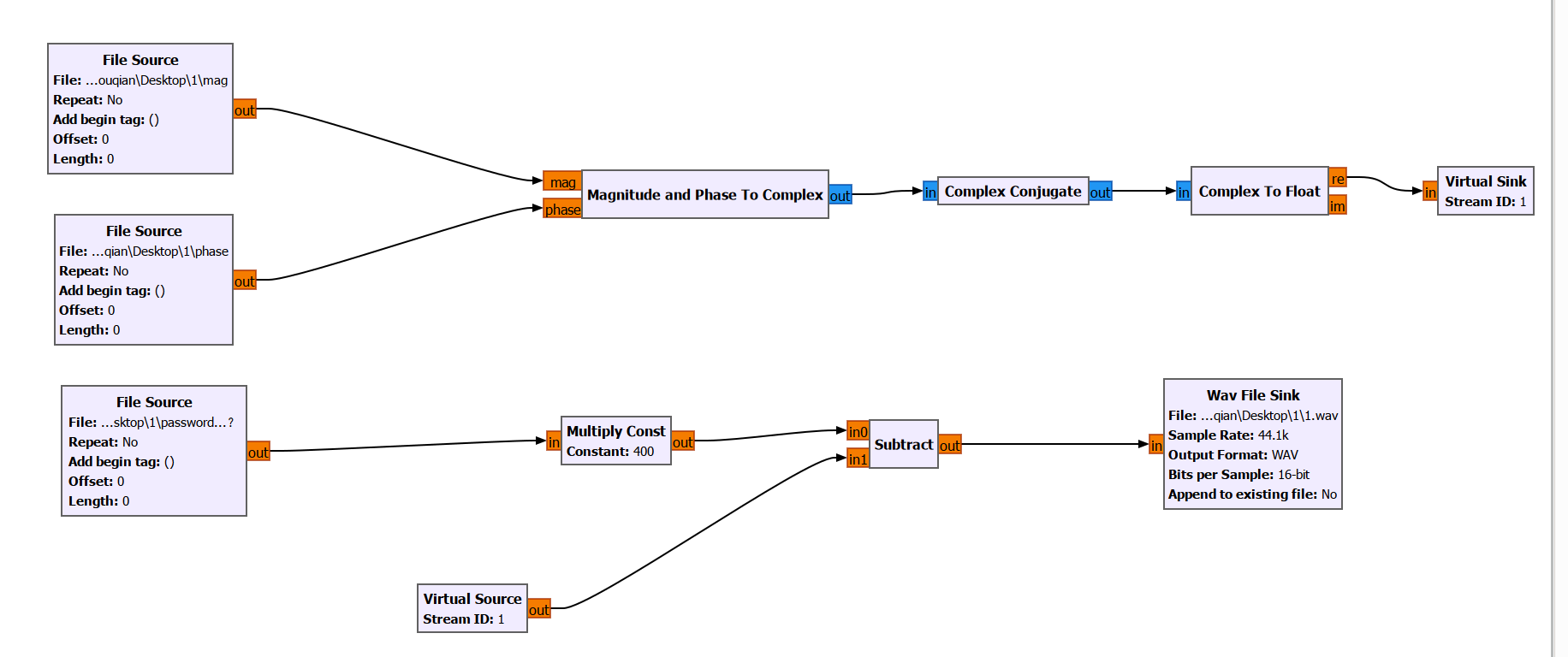
打开后可以看到流程图如上,在流程图可以看到很多最后产生的文件,都是一开始题目给的剩下三个文件,我们一个个来看
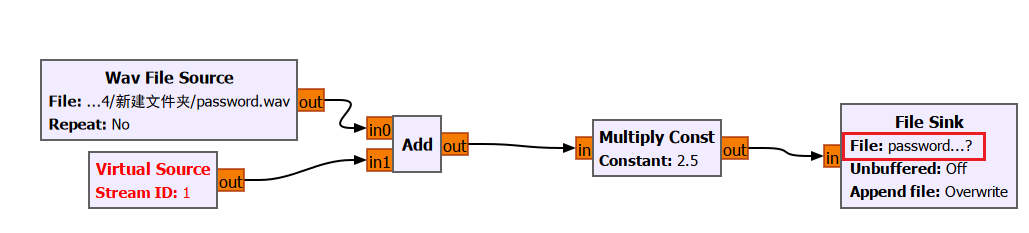
首先是这个password…?文件的产生,这是由一个password.wav产生的
就是(原音频+虚拟原信号)*2.5得到的这个password…?
现在还差个虚拟原信号Virtual Source
正好下边俩文件可以逆向出这个
这俩文件不是白给的
这个mag是个复数幅度信息文件,phase是个复数相位信息文件
这下可以直接逆推出Virtual Source了
我们保存的:mag = |Z_conj|, phase = arg(Z_conj)
其中 Z_conj = 共轭(Z_original)
所以Z_conj = mag × exp(j × phase)
那么Z_original = conjugate(Z_conj) = mag × exp(-j × phase)
大概就是这样子
这边解法的话有两种,一种是直接python解
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 import numpy as np
当然了,我们也可以直接在GNU进行解密的
特别要注意每一块的type设置,否则红的不让用,建议是走全英文路径,避免失败
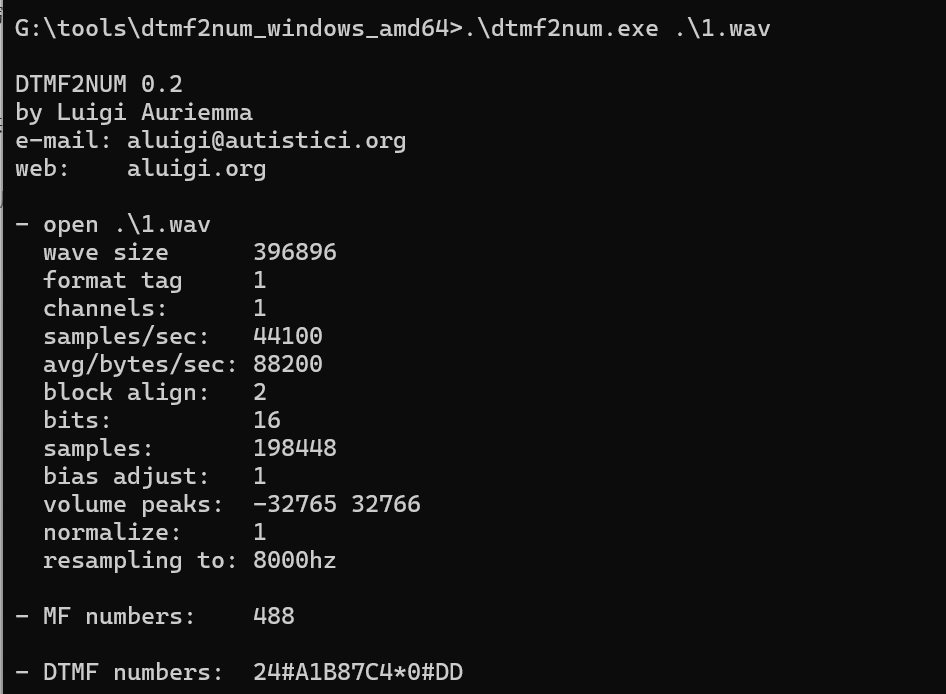
不管用哪种方法我们都能得到解密后的音频文件
听出来大概是拨号的声音,所以我们下载一个相关的拨号解密工具
Releases · Moxin1044/DTMF2NUM
得到压缩包密码:24#A1B87C4*0#DD
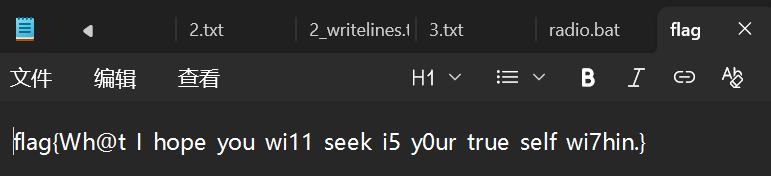
解开即可得到flag
flag{Wh@t_I_hope_you_wi11_seek_i5_y0ur_true_self_wi7hin.}
[Week1] 俱乐部之旅(1) - 邀请函
上来就是个加密压缩包,这边看上去像掩码啊?
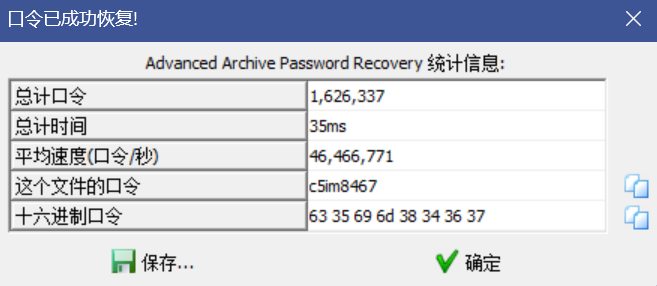
试试看
秒出
c5im8467
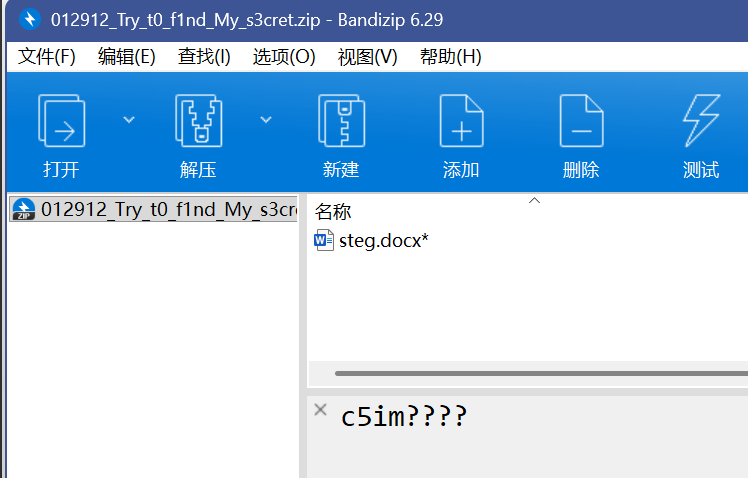
OK,这个word有问题,word隐写应该一共就没几种
改后缀为zip,看看内容
果然能发现一个
看上去是十六进制
啊,好像是后半段?
还有一半应该在文档里边
打开来可以看到头上有一些内容
“重要的内容就应该存在备注中”
原来写的是这个
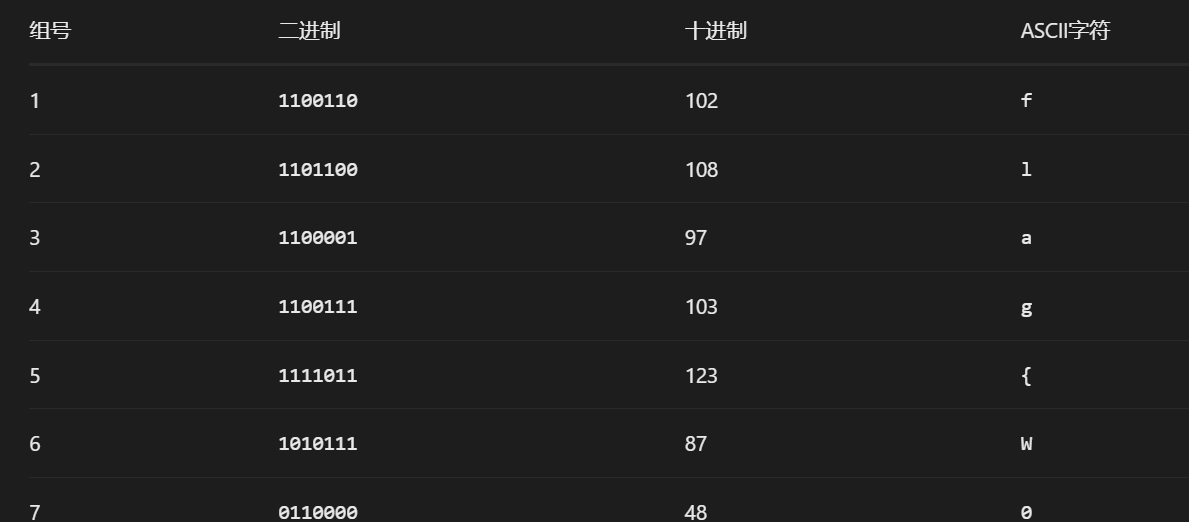
写了让我用每7位转一个ASCII码了
那我直接转就是了
flag{W0rd_5t3g_is_1z
所以flag为flag{W0rd_5t3g_is_1z&Welc0me_t0_th3_c5im_C1ub}
[Week1] 维吉尼亚朋友的来信
噢?是音频隐写题
Audacity开起来看看
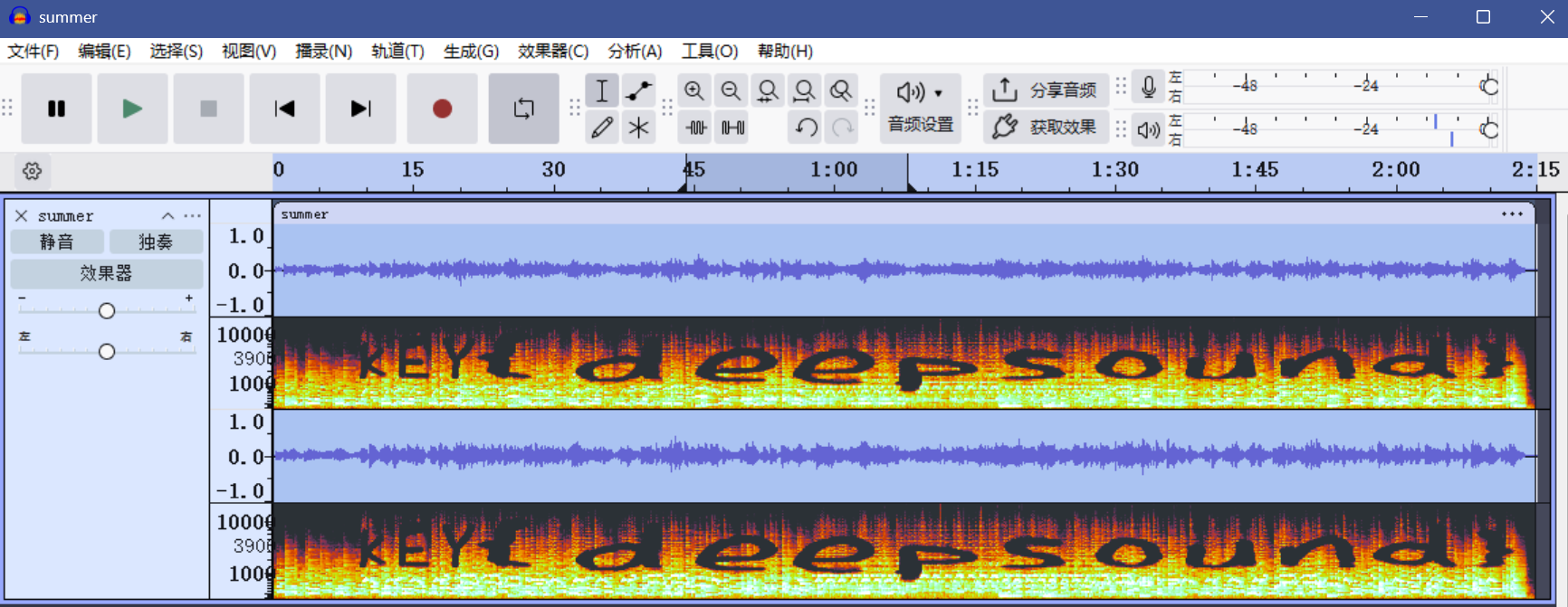
是菊次郎的夏天啊,挺好听的,还是双声道的
打开多视图直接就看见了KEY{deepsound}
给了key,就是有key的音频隐写了,又说deepsound,那很有可能是deepsound加密
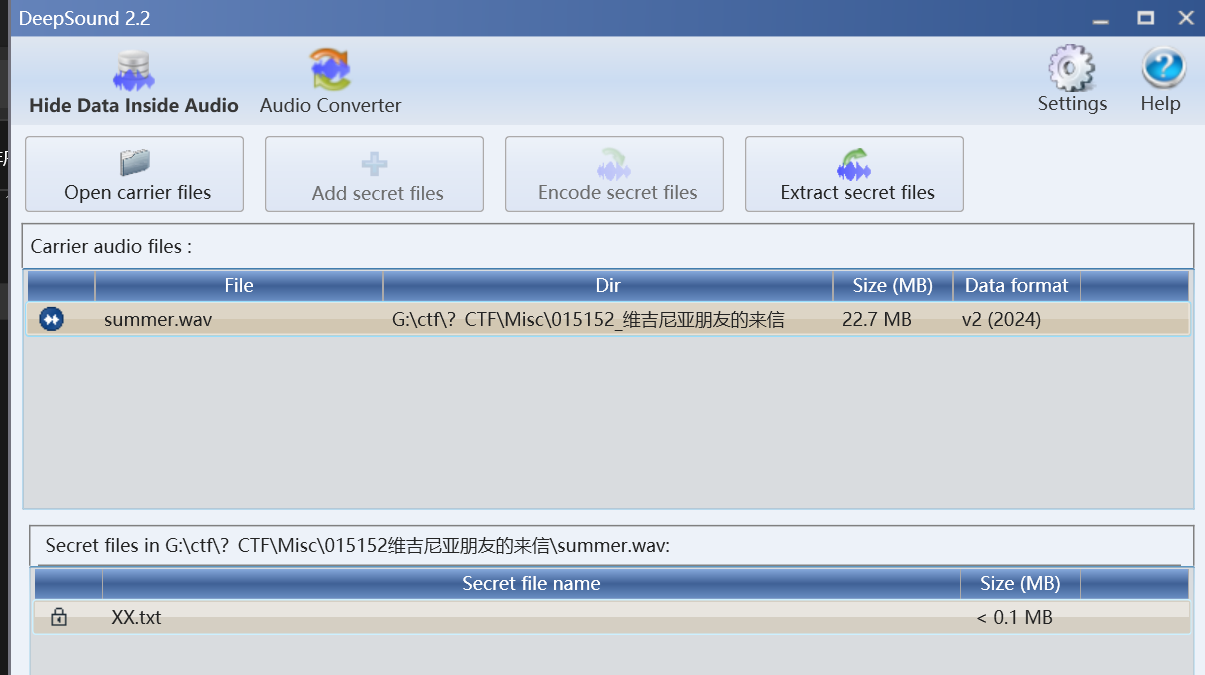
之前直接扔到deepsound一直出不来,现在判断下来是版本太低不支持Win11(嘻嘻当时做了一辈子都搞不出来看傻了)
问题不大,下一个最新版Deepsound2.2
https://github.com/Jpinsoft/DeepSound/releases
得到一个txt文件
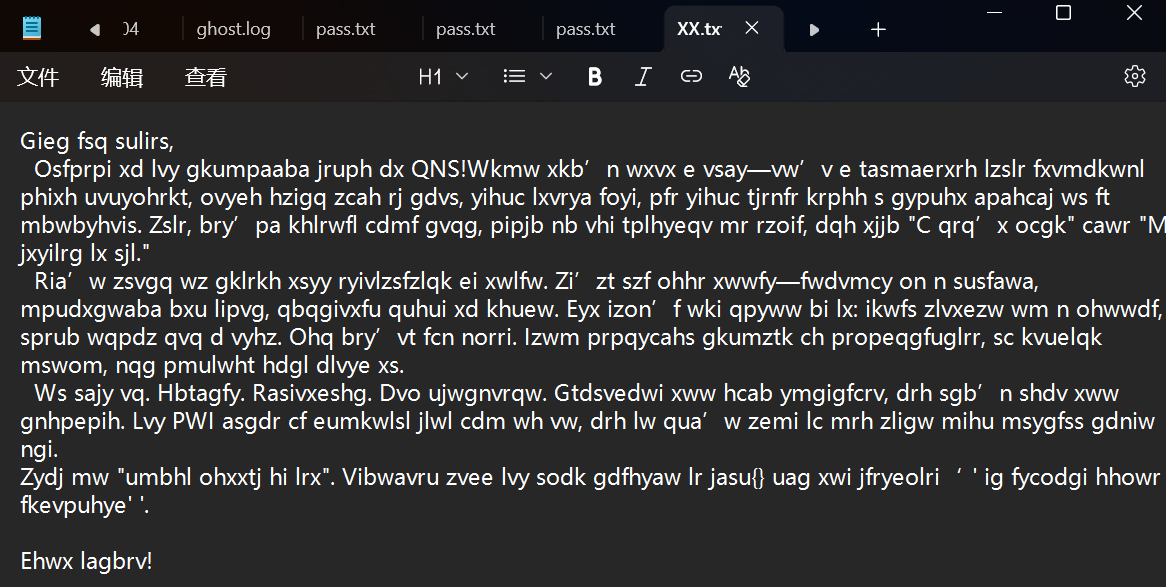
打开来明显发现有加密,根据题目名字推测是维吉亚娜,key应该就是deepsound
得到flag是flag{funny_letter_to_you}
[Week1] 《关于我穿越到CTF的异世界这档事:序》
Osint [Week1] Task 1. 见面地点
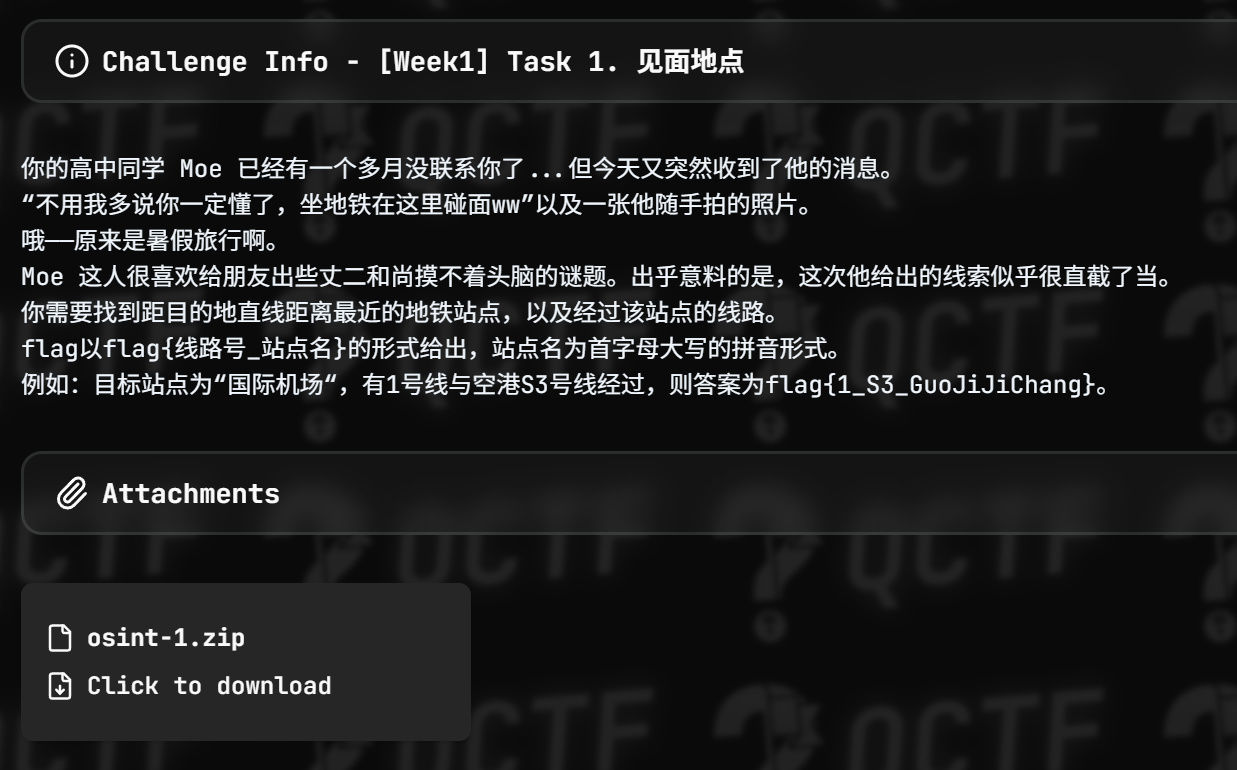
见面地点,看看图片
左边那东西还挺有辨识度的,是河南艺术中心,那就很好找了,大概能确定是郑州的郑东新区那边,然后找找地铁站就好
是会展中心站,然后是郑州地铁1号线和4号线的交接站
接下来就直接构造flag模板就好了,这玩意AI能直接看出来
如图:
flag{1_4_HuiZhanZhongXin}
Forensics [Week1] 取证第一次
话都说到这份上了,去日志里找就是了
是个镜像,我们火眼打开分析
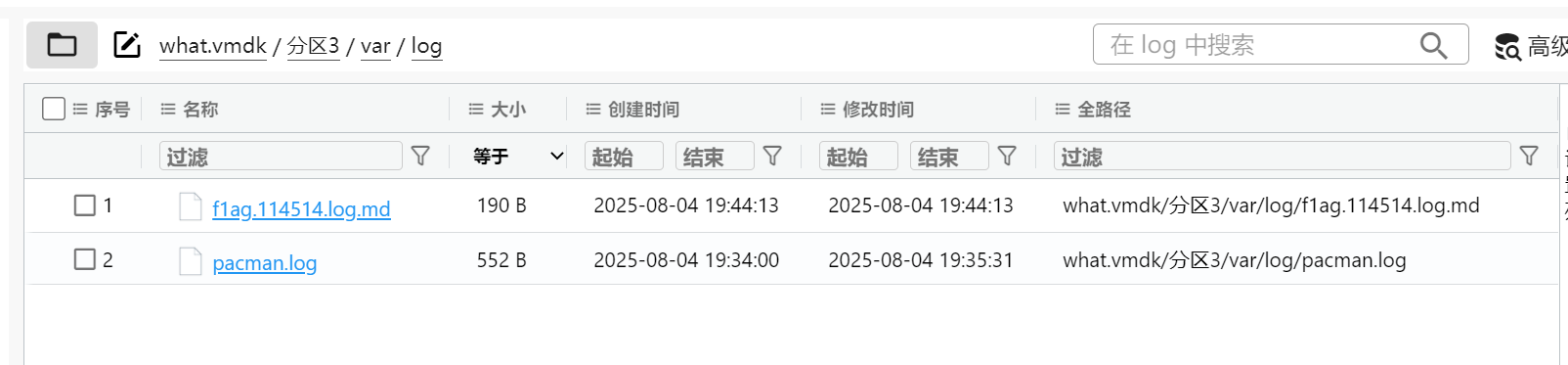
直接在路径/var/log就能找到flag的日志文件
这也太简单了(??)我发现现在的CTF取证题目要么我是一点不会,要么就是一眼出
flag{F0r3ns1cs_i$Fun_Rea11y ???}
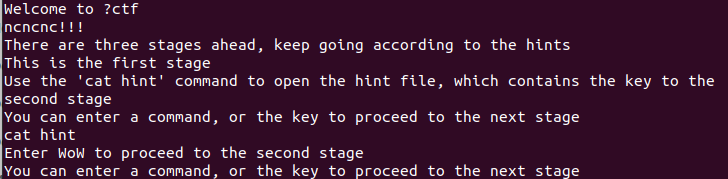
Pwn [Week1] ncncnc
太好啦!是nc,我们有救了
上来先是cat应用
第二部分是cat和hint的绕过,因为只是字符串进了黑名单我们可以直接用单引号绕过
c’at’ hi’nt’即可
第三部分绕过空格,只要${IFS}绕过即可
这题出的全是绕过啊,像web题
得到flag{b59a0c9c-c448-499b-b784-20939501c441}
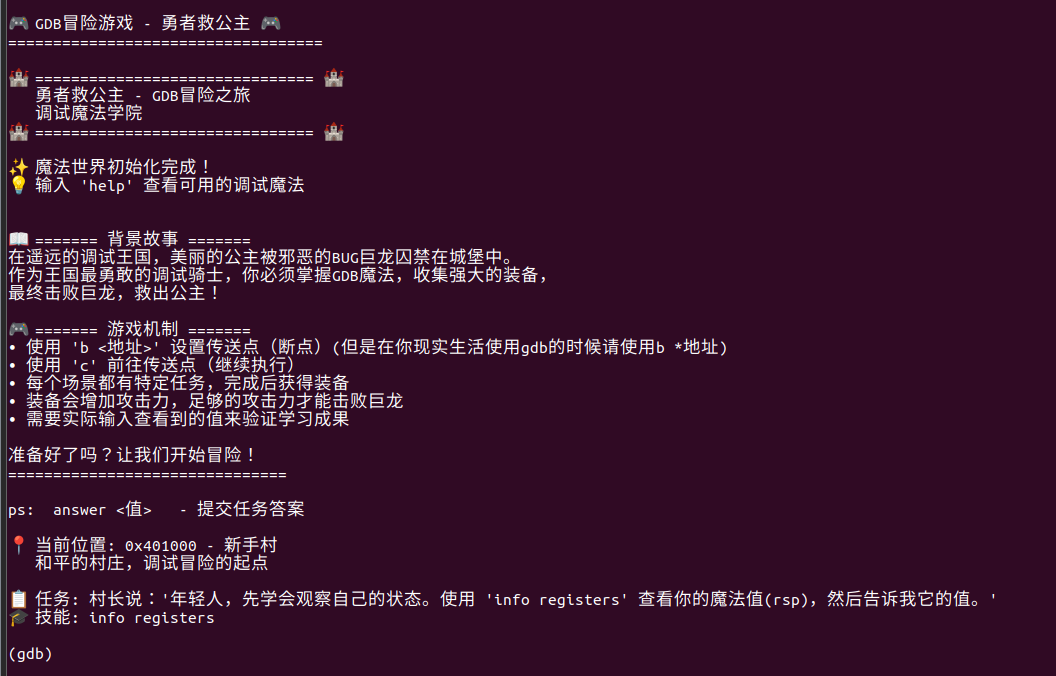
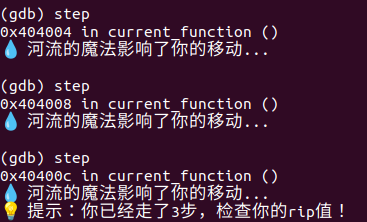
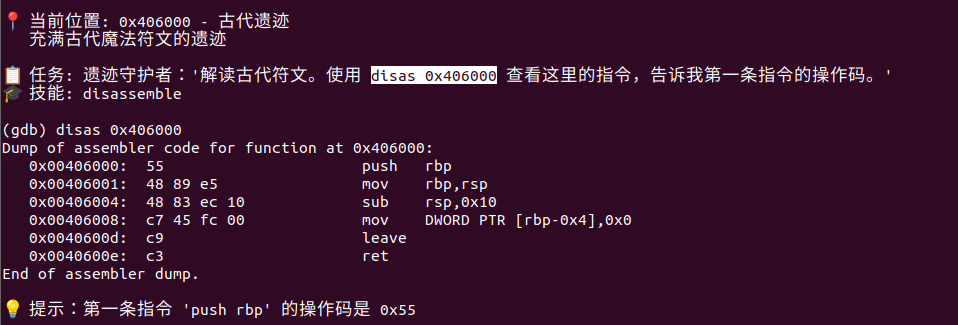
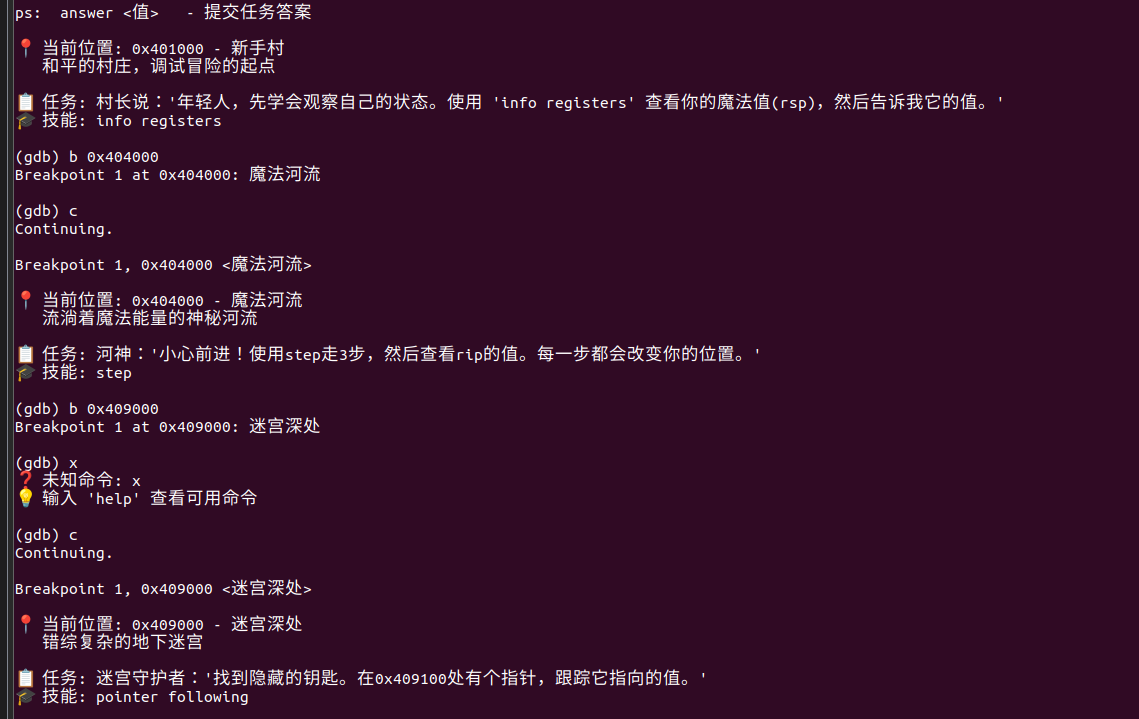
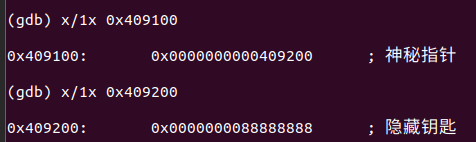
[Week1] 勇者救公主
是一道又臭又长的复制粘贴题
给的提示太多了导致很没意思
就是这样子,每一步都全是提示
主要是又臭又长,太久不动又要重新开打
但是似乎可以跳关
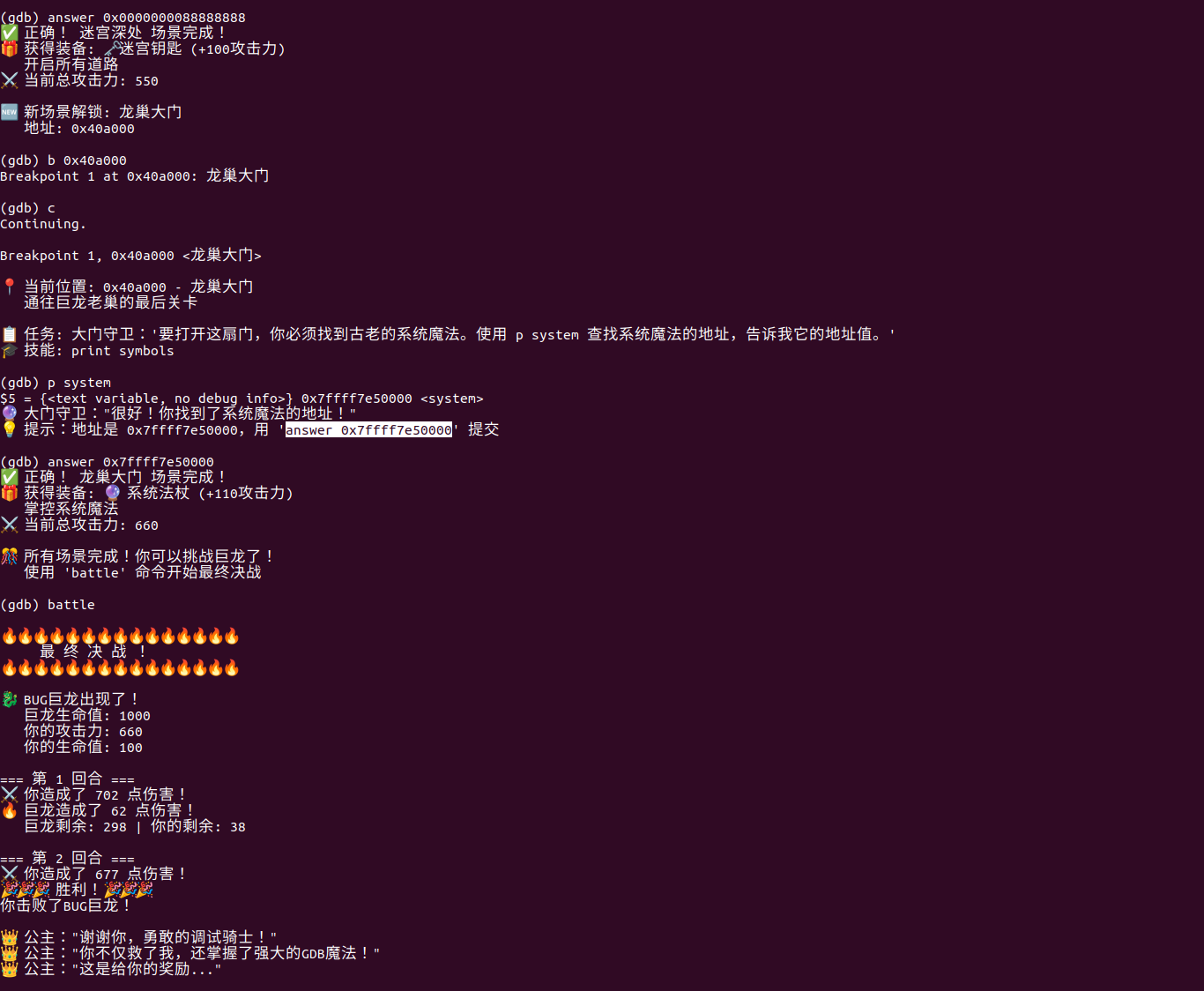
看指向的值x/1x 即可
噢好吧,不能跳关,跳关了交不上答案
一步步就好,后边提示都是直接报答案的,我实在不知道有什么写wp的必要
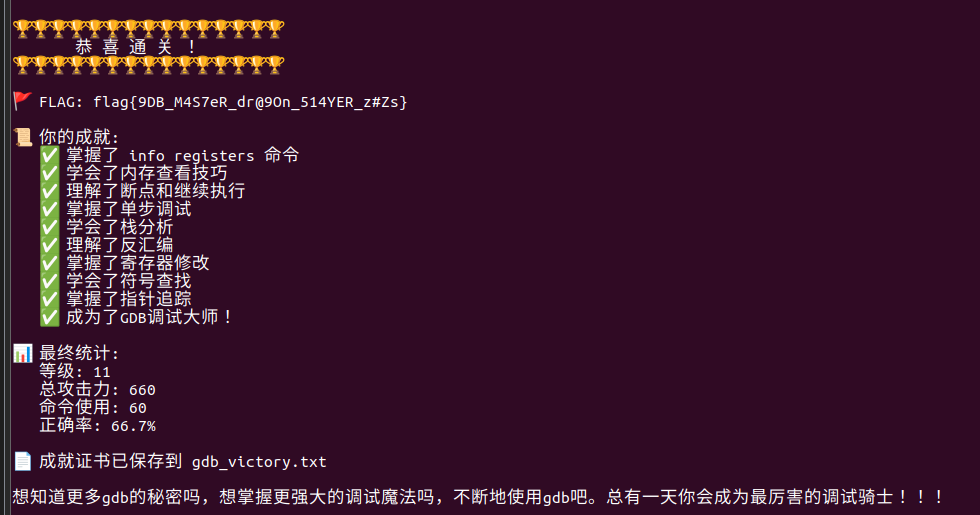
flag{9DB_M4S7eR_dr@9On_514YER_z#Zs}
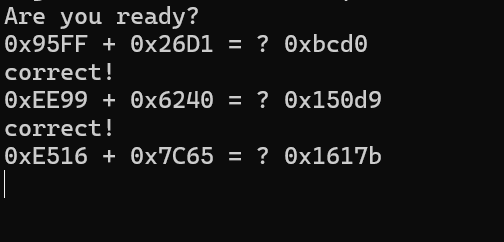
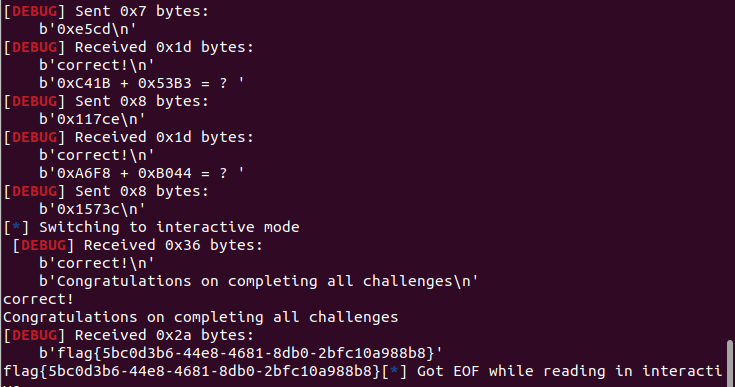
[Week1] count
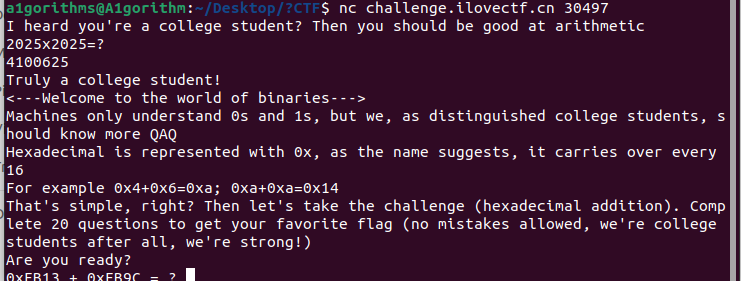
我们先nc试试看
似乎后边需要很快的回答速度,否则会马上结束,所以这就是需要写代码了,手打肯定来不及,我直接复制粘贴进python算都来不及
先截断在2025*2025,然后去发个4100625
后边等到进入运算阶段,每次都截断?即可,后边开始提取十六进制数算一下,都是加法,再发过去
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 from pwn import *
直接就输出flag了
flag{5bc0d3b6-44e8-4681-8db0-2bfc10a988b8}
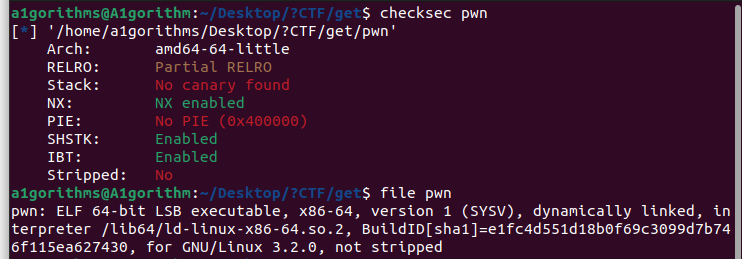
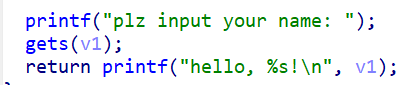
[Week1] 危险的 gets
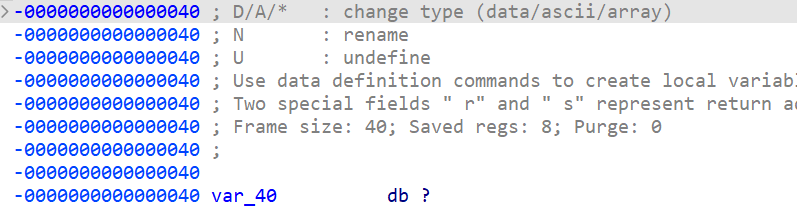
保护:
看看main函数,64位
好看起来是个溢出的rop题目
0x40+8溢出
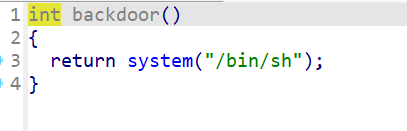
溢出后直接去后门函数即可
backdoor=0x0004011B6
注意栈对齐
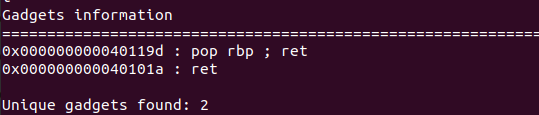
ROPgadget –binary “pwn” –only “pop|ret”
ret=0x40101a
直接写代码吧
1 2 3 4 5 6 7 8 9 10 11 12 from pwn import *
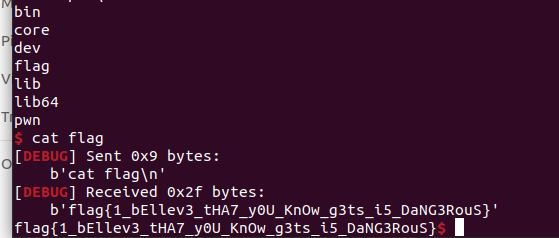
flag{1_bEllev3_tHA7_y0U_KnOw_g3ts_i5_DaNG3RouS}
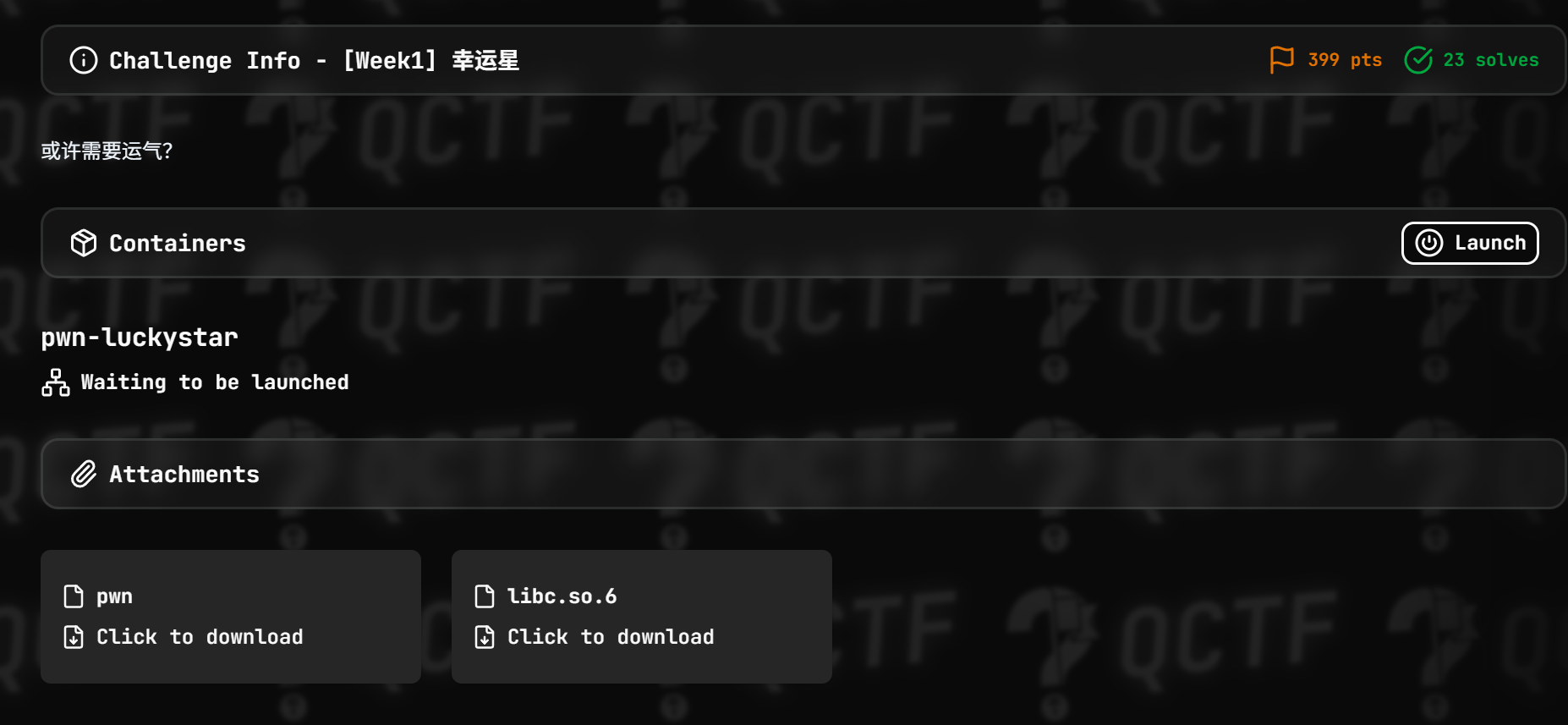
[Week1] 幸运星
幸运星?
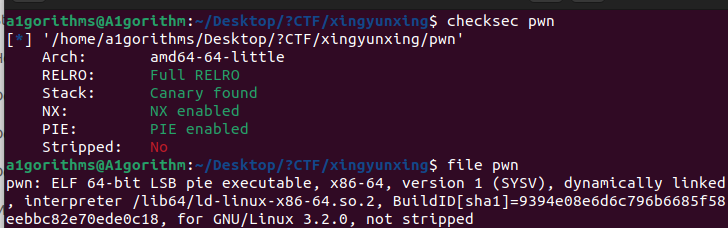
保护:
我靠全开啊
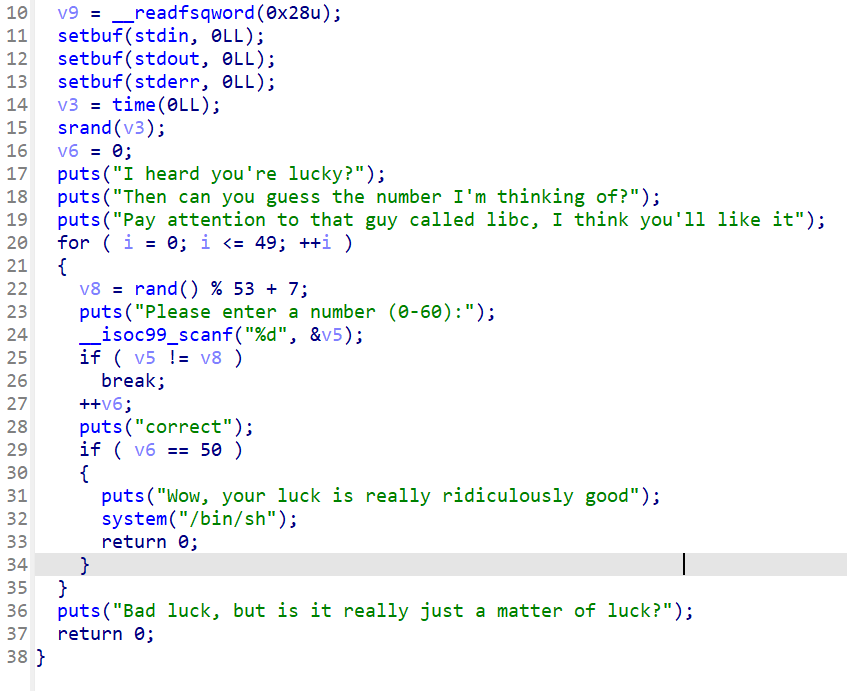
连续猜中50次就好啦~这怎么可能啊!
肯定需要动用libc了
Reverse [Week1] 8086ASM
考汇编语言来了
来看看汇编语言
大概理解一下逻辑,上边的是密文,下边的是key
然后要我加密后和上边的密文长一样
核心在于这个加密部分
主要是两部分
首先是循环右移,左边缺的由右边多的补
然后是异或加密:将当前字节和它的下一个字节作为一个整体,与密钥中的一个字进行异或操作。密钥是循环使用的,即用尽5个字后从头开始
大概理解之后就可以开始解密了,由于是异或所以不会很难,代码如下
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 def rol_byte(byte, shift):
flag{W31c0m3_t0_8086_A5M_W0RlD___!!}
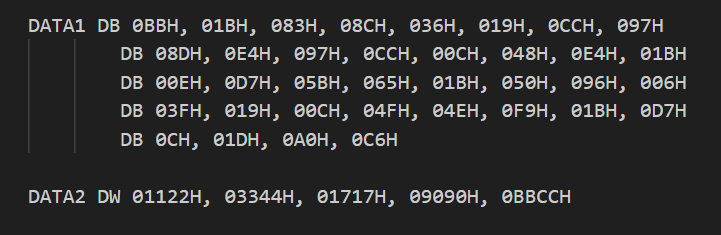
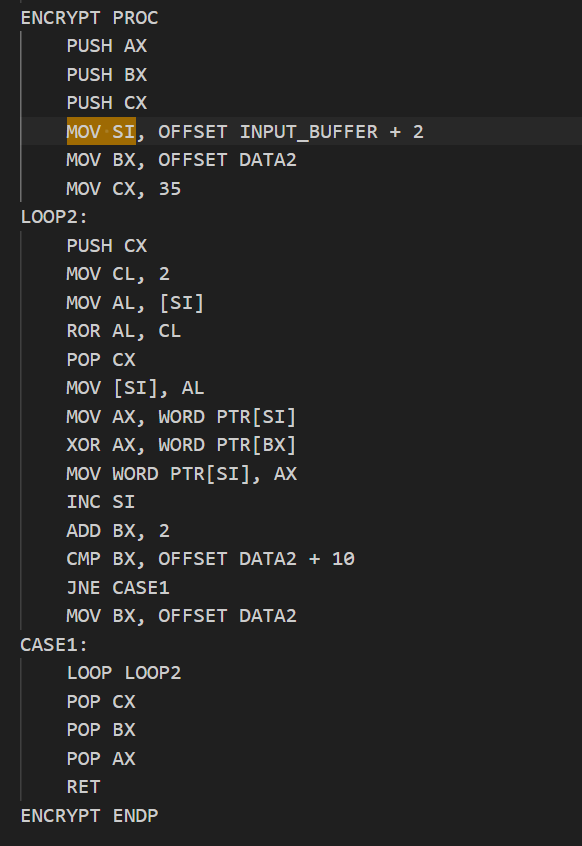
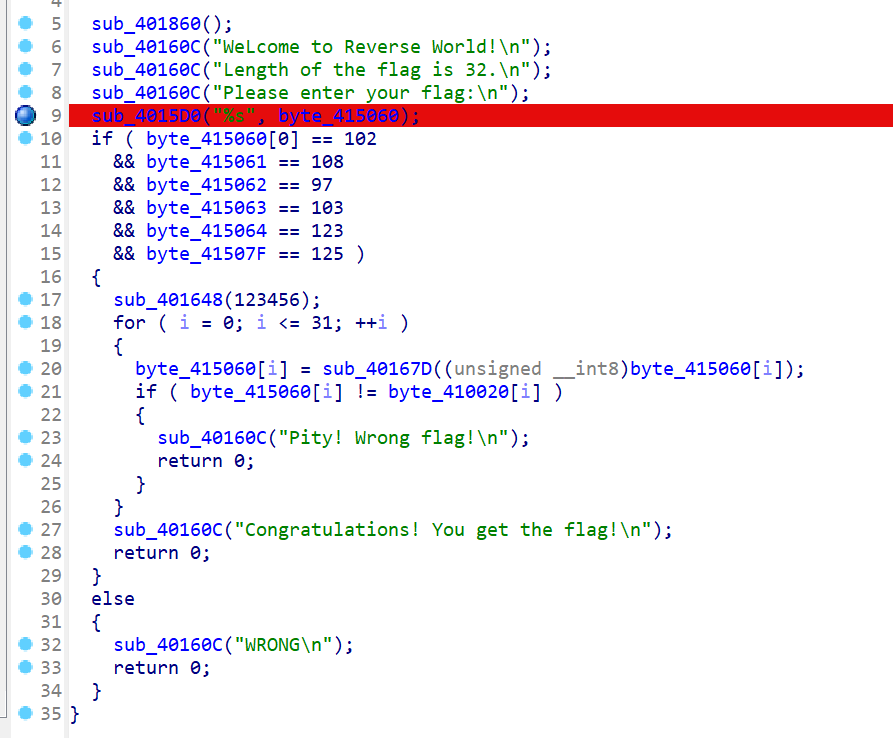
[Week1] PlzDebugMe
动调题
32位
在输入点先打个断点,动调看看
我的输入会放在这边,一共32个位置
会和这个比较
密文是上边这个
但是这边不能动调直接得到啊
毕竟是一个个检验的,不对直接return 0了,所以我们不能patch
那就看看加密过程吧
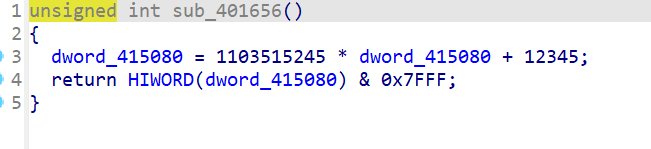
基本上可以确定加密函数就是这个sub_40167D
这是流密码啊
会生成一个伪随机数,然后和原来的异或去
我们可以根据前几位,如5B和66来确定到底在和谁异或
可能需要暴力破解一下流加密,因为是确定的,所以我们可以做到这一步
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 def lcg(state):
成功找到LCG初始种子: 0x1e240
解密出的完整明文是:
flag{Y0u_Kn0w_H0w_t0_D3bug!!!!!}
(好吧这一题是不是不应该这样子做?应该动调?)
[Week1] ezCSharp
这边需要用dnspy,正好我有
OK打开了
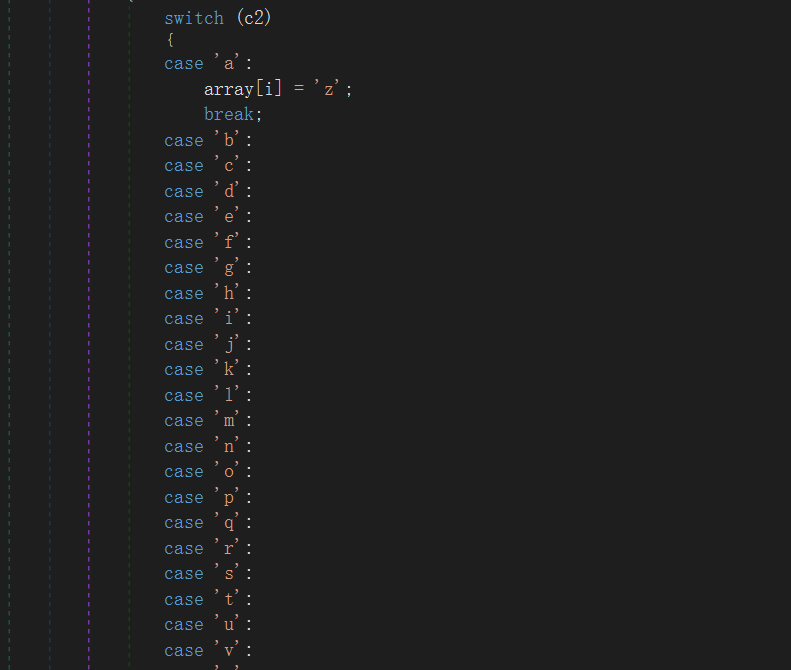
我们直接搜flag{很容易定位到这边,这边是很简单的加密,只是把!换成_,然后把a换成z,最后把b-z往前一位
Locate the ‘FlagContainer’ class in the Program Resource Manager
我们找找
其实搜感叹号也行,直接搜这个flagcontainer不知道为什么找不到
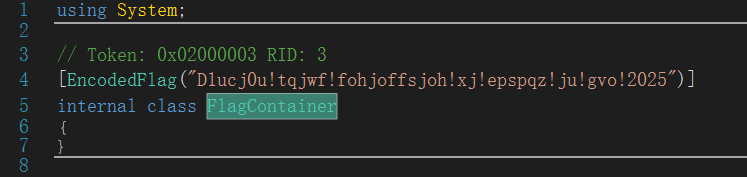
直接按规则解密D1ucj0u!tqjwf!fohjoffsjoh!xj!epspqz!ju!gvo!2025
先小写字母移1,然后把!换成_,然后把a换成z
flag{D1tbi0t_spive_engineering_wi_doropy_it_fun_2025}
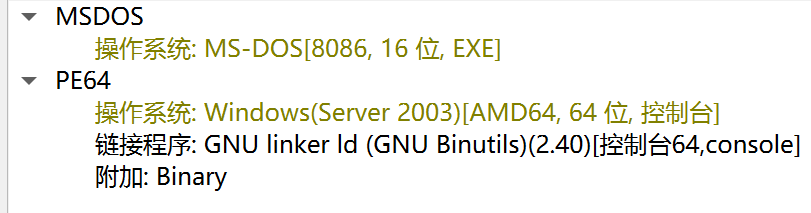
[Week1] ezCalculate
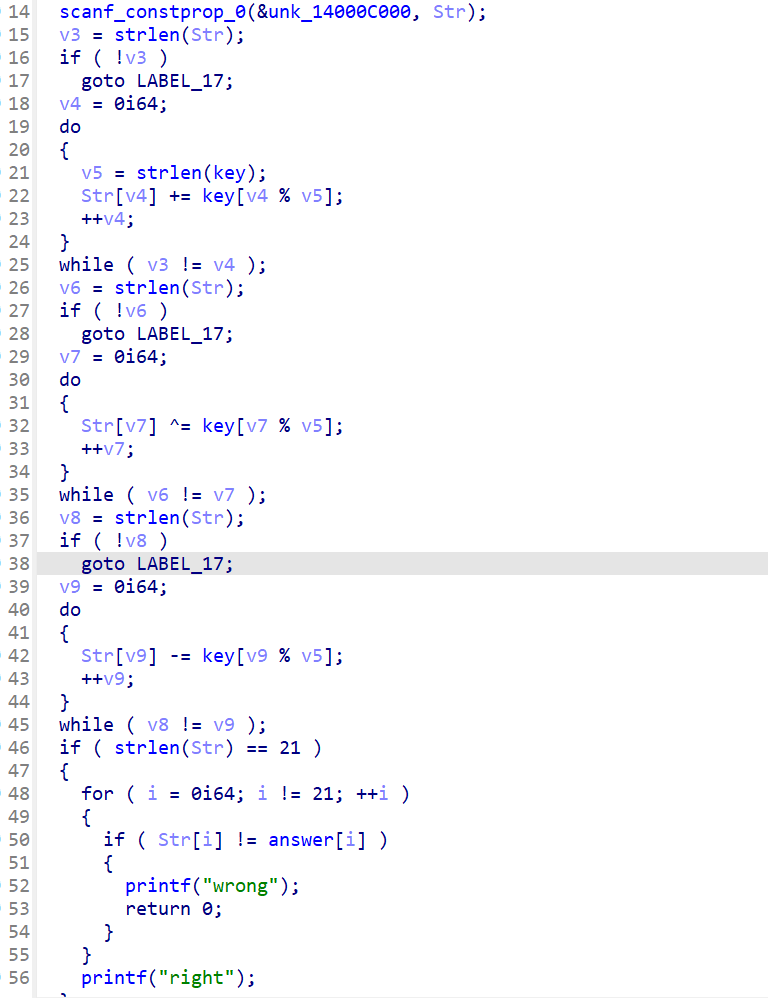
看看main函数,是很长的加密过程
先和key的内容相加,再和key的内容异或,最后相减,有够复杂的
我们直接逆向也是这个思路
key是这个wwqessgxsddkaao123wms
然后密文是上边这个
最后要和这个比
1 2 3 4 5 6 7 8 9 10 11 解密第三步:
然后就可以得到flag
flag{Add_X0r_and_Sub}
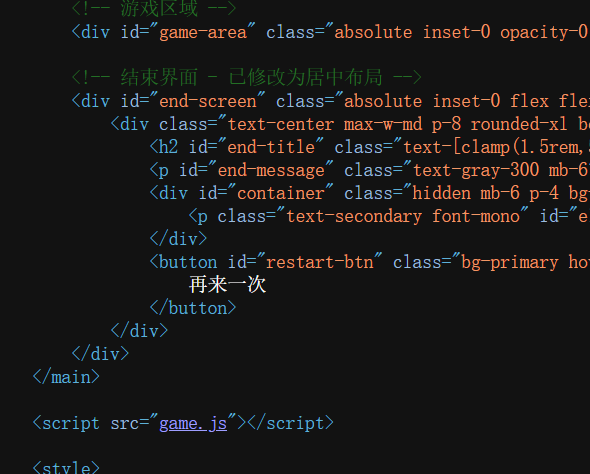
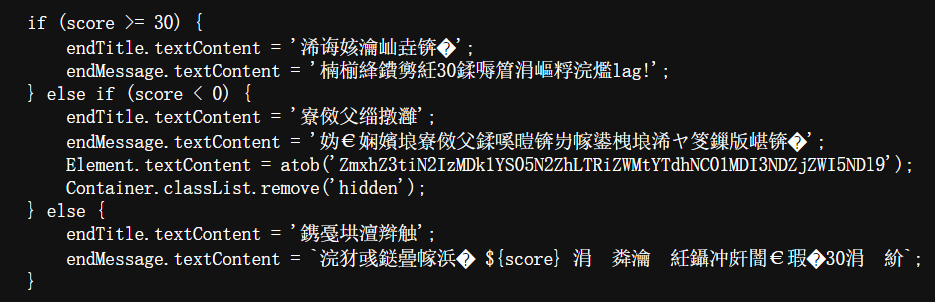
Web [Week1] 前端小游戏
是一个小游戏
结果就算60秒点了30个也不给flag,浪费我时间。。
在源代码可以看到game.js
然后我们点进去看看
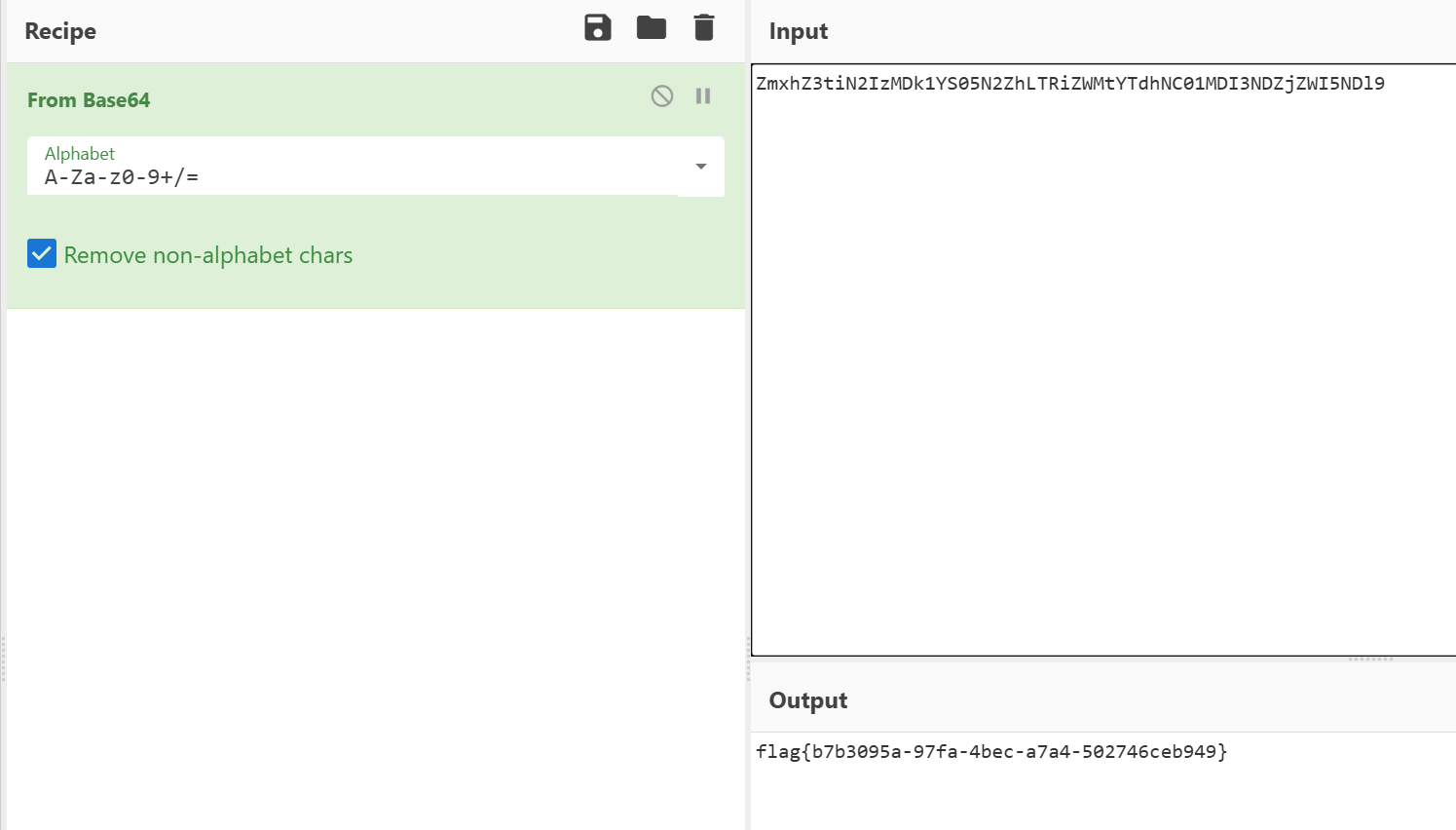
分高于30就发这些,这一眼base64
flag{b7b3095a-97fa-4bec-a7a4-502746ceb949}
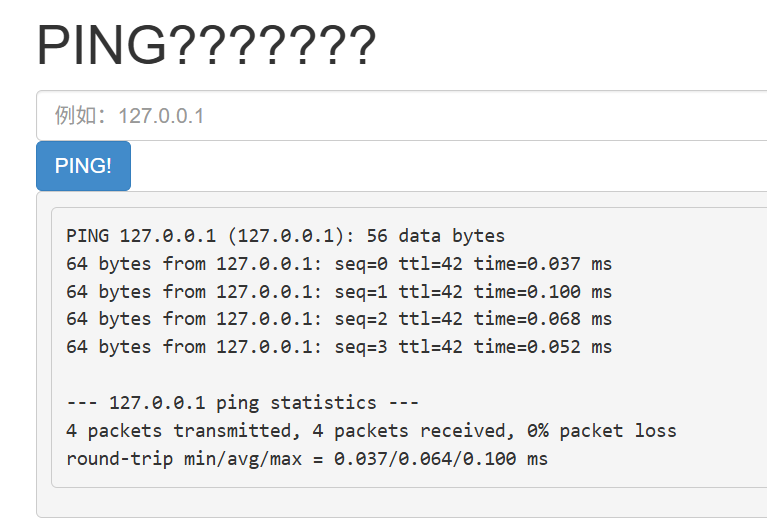
[Week1] Ping??
好眼熟的题目,nss好像有一道差不多的
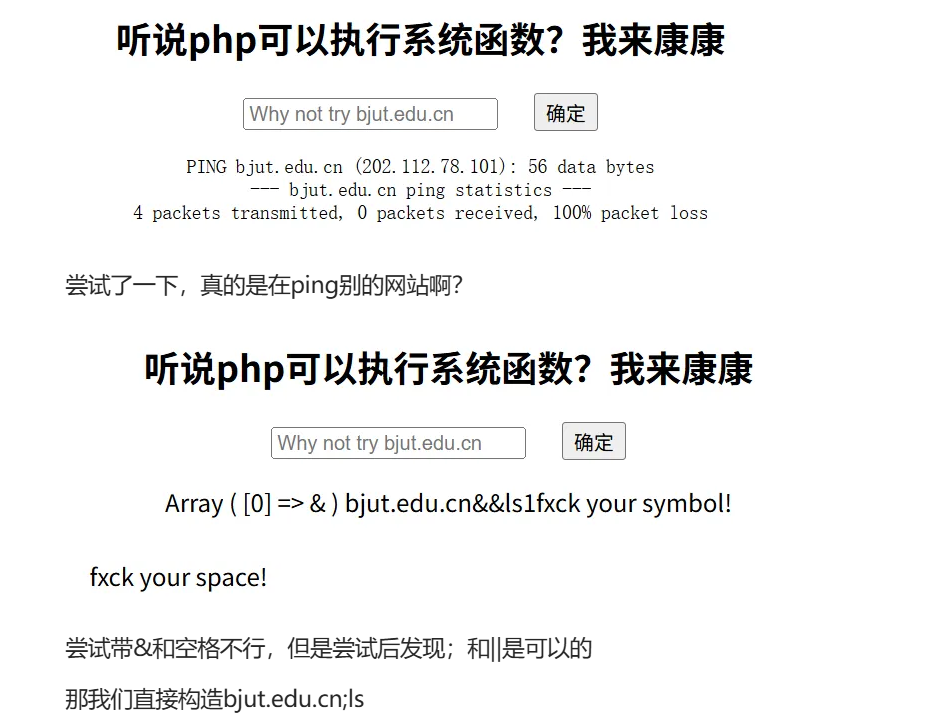
差不多是在后边加&然后加命令
那我们也试试看
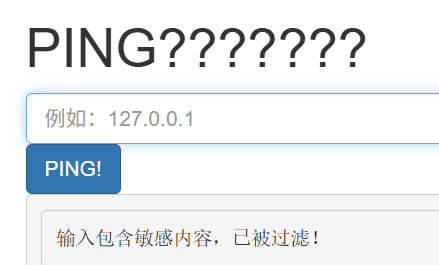
但是不知道过滤了什么,我们试试看
OK没过滤&,可以这样子做
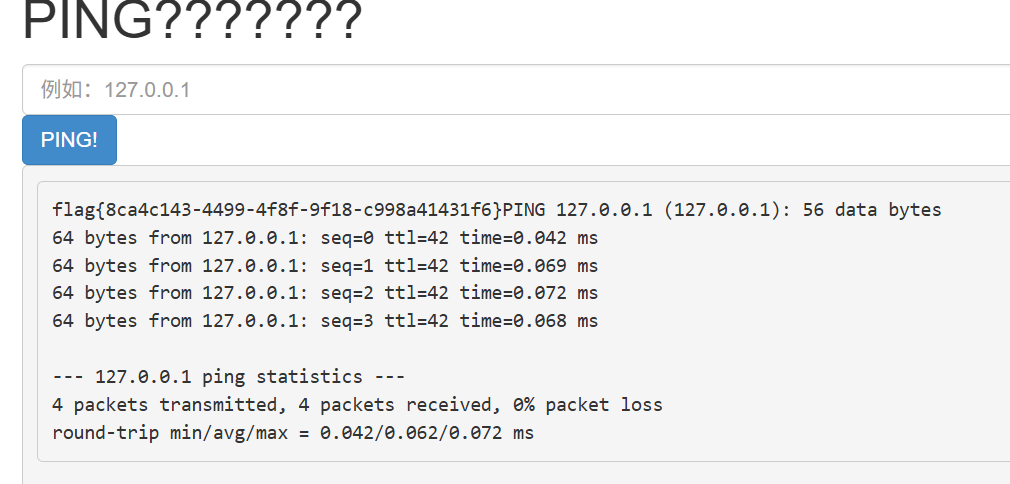
我们尝试127.0.0.1&c’at’ f*
直接就得到了
flag{8ca4c143-4499-4f8f-9f18-c998a41431f6}
[Week1] from_http
好像所有新生赛都有的玩意
OK啊,直接改user-agent
照做就好?welcome=to
the=?CTF
比0xGame的好玩
一步步跟着做就好啦,直接得到flag
flag{843d5687-0cfc-47b0-b481-30fcadaed18d}
[Week1] Gitttttttt
说是在有.git文件
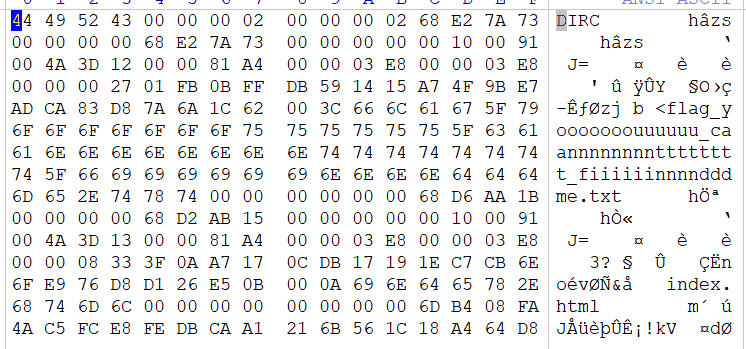
其实也就是git泄露的题目,我们加上/.git/index看看,.git/index 文件是暂存区,记录了哪些文件被添加到了暂存区以及它们的状态。如果该文件被泄露,攻击者可以通过分析索引文件来了解哪些文件可能包含敏感信息,以及它们的版本状态。
发现有个txt,我们复制粘贴/flag_yooooooouuuuuu_caannnnnnnntttttttt_fiiiiiinnnndddme.txt
flag{oH_I_NEzv0R_lEV3O_7lE_G&IT_ABgAZN}
[Week1] 包含不明东西的食物?!
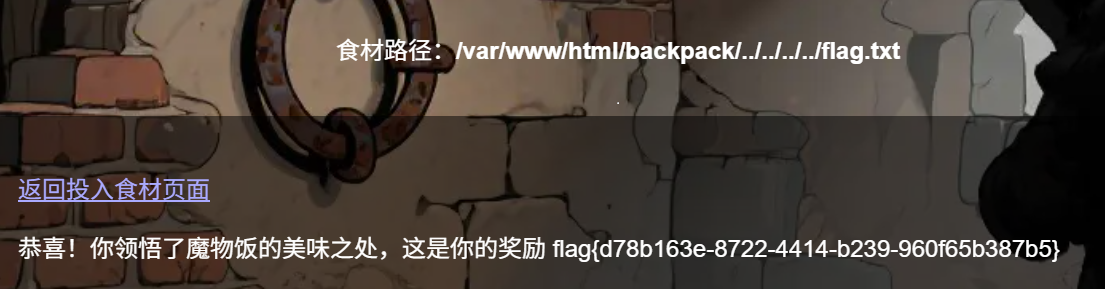
投入锅里?看上去像文件上传漏洞,打开看看
啊好像不是,不能上传
只能写路径然后看文件
这边源代码有提示
那一共我们在/var/www/html/backpack/路径,一般都会放在根目录,那我们要写四个../回退
OK成功得到
flag{d78b163e-8722-4414-b239-960f65b387b5}
[Week1] secret of php
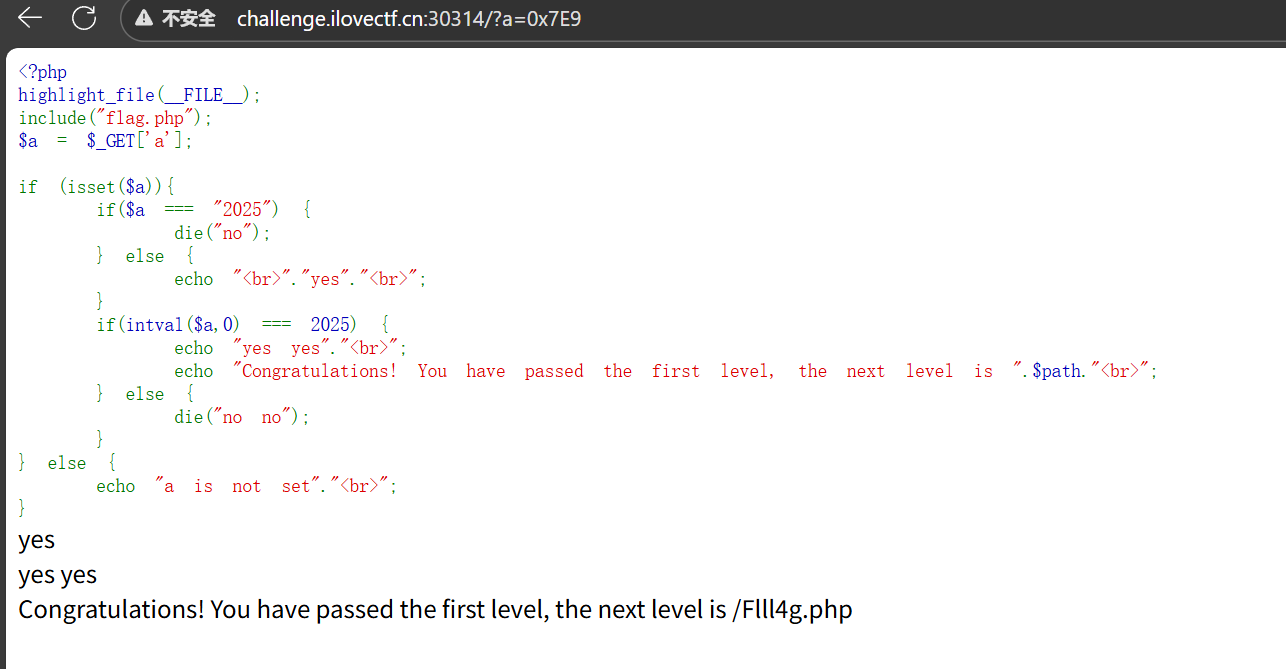
很简单的php题,只是要严格不等于2025,但是intval($a, 0)之后为2025,那直接十六进制即可
a=0x7E9
噢原来有好几题吗
三部分
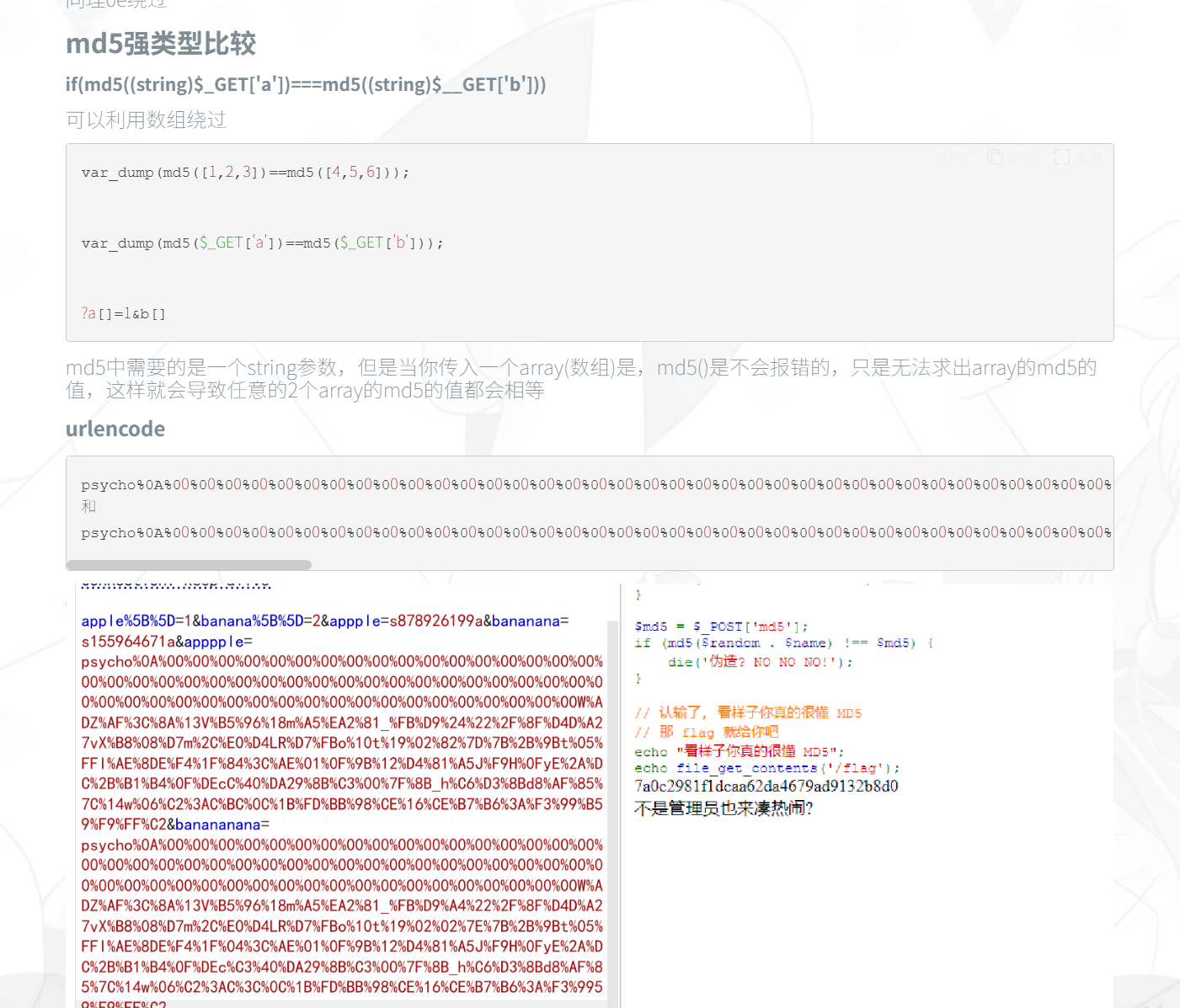
第一部分是经典md5,直接0e绕过,a=QNKCDZO&b=240610708,他们的md5都是0e开头,会被认为都是0
第二部分是值不一样,但是类型和md5值都一样,直接数组绕过aa[]=1&bb[]=2
第三部分要求更高了(string)$a !== (string)$b,但MD5哈希严格相等,我们使用URL编码后的字符串
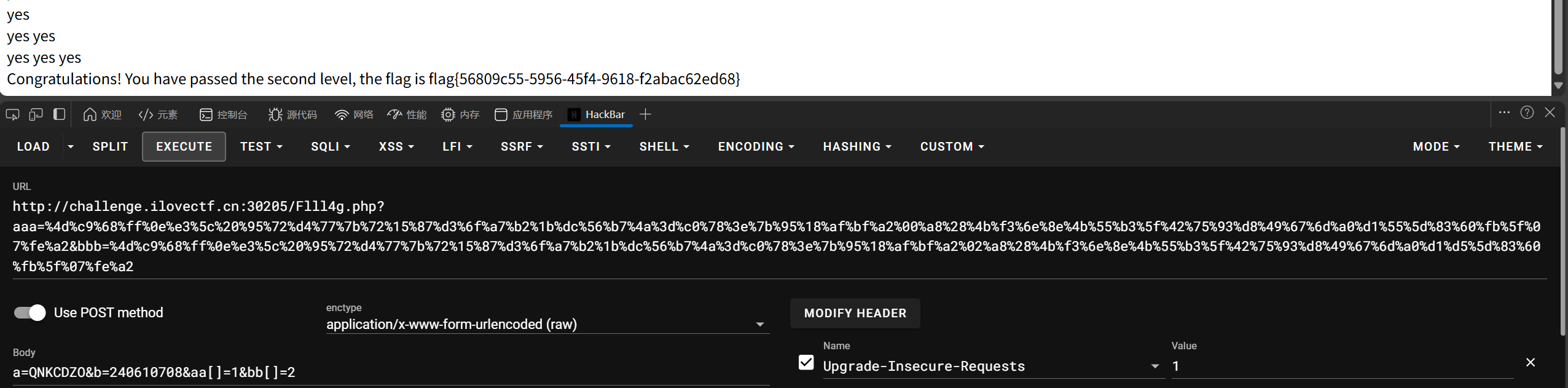
这边上下都可以
1 aaa = %4d%c9%68%ff%0e%e3%5c%20%95%72%d4%77%7b%72%15%87%d3%6f%a7%b2%1b%dc%56%b7%4a%3d%c0%78%3e%7b%95%18%af%bf%a2%00%a8%28%4b%f3%6e%8e%4b%55%b3%5f%42%75%93%d8%49%67%6d%a0%d1%55%5d%83%60%fb%5f%07%fe%a2&bbb = %4d%c9%68%ff%0e%e3%5c%20%95%72%d4%77%7b%72%15%87%d3%6f%a7%b2%1b%dc%56%b7%4a%3d%c0%78%3e%7b%95%18%af%bf%a2%02%a8%28%4b%f3%6e%8e%4b%55%b3%5f%42%75%93%d8%49%67%6d%a0%d1%d5%5d%83%60%fb%5f%07%fe%a2
可能是POST太长了传不过去,只需要把最后的改为GET传输即可
这边可以看到最后的flag
flag{56809c55-5956-45f4-9618-f2abac62ed68}
Crypto [Week1] Basic Number theory
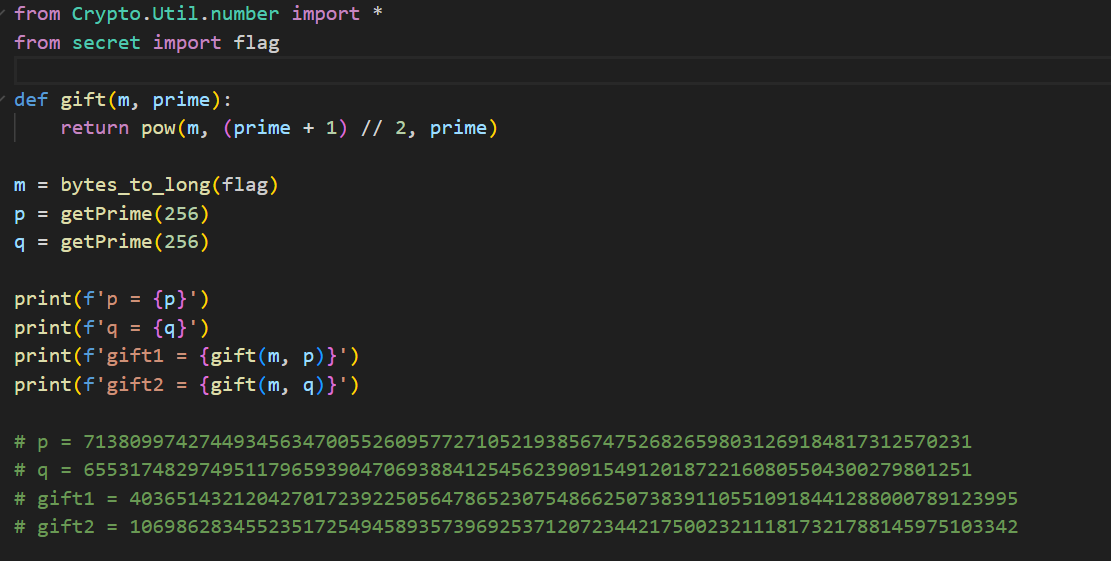
是一个基于中国剩余定理CRT的题目
所以gift1可能是m mod p或者是-m mod p
所以我们最后可以解CRT式子
只需要遍历四种情况,然后和m的值进行比较,选出其中最合适的转化为字节即可
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 from Crypto.Util.number import long_to_bytes
情况 4 成功: b‘flag{Th3_c0rner5t0ne_0f_C2ypt0gr@phy}’
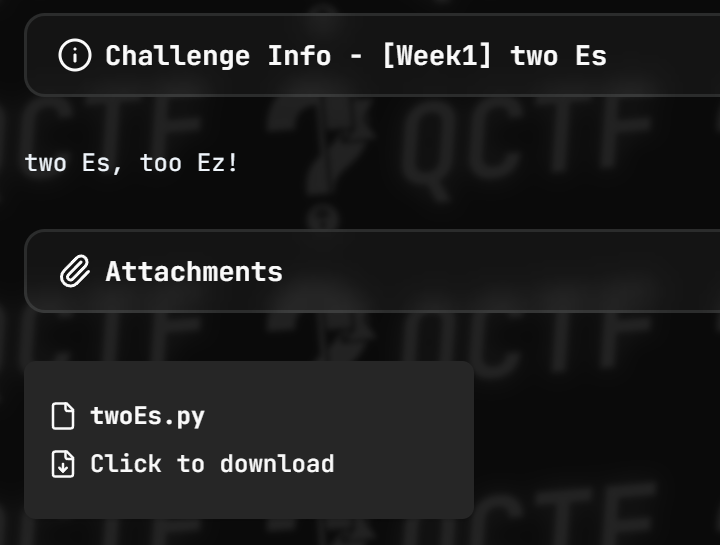
[Week1] two Es
这边依旧打开
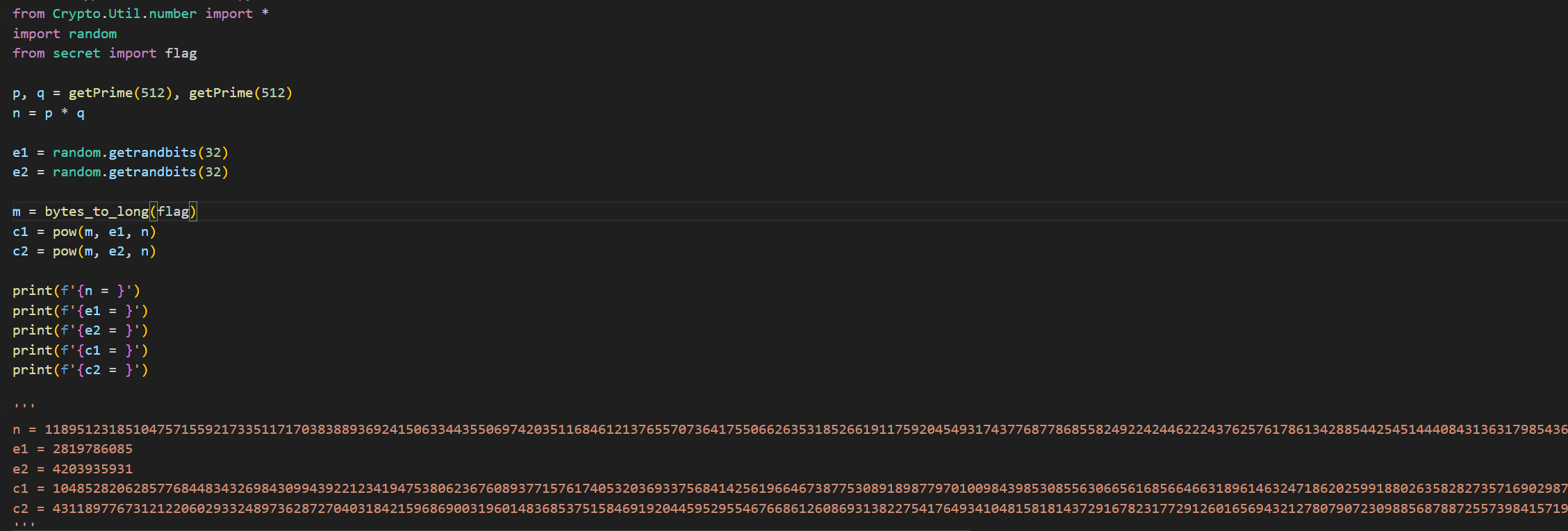
可以大概看见这些内容,是一道RSA的共模攻击
想象一下,您用同一把锁(模数 n)但不同的钥匙齿纹(加密指数 e1和 e2)给同一个箱子(明文 m)上锁,得到了两把不同的锁具(密文 c1和 c2)。共模攻击就像是一位锁匠,他不需要知道锁的内部结构(私钥 d或 p, q),仅仅通过观察这两把锁具和钥匙齿纹,就能巧妙地打开箱子。
由于我们知道了n,e1,e2,c1,c2
所以可以通过扩展欧几里得算法找到整数s1和s2使得e1s1+e2 s2=1
所以现在我们有了s1和s2
由于我们知道
c1 ≡ m^e1 (mod n)
c2 ≡ m^e2 (mod n)
如果我们对密文进行如下运算:
c1^s1 · c2^s2 mod n
接下来,我们一步步推导:
c1^s1 · c2^s2 mod n
≡ (m^e1)^s1 · (m^e2)^s2 mod n(将 c1, c2用其定义替换)
≡ m^(e1·s1) · m^(e2·s2) mod n(幂的乘方法则:(a^b)^c = a^(b·c))
≡ m^(e1·s1 + e2·s2) mod n(同底数幂相乘,指数相加)
请注意,指数部分 e1·s1 + e2·s2正是我们根据贝祖定理得到的 1!
所以,上式最终简化为:
≡ m^1 mod n
≡ m
所以我们这样子就能通过共模攻击得到m了
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 from Crypto.Util.number import long_to_bytes
GCD of e1 and e2: 3
s1 = -301370735, s2 = 202144138
flag{s01v3_rO0T_bY_7he_S4mE_m0dU1u5}
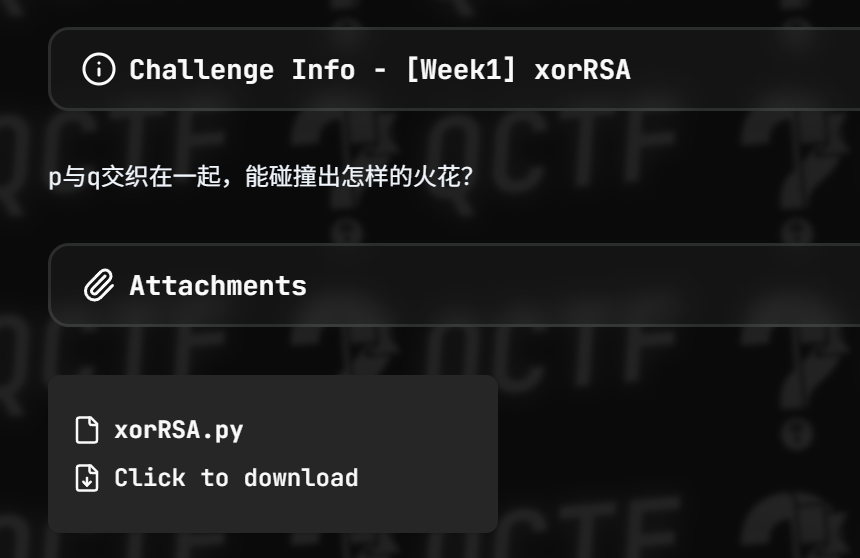
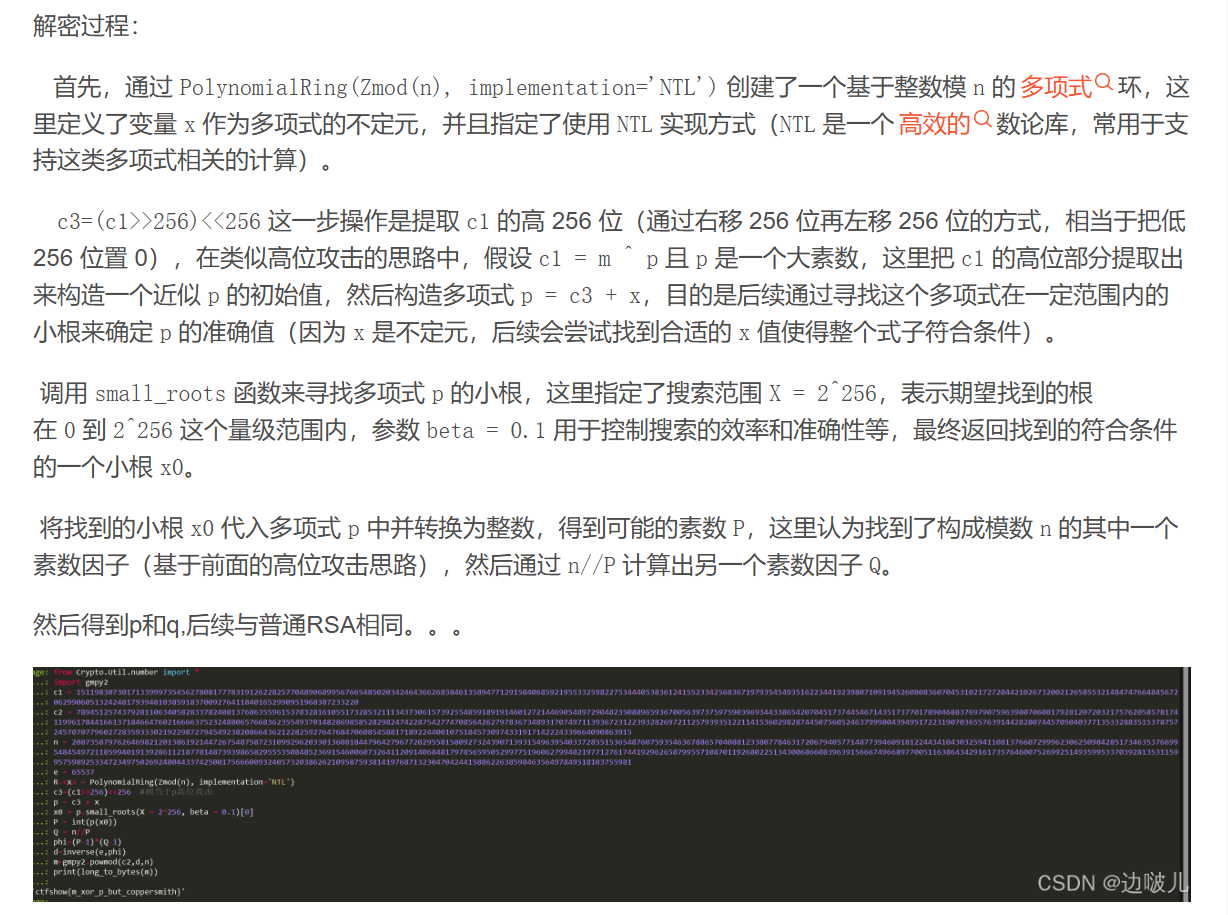
[Week1] xorRSA
叫xorRSA,看来是异或和RSA合起来了
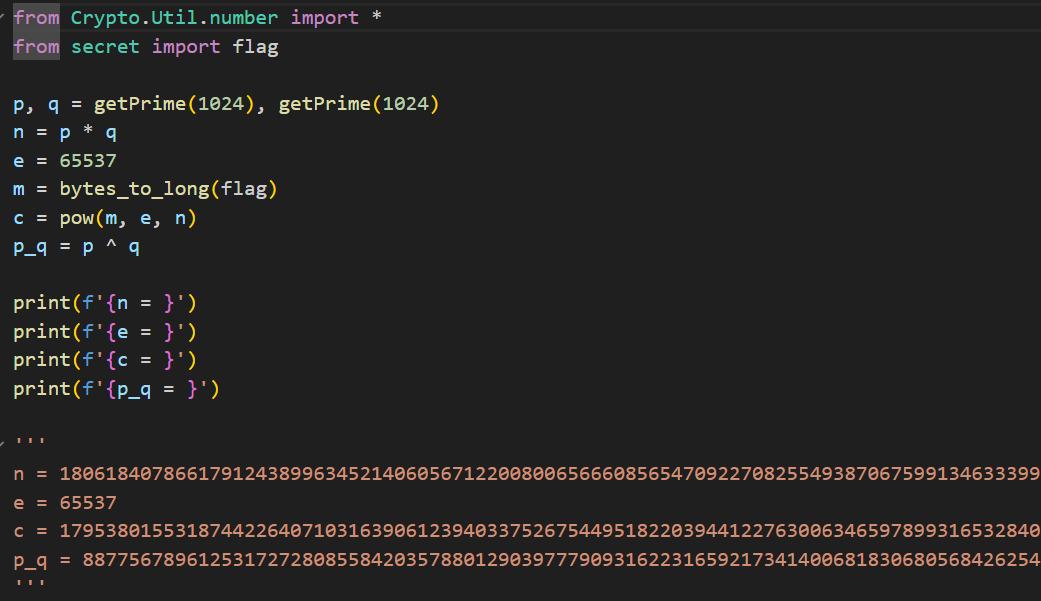
告诉了我们p*q和p^q的值
这边其实就是解方程组
由于真的很大,似乎没有那么简单,z3一直都解不出来
麻烦的很啊。。以后还是让谢晨做密码算了
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 from Cryptodome.Util.number import long_to_bytes, inverse
flag{U5e_PruN1ng_41g0rI7hm_tO_sEarch}
[Week1] beyondHex
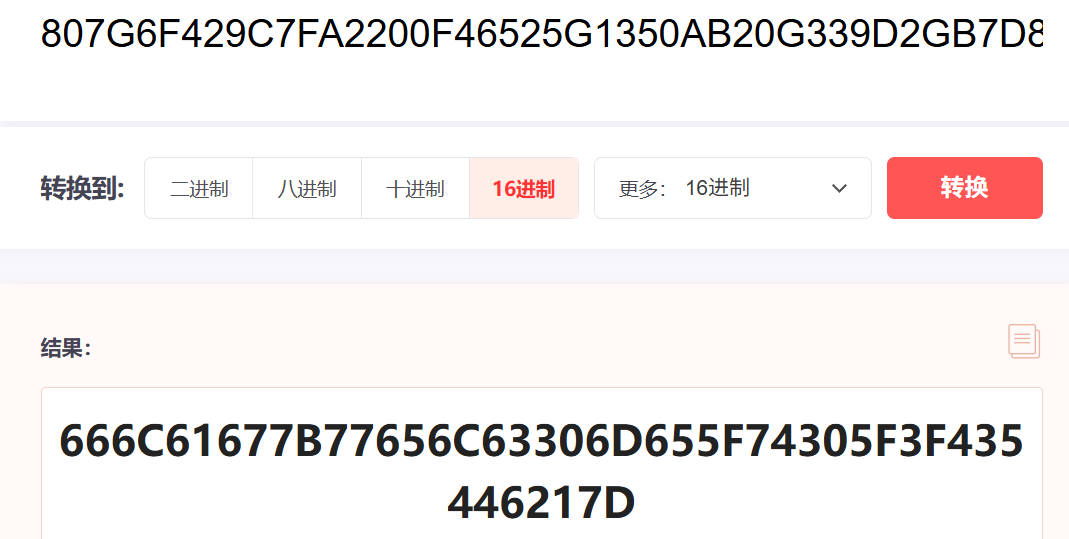
就那么点条件,说是Hex结果有个G
怀疑一下十七进制
一眼出了,这就是flag
所以这题只是个简单的十七进制转化而已
flag{welc0me_t0_?CTF!}
[Week1] Strange Machine
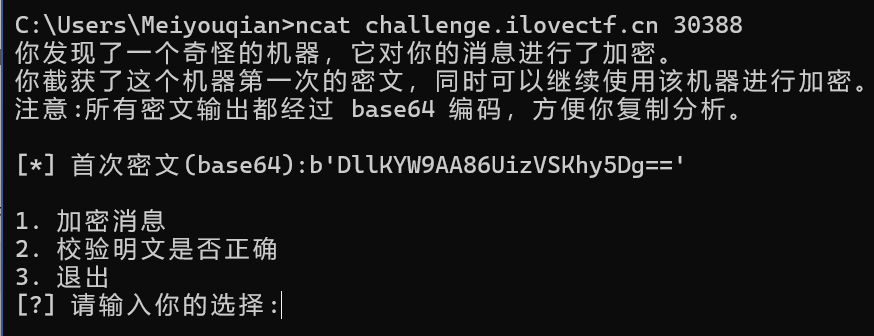
打开来需要先改为utf-8编码
然后大概就长成这样子
攻击步骤大约如上,我们试着填填看
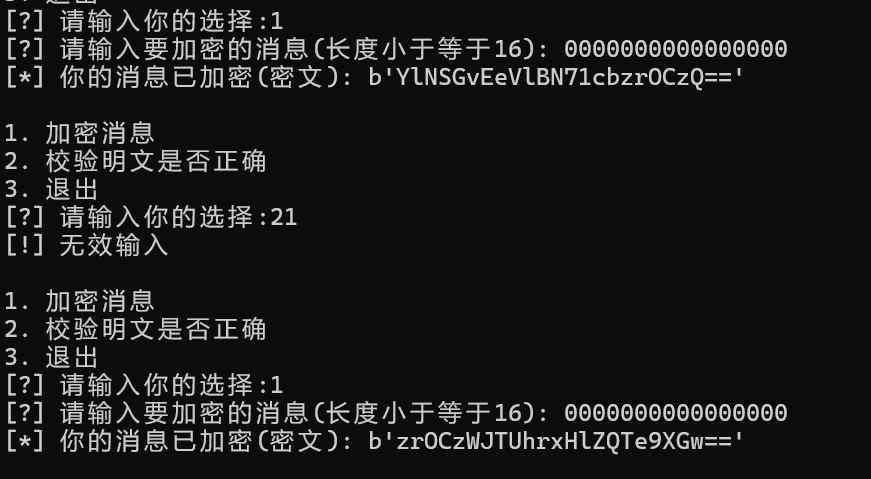
确实输入一样的都不一样了,我们尝试计算出左移的偏移量
正好是左移12位
所以是offset=12